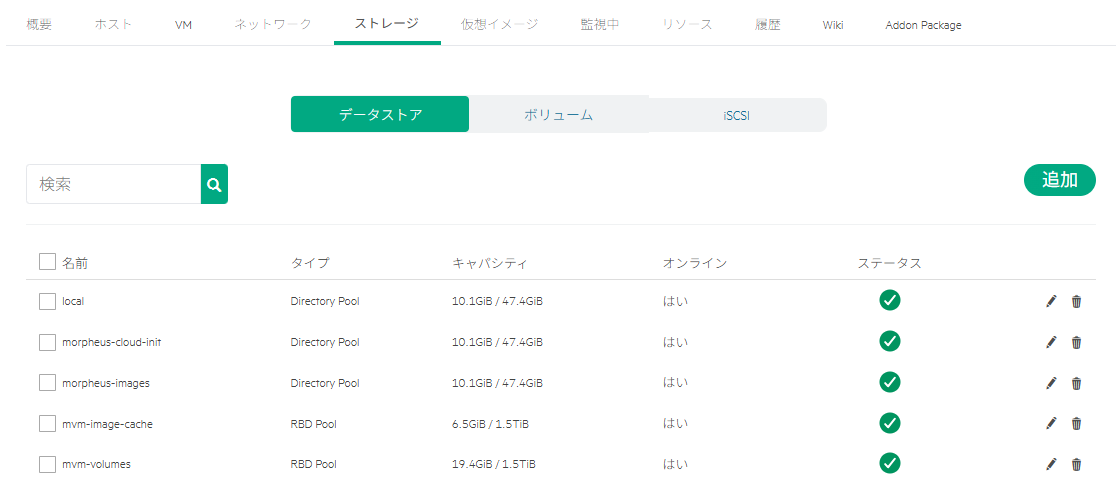
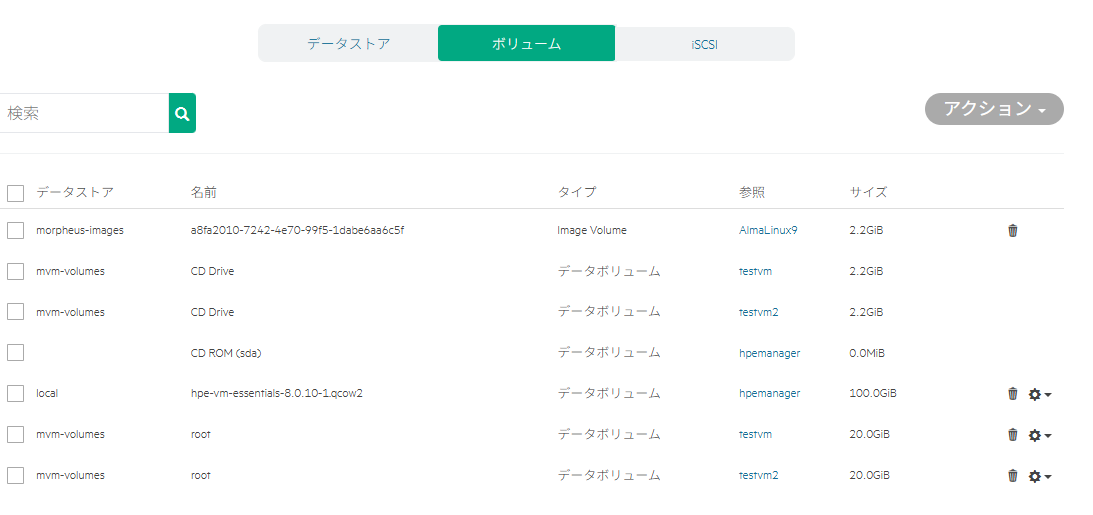
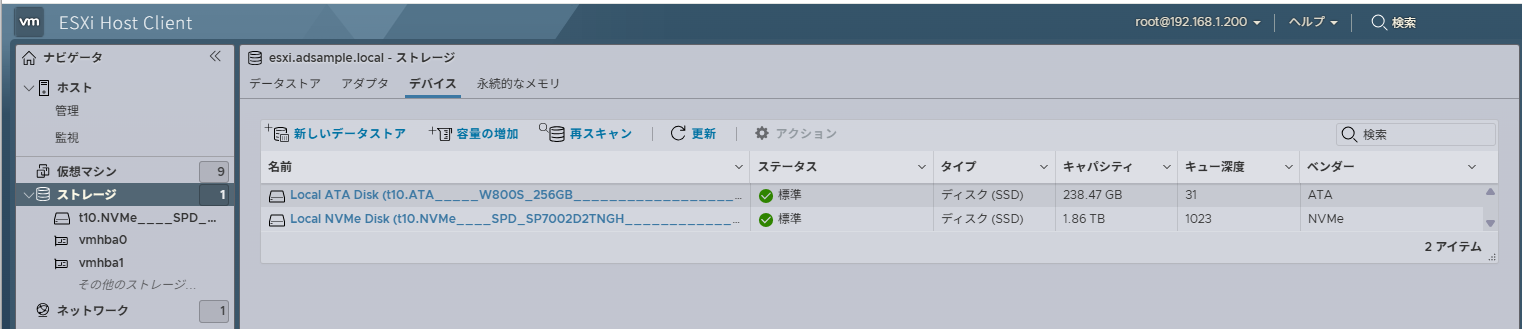
HPE VM Essentails に iSCSIストレージをつないだ場合の動作がわからない点が多かった、Web UIからではなく、CLIでいろいろ調べる羽目になったのでメモ書き
Linux汎用で使える話ではある
接続の確認
iscsiが接続できているかを「iscsiadm -m session」で確認
pcuser@hpevme6:~$ sudo iscsiadm -m session
tcp: [1] 192.168.3.34:3260,1029 iqn.1992-08.com.netapp:sn.e56cfbb6bab111f09b2a000c2980b7f5:vs.3 (non-flash)
tcp: [2] 192.168.2.34:3260,1028 iqn.1992-08.com.netapp:sn.e56cfbb6bab111f09b2a000c2980b7f5:vs.3 (non-flash)
pcuser@hpevme6:~$
何もつながっていない場合は下記
pcuser@hpevme6:~$ sudo iscsiadm -m session
iscsiadm: No active sessions.
pcuser@hpevme6:~$
詳細を確認したい場合は「-P 数字」というオプションを付ける。0,1,2,3が指定できるが「-P 0」は付けない場合と同じ
0~2は、接続先IPアドレスとログイン情報などの範囲
3になると、デバイスが認識されているかがわかるようになるので「sudo iscsiadm -m session -P 3」はトラブル時に必須
pcuser@hpevme6:~$ sudo iscsiadm -m session --print=3
iSCSI Transport Class version 2.0-870
version 2.1.9
Target: iqn.1992-08.com.netapp:sn.e56cfbb6bab111f09b2a000c2980b7f5:vs.3 (non-flash)
Current Portal: 192.168.3.34:3260,1029
Persistent Portal: 192.168.3.34:3260,1029
**********
Interface:
**********
Iface Name: default
Iface Transport: tcp
Iface Initiatorname: iqn.2024-12.com.hpe:hpevme6:59012
Iface IPaddress: 192.168.3.60
Iface HWaddress: default
Iface Netdev: default
SID: 1
iSCSI Connection State: LOGGED IN
iSCSI Session State: LOGGED_IN
Internal iscsid Session State: NO CHANGE
*********
Timeouts:
*********
Recovery Timeout: 5
Target Reset Timeout: 30
LUN Reset Timeout: 30
Abort Timeout: 15
*****
CHAP:
*****
username: <empty>
password: ********
username_in: <empty>
password_in: ********
************************
Negotiated iSCSI params:
************************
HeaderDigest: None
DataDigest: None
MaxRecvDataSegmentLength: 262144
MaxXmitDataSegmentLength: 65536
FirstBurstLength: 65536
MaxBurstLength: 1048576
ImmediateData: Yes
InitialR2T: Yes
MaxOutstandingR2T: 1
************************
Attached SCSI devices:
************************
Host Number: 33 State: running
scsi33 Channel 00 Id 0 Lun: 0
Attached scsi disk sdb State: running
scsi33 Channel 00 Id 0 Lun: 1
Attached scsi disk sdd State: running
Current Portal: 192.168.2.34:3260,1028
Persistent Portal: 192.168.2.34:3260,1028
**********
Interface:
**********
Iface Name: default
Iface Transport: tcp
Iface Initiatorname: iqn.2024-12.com.hpe:hpevme6:59012
Iface IPaddress: 192.168.2.60
Iface HWaddress: default
Iface Netdev: default
SID: 2
iSCSI Connection State: LOGGED IN
iSCSI Session State: LOGGED_IN
Internal iscsid Session State: NO CHANGE
*********
Timeouts:
*********
Recovery Timeout: 5
Target Reset Timeout: 30
LUN Reset Timeout: 30
Abort Timeout: 15
*****
CHAP:
*****
username: <empty>
password: ********
username_in: <empty>
password_in: ********
************************
Negotiated iSCSI params:
************************
HeaderDigest: None
DataDigest: None
MaxRecvDataSegmentLength: 262144
MaxXmitDataSegmentLength: 65536
FirstBurstLength: 65536
MaxBurstLength: 1048576
ImmediateData: Yes
InitialR2T: Yes
MaxOutstandingR2T: 1
************************
Attached SCSI devices:
************************
Host Number: 34 State: running
scsi34 Channel 00 Id 0 Lun: 0
Attached scsi disk sdc State: running
scsi34 Channel 00 Id 0 Lun: 1
Attached scsi disk sde State: running
pcuser@hpevme6:~$
“Attached SCSI devices:” のあとに scsi~ という表記があるかどうか
ない場合は、iSCSIストレージ側で、アクセス許可されてない可能性があるので、設定を確認
まず、Linux側のInitiatorNameを確認。Linuxの場合 /etc/iscsi/initiatorname.iscsi に記載されいて、OSインストール直後などは「InitiatorName=iqn.2004-10.com.ubuntu:01:<ランダム>」といった値で設定されていることが多い
HPE VMEの場合、hpe-vmセットアップ直後は ubuntuランダムなのだが、Web UIからiSCSI接続をするとホスト名 ランダムといった下記のような設定に切り替わる
pcuser@hpevme6:~$ sudo cat /etc/iscsi/initiatorname.iscsi
## DO NOT EDIT OR REMOVE THIS FILE!
## If you remove this file, the iSCSI daemon will not start.
## If you change the InitiatorName, existing access control lists
## may reject this initiator. The InitiatorName must be unique
## for each iSCSI initiator. Do NOT duplicate iSCSI InitiatorNames.
InitiatorName=iqn.2024-12.com.hpe:hpevme6:59012
pcuser@hpevme6:~$
この「InitiatorName」の値をiSCSIストレージ側の「イニシエータ」の登録に追加する必要がある
NetAppの場合の設定例
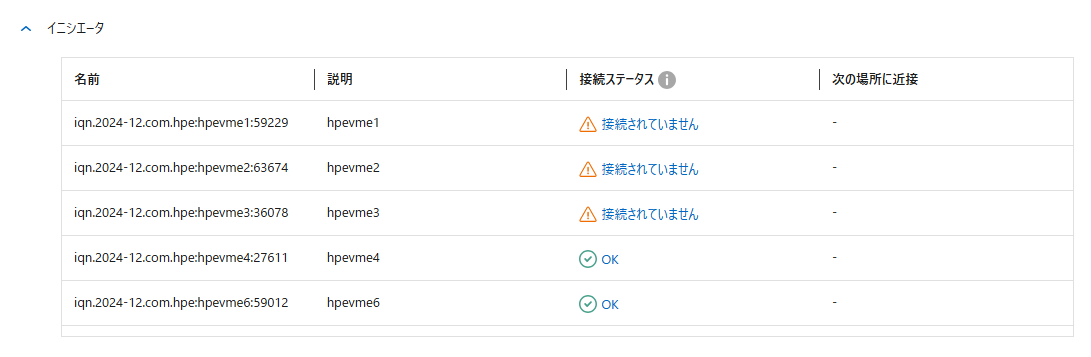
HPE VMEの場合、iSCSI設定を行う際に、Manager仮想マシンが各サーバの /etc/iscsi/initiatorname.iscsi の値を書き換えるので、設定したはずなのにつながらない場合は、最新の名前がiSCSIストレージ側に登録されているかを確認すること
設定変更した後、「sudo iscsiadm -m session –rescan」を実行して再スキャンを行う
認識していない状態から–rescanを実行して認識した、という実行ログ
pcuser@hpevme6:~$ sudo iscsiadm -m session -P 3
iSCSI Transport Class version 2.0-870
version 2.1.9
Target: iqn.1992-08.com.netapp:sn.e56cfbb6bab111f09b2a000c2980b7f5:vs.3 (non-flash)
Current Portal: 192.168.3.34:3260,1029
Persistent Portal: 192.168.3.34:3260,1029
**********
Interface:
**********
Iface Name: default
Iface Transport: tcp
Iface Initiatorname: iqn.2024-12.com.hpe:hpevme6:59012
Iface IPaddress: 192.168.3.60
Iface HWaddress: default
Iface Netdev: default
SID: 1
iSCSI Connection State: LOGGED IN
iSCSI Session State: LOGGED_IN
Internal iscsid Session State: NO CHANGE
*********
Timeouts:
*********
Recovery Timeout: 120
Target Reset Timeout: 30
LUN Reset Timeout: 30
Abort Timeout: 15
*****
CHAP:
*****
username: <empty>
password: ********
username_in: <empty>
password_in: ********
************************
Negotiated iSCSI params:
************************
HeaderDigest: None
DataDigest: None
MaxRecvDataSegmentLength: 262144
MaxXmitDataSegmentLength: 65536
FirstBurstLength: 65536
MaxBurstLength: 1048576
ImmediateData: Yes
InitialR2T: Yes
MaxOutstandingR2T: 1
************************
Attached SCSI devices:
************************
Host Number: 33 State: running
Current Portal: 192.168.2.34:3260,1028
Persistent Portal: 192.168.2.34:3260,1028
**********
Interface:
**********
Iface Name: default
Iface Transport: tcp
Iface Initiatorname: iqn.2024-12.com.hpe:hpevme6:59012
Iface IPaddress: 192.168.2.60
Iface HWaddress: default
Iface Netdev: default
SID: 2
iSCSI Connection State: LOGGED IN
iSCSI Session State: LOGGED_IN
Internal iscsid Session State: NO CHANGE
*********
Timeouts:
*********
Recovery Timeout: 120
Target Reset Timeout: 30
LUN Reset Timeout: 30
Abort Timeout: 15
*****
CHAP:
*****
username: <empty>
password: ********
username_in: <empty>
password_in: ********
************************
Negotiated iSCSI params:
************************
HeaderDigest: None
DataDigest: None
MaxRecvDataSegmentLength: 262144
MaxXmitDataSegmentLength: 65536
FirstBurstLength: 65536
MaxBurstLength: 1048576
ImmediateData: Yes
InitialR2T: Yes
MaxOutstandingR2T: 1
************************
Attached SCSI devices:
************************
Host Number: 34 State: running
pcuser@hpevme6:~$ sudo iscsiadm -m session --rescan
Rescanning session [sid: 1, target: iqn.1992-08.com.netapp:sn.e56cfbb6bab111f09b2a000c2980b7f5:vs.3, portal: 192.168.3.34,3260]
Rescanning session [sid: 2, target: iqn.1992-08.com.netapp:sn.e56cfbb6bab111f09b2a000c2980b7f5:vs.3, portal: 192.168.2.34,3260]
pcuser@hpevme6:~$ sudo iscsiadm -m session -P 3
iSCSI Transport Class version 2.0-870
version 2.1.9
Target: iqn.1992-08.com.netapp:sn.e56cfbb6bab111f09b2a000c2980b7f5:vs.3 (non-flash)
Current Portal: 192.168.3.34:3260,1029
Persistent Portal: 192.168.3.34:3260,1029
**********
Interface:
**********
Iface Name: default
Iface Transport: tcp
Iface Initiatorname: iqn.2024-12.com.hpe:hpevme6:59012
Iface IPaddress: 192.168.3.60
Iface HWaddress: default
Iface Netdev: default
SID: 1
iSCSI Connection State: LOGGED IN
iSCSI Session State: LOGGED_IN
Internal iscsid Session State: NO CHANGE
*********
Timeouts:
*********
Recovery Timeout: 5
Target Reset Timeout: 30
LUN Reset Timeout: 30
Abort Timeout: 15
*****
CHAP:
*****
username: <empty>
password: ********
username_in: <empty>
password_in: ********
************************
Negotiated iSCSI params:
************************
HeaderDigest: None
DataDigest: None
MaxRecvDataSegmentLength: 262144
MaxXmitDataSegmentLength: 65536
FirstBurstLength: 65536
MaxBurstLength: 1048576
ImmediateData: Yes
InitialR2T: Yes
MaxOutstandingR2T: 1
************************
Attached SCSI devices:
************************
Host Number: 33 State: running
scsi33 Channel 00 Id 0 Lun: 0
Attached scsi disk sdb State: running
scsi33 Channel 00 Id 0 Lun: 1
Attached scsi disk sdd State: running
Current Portal: 192.168.2.34:3260,1028
Persistent Portal: 192.168.2.34:3260,1028
**********
Interface:
**********
Iface Name: default
Iface Transport: tcp
Iface Initiatorname: iqn.2024-12.com.hpe:hpevme6:59012
Iface IPaddress: 192.168.2.60
Iface HWaddress: default
Iface Netdev: default
SID: 2
iSCSI Connection State: LOGGED IN
iSCSI Session State: LOGGED_IN
Internal iscsid Session State: NO CHANGE
*********
Timeouts:
*********
Recovery Timeout: 5
Target Reset Timeout: 30
LUN Reset Timeout: 30
Abort Timeout: 15
*****
CHAP:
*****
username: <empty>
password: ********
username_in: <empty>
password_in: ********
************************
Negotiated iSCSI params:
************************
HeaderDigest: None
DataDigest: None
MaxRecvDataSegmentLength: 262144
MaxXmitDataSegmentLength: 65536
FirstBurstLength: 65536
MaxBurstLength: 1048576
ImmediateData: Yes
InitialR2T: Yes
MaxOutstandingR2T: 1
************************
Attached SCSI devices:
************************
Host Number: 34 State: running
scsi34 Channel 00 Id 0 Lun: 0
Attached scsi disk sdc State: running
scsi34 Channel 00 Id 0 Lun: 1
Attached scsi disk sde State: running
pcuser@hpevme6:~$
マルチパスの認識
iSCSIストレージは複数のセッション=マルチパスで接続されるので、下の例では、scsi33とscsi34 の2つで見えている
pcuser@hpevme6:~$ sudo iscsiadm -m session -P 3
iSCSI Transport Class version 2.0-870
version 2.1.9
Target: iqn.1992-08.com.netapp:sn.e56cfbb6bab111f09b2a000c2980b7f5:vs.3 (non-flash)
Current Portal: 192.168.3.34:3260,1029
Persistent Portal: 192.168.3.34:3260,1029
**********
Interface:
**********
Iface Name: default
Iface Transport: tcp
Iface Initiatorname: iqn.2024-12.com.hpe:hpevme6:59012
Iface IPaddress: 192.168.3.60
Iface HWaddress: default
Iface Netdev: default
SID: 1
iSCSI Connection State: LOGGED IN
iSCSI Session State: LOGGED_IN
Internal iscsid Session State: NO CHANGE
*********
Timeouts:
*********
Recovery Timeout: 5
Target Reset Timeout: 30
LUN Reset Timeout: 30
Abort Timeout: 15
*****
CHAP:
*****
username: <empty>
password: ********
username_in: <empty>
password_in: ********
************************
Negotiated iSCSI params:
************************
HeaderDigest: None
DataDigest: None
MaxRecvDataSegmentLength: 262144
MaxXmitDataSegmentLength: 65536
FirstBurstLength: 65536
MaxBurstLength: 1048576
ImmediateData: Yes
InitialR2T: Yes
MaxOutstandingR2T: 1
************************
Attached SCSI devices:
************************
Host Number: 33 State: running
scsi33 Channel 00 Id 0 Lun: 0
Attached scsi disk sdb State: running
scsi33 Channel 00 Id 0 Lun: 1
Attached scsi disk sdd State: running
Current Portal: 192.168.2.34:3260,1028
Persistent Portal: 192.168.2.34:3260,1028
**********
Interface:
**********
Iface Name: default
Iface Transport: tcp
Iface Initiatorname: iqn.2024-12.com.hpe:hpevme6:59012
Iface IPaddress: 192.168.2.60
Iface HWaddress: default
Iface Netdev: default
SID: 2
iSCSI Connection State: LOGGED IN
iSCSI Session State: LOGGED_IN
Internal iscsid Session State: NO CHANGE
*********
Timeouts:
*********
Recovery Timeout: 5
Target Reset Timeout: 30
LUN Reset Timeout: 30
Abort Timeout: 15
*****
CHAP:
*****
username: <empty>
password: ********
username_in: <empty>
password_in: ********
************************
Negotiated iSCSI params:
************************
HeaderDigest: None
DataDigest: None
MaxRecvDataSegmentLength: 262144
MaxXmitDataSegmentLength: 65536
FirstBurstLength: 65536
MaxBurstLength: 1048576
ImmediateData: Yes
InitialR2T: Yes
MaxOutstandingR2T: 1
************************
Attached SCSI devices:
************************
Host Number: 34 State: running
scsi34 Channel 00 Id 0 Lun: 0
Attached scsi disk sdc State: running
scsi34 Channel 00 Id 0 Lun: 1
Attached scsi disk sde State: running
pcuser@hpevme6:~$
2パスで見えているものを1つにまとめるのが multipathd の役割
「sudo multipath -ll」を実行して認識状況を確認
pcuser@hpevme6:~$ sudo multipath -ll
3600a09807770457a795d5a4159416c34 dm-2 NETAPP,LUN C-Mode
size=70G features='3 queue_if_no_path pg_init_retries 50' hwhandler='1 alua' wp=rw
`-+- policy='service-time 0' prio=50 status=active
|- 34:0:0:0 sdc 8:32 active ready running
`- 33:0:0:0 sdb 8:16 active ready running
3600a09807770457a795d5a4159416c35 dm-1 NETAPP,LUN C-Mode
size=5.0G features='3 queue_if_no_path pg_init_retries 50' hwhandler='1 alua' wp=rw
`-+- policy='service-time 0' prio=50 status=active
|- 33:0:0:1 sdd 8:48 active ready running
`- 34:0:0:1 sde 8:64 active ready running
pcuser@hpevme6:~$
multipathdでまとめられたデバイスは /dev/mapper の下にデバイスファイルがある
pcuser@hpevme6:~$ ls /dev/mapper/*
/dev/mapper/3600a09807770457a795d5a4159416c34 /dev/mapper/control
/dev/mapper/3600a09807770457a795d5a4159416c35 /dev/mapper/ubuntu--vg-ubuntu--lv
pcuser@hpevme6:~$
「sudo multipath -ll」で何も表示されていない場合は、手動でデバイスを登録する
まず、認識している /dev/sd? に対応するWWIDを調べるため「/lib/udev/scsi_id -g -u -d /dev/sd?」を実行する
/lib/udev/scsi_id -g -u -d /dev/sdX
このWWIDをmutlipathに登録するため「multipath -a WWID」を実行する
multipath -a WWID
登録した後は「multipath -r」で再読み込みして、「multipath -ll」で追加されたかを確認する
ターゲットログインなどの初期設定
「iscsiadm -m discovery -t sendtargets -p IPアドレス」で接続
接続パラメータの変更
現在のパラメータ確認は「sudo iscsiadm -m node」でポータル名を確認
pcuser@hpevme6:~$ sudo iscsiadm -m node
192.168.2.34:3260,1028 iqn.1992-08.com.netapp:sn.e56cfbb6bab111f09b2a000c2980b7f5:vs.3
192.168.3.34:3260,1029 iqn.1992-08.com.netapp:sn.e56cfbb6bab111f09b2a000c2980b7f5:vs.3
pcuser@hpevme6:~$
各ポータルに設定されているパラメータを「sudo iscsiadm -m node -p <ポータル名>」で確認
pcuser@hpevme6:~$ sudo iscsiadm -m node -p 192.168.2.34:3260,1028
# BEGIN RECORD 2.1.9
node.name = iqn.1992-08.com.netapp:sn.e56cfbb6bab111f09b2a000c2980b7f5:vs.3
node.tpgt = 1028
node.startup = automatic
node.leading_login = No
iface.iscsi_ifacename = default
iface.net_ifacename = <empty>
iface.ipaddress = <empty>
iface.prefix_len = 0
iface.hwaddress = <empty>
iface.transport_name = tcp
iface.initiatorname = <empty>
iface.state = <empty>
iface.vlan_id = 0
iface.vlan_priority = 0
iface.vlan_state = <empty>
iface.iface_num = 0
iface.mtu = 0
iface.port = 0
iface.bootproto = <empty>
iface.subnet_mask = <empty>
iface.gateway = <empty>
iface.dhcp_alt_client_id_state = <empty>
iface.dhcp_alt_client_id = <empty>
iface.dhcp_dns = <empty>
iface.dhcp_learn_iqn = <empty>
iface.dhcp_req_vendor_id_state = <empty>
iface.dhcp_vendor_id_state = <empty>
iface.dhcp_vendor_id = <empty>
iface.dhcp_slp_da = <empty>
iface.fragmentation = <empty>
iface.gratuitous_arp = <empty>
iface.incoming_forwarding = <empty>
iface.tos_state = <empty>
iface.tos = 0
iface.ttl = 0
iface.delayed_ack = <empty>
iface.tcp_nagle = <empty>
iface.tcp_wsf_state = <empty>
iface.tcp_wsf = 0
iface.tcp_timer_scale = 0
iface.tcp_timestamp = <empty>
iface.redirect = <empty>
iface.def_task_mgmt_timeout = 0
iface.header_digest = <empty>
iface.data_digest = <empty>
iface.immediate_data = <empty>
iface.initial_r2t = <empty>
iface.data_seq_inorder = <empty>
iface.data_pdu_inorder = <empty>
iface.erl = 0
iface.max_receive_data_len = 0
iface.first_burst_len = 0
iface.max_outstanding_r2t = 0
iface.max_burst_len = 0
iface.chap_auth = <empty>
iface.bidi_chap = <empty>
iface.strict_login_compliance = <empty>
iface.discovery_auth = <empty>
iface.discovery_logout = <empty>
node.discovery_address = 192.168.2.34
node.discovery_port = 3260
node.discovery_type = send_targets
node.session.initial_cmdsn = 0
node.session.initial_login_retry_max = 8
node.session.xmit_thread_priority = 0
node.session.cmds_max = 128
node.session.queue_depth = 32
node.session.nr_sessions = 1
node.session.auth.authmethod = None
node.session.auth.username = <empty>
node.session.auth.password = <empty>
node.session.auth.username_in = <empty>
node.session.auth.password_in = <empty>
node.session.auth.chap_algs = MD5
node.session.timeo.replacement_timeout = 120
node.session.err_timeo.abort_timeout = 15
node.session.err_timeo.lu_reset_timeout = 30
node.session.err_timeo.tgt_reset_timeout = 30
node.session.err_timeo.host_reset_timeout = 60
node.session.iscsi.FastAbort = Yes
node.session.iscsi.InitialR2T = No
node.session.iscsi.ImmediateData = Yes
node.session.iscsi.FirstBurstLength = 262144
node.session.iscsi.MaxBurstLength = 16776192
node.session.iscsi.DefaultTime2Retain = 0
node.session.iscsi.DefaultTime2Wait = 2
node.session.iscsi.MaxConnections = 1
node.session.iscsi.MaxOutstandingR2T = 1
node.session.iscsi.ERL = 0
node.session.scan = auto
node.session.reopen_max = 0
node.conn[0].address = 192.168.2.34
node.conn[0].port = 3260
node.conn[0].startup = automatic
node.conn[0].tcp.window_size = 524288
node.conn[0].tcp.type_of_service = 0
node.conn[0].timeo.logout_timeout = 15
node.conn[0].timeo.login_timeout = 15
node.conn[0].timeo.auth_timeout = 45
node.conn[0].timeo.noop_out_interval = 5
node.conn[0].timeo.noop_out_timeout = 5
node.conn[0].iscsi.MaxXmitDataSegmentLength = 0
node.conn[0].iscsi.MaxRecvDataSegmentLength = 262144
node.conn[0].iscsi.HeaderDigest = None
node.conn[0].iscsi.DataDigest = None
node.conn[0].iscsi.IFMarker = No
node.conn[0].iscsi.OFMarker = No
# END RECORD
pcuser@hpevme6:~$
マルチパスで一部のセッションが切れた時の再接続にかかる時間がnode.session.timeo.replacement_timeout で設定されていれ標準は120秒となっている
これだと長いので、例えばHPEの「HPE Primera Red Hat Enterprise Linux実装ガイド」では 10秒 としている
今すぐ変更したい場合はiscsiadmを実行
pcuser@hpevme6:~$ sudo iscsiadm -m node -p 192.168.2.34:3260,1028 |grep node.session.timeo.replacem
ent_timeout
node.session.timeo.replacement_timeout = 120
pcuser@hpevme6:~$ sudo iscsiadm -m node -p 192.168.2.34:3260,1028 -o update -n node.session.timeo.replacement_timeout -v 10
pcuser@hpevme6:~$ sudo iscsiadm -m node -p 192.168.2.34:3260,1028 |grep node.session.timeo.replacement_timeout
node.session.timeo.replacement_timeout = 10
pcuser@hpevme6:~$
恒久的に変更するには /etc/iscsi/iscsid.conf にて該当する行を修正する。