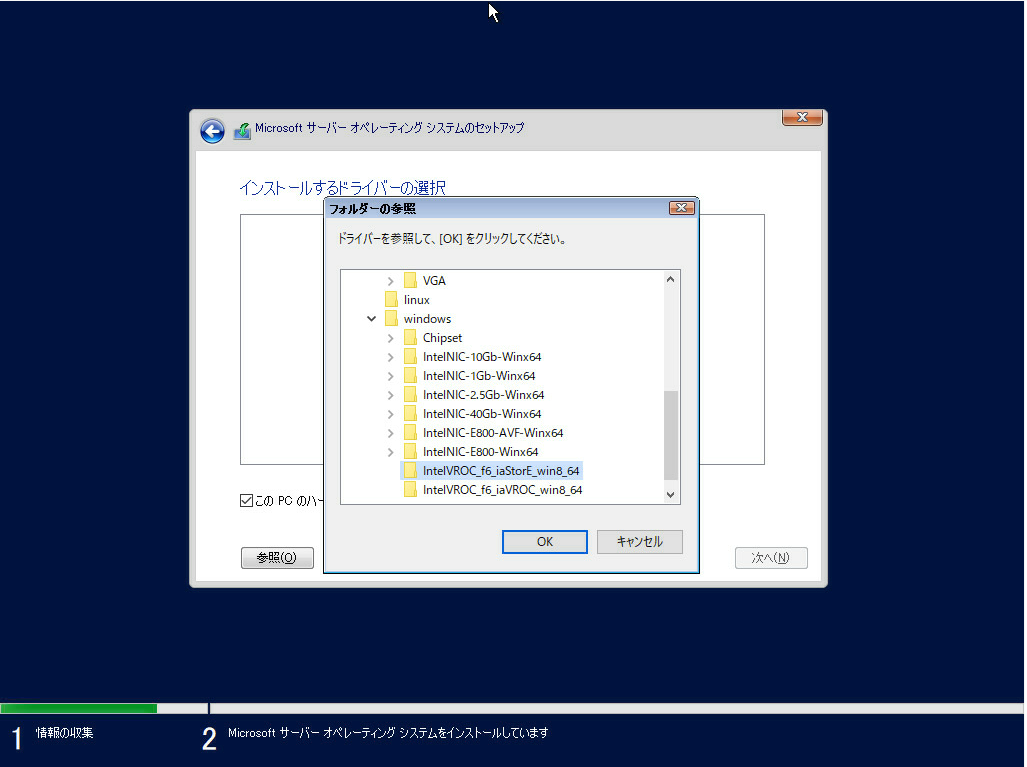
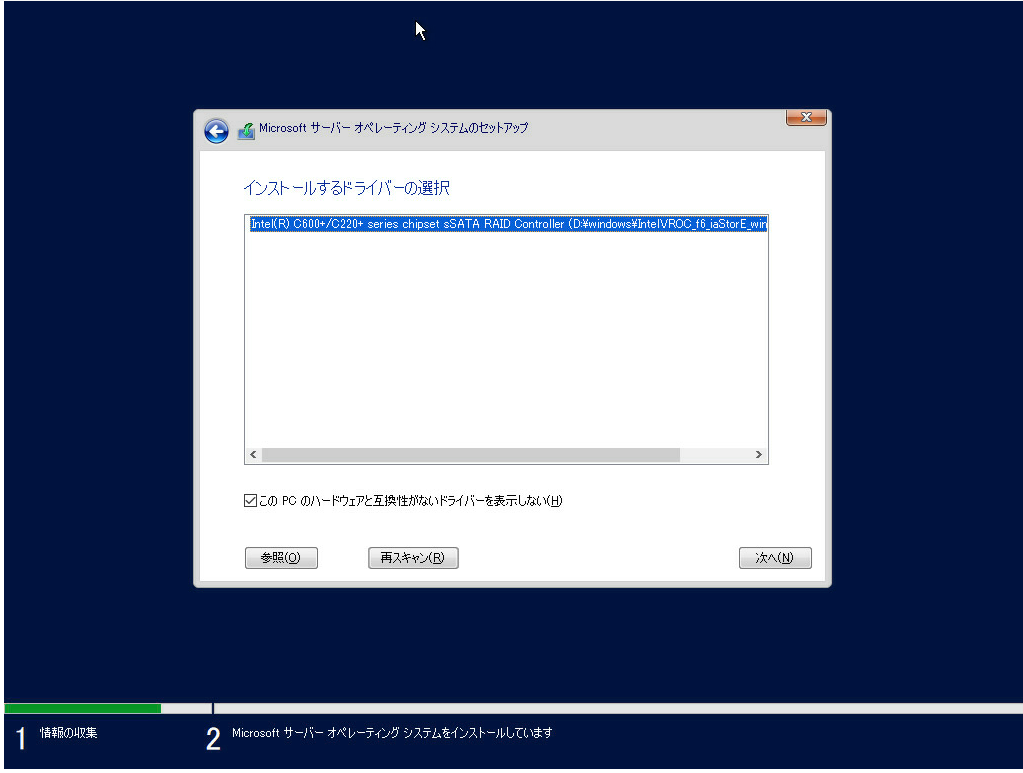
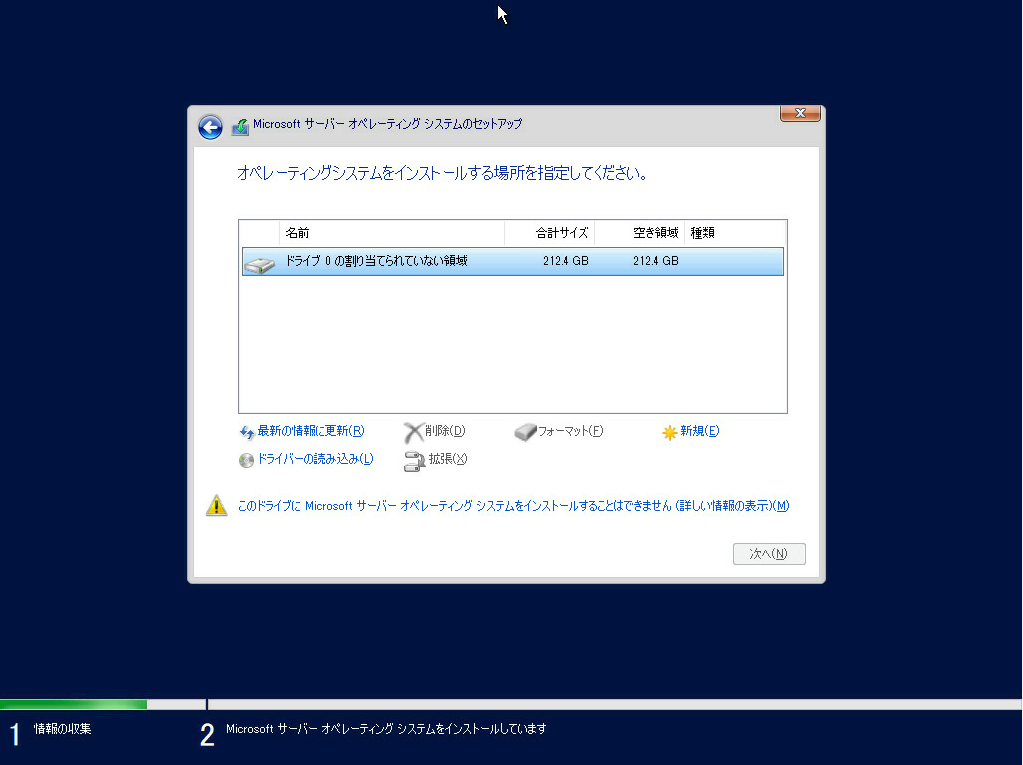
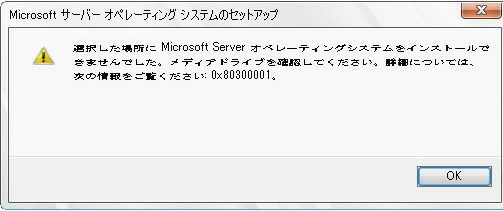
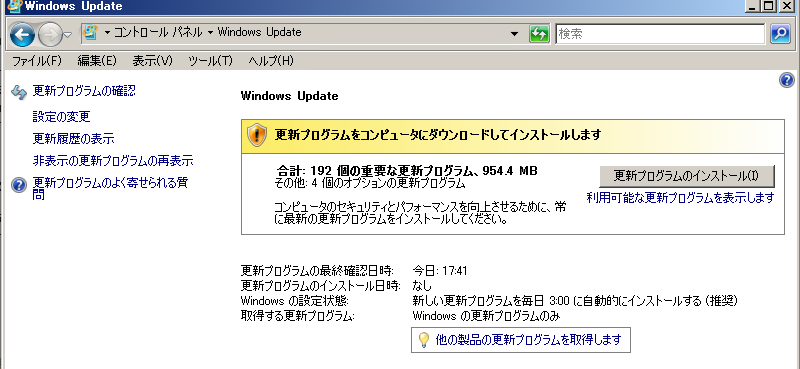
Windows Serverを移行する時に現状の設定を確認する必要がある。
その際に確認しといた方が良さそうな項目についてのメモ
1) ネットワーク設定
Active Directoryに参加するだろうからある程度はなんとかなるだろうけど・・・
DNSサーバの順序あたりは確認しておいた方がいい
「ipconfig /all」
「netsh interface ipv4 show config」
NICチーミング設定がされてるかどうか、されている場合は「チーミングモード」「負荷分散モード」と「スタンバイアダプターの設定有無」を確認
2) Windowsファイアウォール設定
これもActive Directory側から操作されてるかもしれないけど確認
「受信の規則」にある追加されたっぽい設定を確認
コマンドの場合
「netsh advfirewall show allprofiles」でプロファイル確認
「netsh advfirewall show currentprofile」で現在有効になってるプロファイル確認
「netsh advfirewall firewall show rule name=all」で設定出力
3) 共有設定
コンピュータの管理を起動して共有確認
「コンピュータの管理」の[システムツール]-[共有フォルダー]-[共有]の内容を確認
各共有のプロパティを開き、「共有のアクセス許可」と「セキュリティ」を確認
「net share」で共有一覧を表示
「net share 共有名」で各共有の詳細を確認
「Get-SmbShare」で共有一覧表示
「Get-SmbShare|Get-SmbShareAccess」で各共有のアクセス権限表示
「Get-SmbShare|Format-List」共有一覧の詳細出力
「Get-SmbShare|Get-SmbShareAccess|Format-List」アクセス権限表示の詳細出力
共有をコマンドで設定する場合
net share "share"="D:\share" /GRANT:"BUILTIN\Administrators,FULL" /GRANT:"Everyone,FULL"
4) クォータ設定
クォータ設定は2種類あるので注意が必要
ファイルサーバーリソースマネージャを起動して「クォータ」の内容を確認
対象ディレクトリと適用されている”クォータテンプレート”の内容
制限値, ハード/ソフト, 通知設定
「dirquota template list」でテンプレート一覧を表示
「dirquota template list /list-n」でテンプレートを通知設定込みで表示
「dirquota autoquota list」で自動適用クォータを確認
ドライブプロパティのクォータ設定を確認
各ドライブのプロパティを開き、クォータタブの内容を確認
「fsutil volume list」でドライブ名を確認
「fsutil quota query ドライブ名」で確認
コマンドで設定する場合
旧サーバでtemplateをexportして、新サーバでimportして、各quotaを設定
dirquota template export /file:ファイル名
dirquota template import /file:ファイル名
dirquota quota add /Path:"D:\share" /sourcetemplate:"10 GB 制限"
5) シャドウコピー設定
ドライブプロパティのシャドウコピー設定を確認
各ドライブのプロパティを開き、シャドウコピータブの内容を確認
コマンドの場合、スケジュール実行についてはタスクスケジューラで行っているのでschtasksコマンドでの確認が必要になることに注意
「vssadmin list shadows」で現在存在しているシャドウコピーを確認
「vssadmin list shadowstorage」でシャドウコピーの保存先を確認
「vssadmin list volumes」でディスクのIDを確認
「schtasks /query /xml」で一覧をXML形式で出力し、名前が"ShadowCopyVolume~"のものの内容を確認
6) タスクスケジューラ設定
タスクスケジューラを起動して設定を確認
タスクスケジューラライブラリに登録されているタスク一覧を確認
それぞれのタスクの詳細を確認
「schtasks /query /fo list」で一覧を表示
「schtasks /query /xml」で一覧をXML形式で表示
rocobopyでのファイル同期
robocopyのオプション
「/mir /copyall /R:1 /W:1」でいける場合が多い
EFSRAW対応の場合は「/COPYALL /MIR /B /EFSRAW /R:1 /W:1」
Windowsサーバ上で監査設定があって、コピー先が監査非対応の場合は「/E /B /copy:DATSO /R:1 /W:1」かなぁ?
「 /NP」オプションを付けて進捗表示なしにしてもよい
最初は「/MIR」ではなく「/B /E」で実行して、指定誤りによる誤削除がないようにする、というのも1つの手。
これは /MIR か /PURGE を指定すると、コピー元にないファイルは削除されるが、コピー先のディレクトリ指定を誤って既存データのあるディレクトリを指定してしまうと削除されるため。
robocopyを実行するバッチファイルの作成例(注: 0時~9時に実行するとLOGDATEが期待通りに動作しないかもしれないので注意。その場合はおそらく2行目の「%TIME: =0%」の”:”と”=”の間にあるスペースが抜けてるので修正すること
@echo off
set TIME2=%TIME: =0%
set LOGDATE=%DATE:~0,4%%DATE:~5,2%%DATE:~8,2%-%TIME2:~0,2%%TIME2:~3,2%
robocopy \\旧FS\share \\新FS\share /mir /copyall /R:0 /W:0 /LOG+:D:\LOGS\share-%LOGDATE%.txt
代表的なrobocopyエラーコードと対処一覧
エラー 2 (0x00000002)→指定したフォルダが存在しない
エラー 5 (0x00000005)→アクセス権がない。robocopyに/Bオプションを付ける
エラー 31 (0x0000001F)→コピー先に元と同じNTFSセキュリティ設定が行えない(OS制約などの可能性)
エラー 32 (0x00000020)→ファイルがアプリケーションからロックされているのでアプリを閉じる
エラー 64 (0x00000040)→指定した共有にアクセスできない
エラー 87 (0x00000057)→指定した共有にアクセスするためのユーザ名/パスワード指定が誤っている
エラー 112(0x00000070)→コピー先容量が足らない