ある一定温度になったら5Vファンを回す、程度の制御に使うマイコンとしてなんか買うか、とaliexpress見てたら、506円で ESP32 C3 SuperMiniというのがあったので買ってみた



購入したセラーのページには詳細がなかったので、調べてみたら、「【Arduino】ESP32 C3 SuperMiniを使う」を発見
ESP32 C3 SuperMini という製品名に対して、細かなバージョン違いがあるらしい。
掲載されている写真の部品配置と比較してみたところ、今回買ったものは「ESP32 C3 Super Mini(K2)」に相当しているみたいである
で・・・Ubuntu 24.04Serverをインストールして、arduinoをインストールし、Windows上にインストールしたVcXsrvに画面を飛ばす。
Arduiono上では、ボードマネージャにESP32追加し、ESP32 C3 Dev boardを選択して、サンプルを書き込み
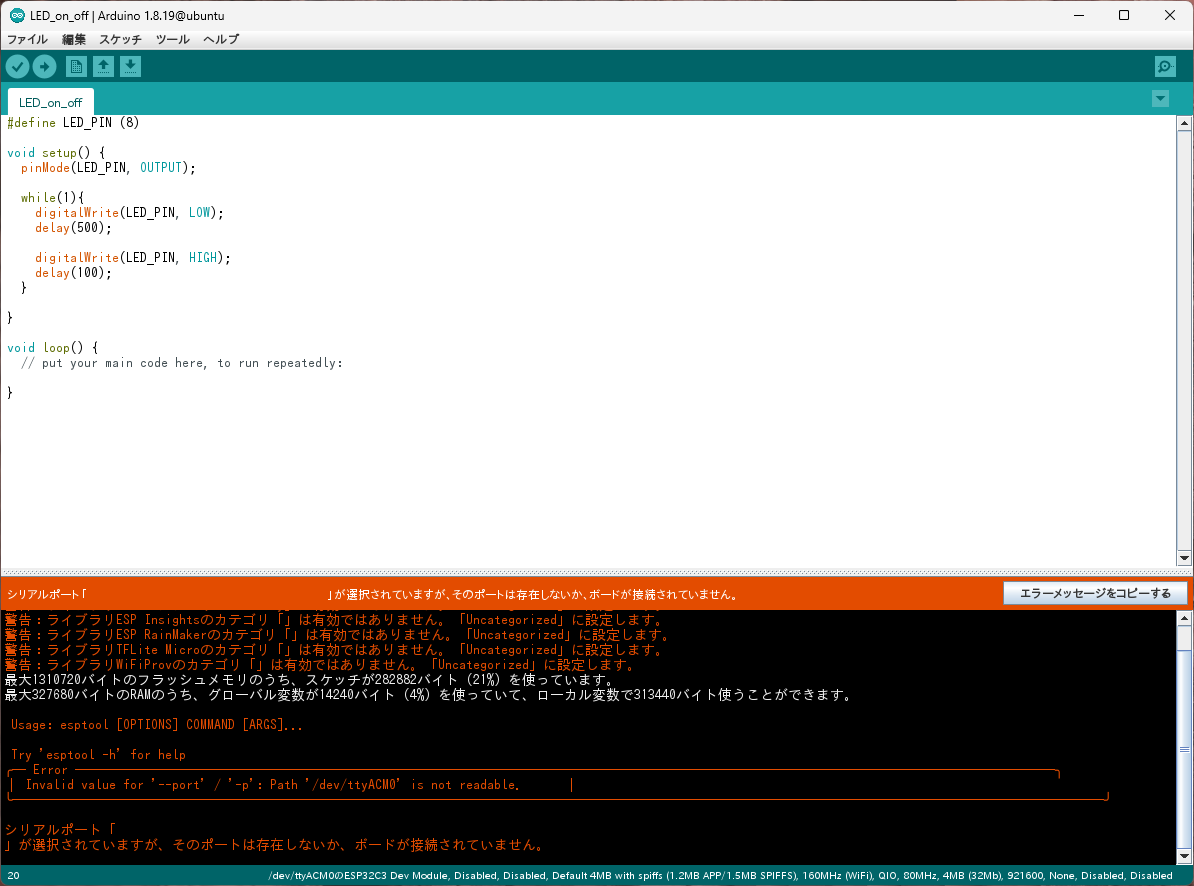
エラー発生
Arduino:1.8.19 (Linux), ボード:"ESP32C3 Dev Module, Disabled, Disabled, Default 4MB with spiffs (1.2MB APP/1.5MB SPIFFS), 160MHz (WiFi), QIO, 80MHz, 4MB (32Mb), 921600, None, Disabled, Disabled"
警告:ライブラリESP_SRのカテゴリ「Sound」は有効ではありません。「Uncategorized」に設定します。
警告:ライブラリHashのカテゴリ「Security」は有効ではありません。「Uncategorized」に設定します。
警告:ライブラリESP Insightsのカテゴリ「」は有効ではありません。「Uncategorized」に設定します。
警告:ライブラリESP RainMakerのカテゴリ「」は有効ではありません。「Uncategorized」に設定します。
警告:ライブラリTFLite Microのカテゴリ「」は有効ではありません。「Uncategorized」に設定します。
警告:ライブラリWiFiProvのカテゴリ「」は有効ではありません。「Uncategorized」に設定します。
最大1310720バイトのフラッシュメモリのうち、スケッチが282882バイト(21%)を使っています。
最大327680バイトのRAMのうち、グローバル変数が14240バイト(4%)を使っていて、ローカル変数で313440バイト使うことができます。
Usage: esptool [OPTIONS] COMMAND [ARGS]...
Try 'esptool -h' for help
╭─ Error ──────────────────────────────────────────────────────────────────────╮
│ Invalid value for '--port' / '-p': Path '/dev/ttyACM0' is not readable. │
╰──────────────────────────────────────────────────────────────────────────────╯
シリアルポート「
」が選択されていますが、そのポートは存在しないか、ボードが接続されていません。
「ファイル」メニューの「環境設定」から
「より詳細な情報を表示する:コンパイル」を有効にすると
より詳しい情報が表示されます。
確認してみる
まず、USBデバイスが存在しているかを確認
pcuser@ubuntu:~$ lsusb
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 001 Device 002: ID 0e0f:0003 VMware, Inc. Virtual Mouse
Bus 001 Device 007: ID 0e0f:0002 VMware, Inc. Virtual USB Hub
Bus 001 Device 008: ID 0e0f:0002 VMware, Inc. Virtual USB Hub
Bus 001 Device 022: ID 303a:1001 Espressif USB JTAG/serial debug unit
Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
pcuser@ubuntu:~$
ある
rootユーザでesptoolを実行したらどうなる?
root@ubuntu:~# /home/pcuser/.arduino15/packages/esp32/tools/esptool_py/5.1.0/esptool --port /dev/ttyACM0 chip-id
esptool v5.1.0
Connected to ESP32-C3 on /dev/ttyACM0:
Chip type: ESP32-C3 (QFN32) (revision v0.4)
Features: Wi-Fi, BT 5 (LE), Single Core, 160MHz, Embedded Flash 4MB (XMC)
Crystal frequency: 40MHz
USB mode: USB-Serial/JTAG
MAC: ac:eb:e6:6d:6b:b0
Stub flasher running.
Warning: ESP32-C3 has no chip ID. Reading MAC address instead.
MAC: ac:eb:e6:6d:6b:b0
Hard resetting via RTS pin...
root@ubuntu:~#
情報が取得できる
一般ユーザだとどうなる?
pcuser@ubuntu:~$ /home/pcuser/.arduino15/packages/esp32/tools/esptool_py/5.1.0/esptool --port /dev/ttyACM0 chip-id
Usage: esptool [OPTIONS] COMMAND [ARGS]...
Try 'esptool -h' for help
lq Error qqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqk
x Invalid value for '--port' / '-p': Path '/dev/ttyACM0' is not readable. x
mqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqj
pcuser@ubuntu:~$
エラーとなる
つまり・・・/dev/ttyACM0 にアクセス権がない
pcuser@ubuntu:~$ ls -l /dev/ttyACM0
crw-rw---- 1 root dialout 166, 0 4月 8 11:40 /dev/ttyACM0
pcuser@ubuntu:~$
面倒くさいので /dev/ttyACM0自体に権限を与えてしまう
pcuser@ubuntu:~$ sudo chmod a+rw /dev/ttyACM0
[sudo] pcuser のパスワード:
pcuser@ubuntu:~$ ls -l /dev/ttyACM0
crw-rw-rw- 1 root dialout 166, 0 4月 8 11:40 /dev/ttyACM0
pcuser@ubuntu:~$
変更後は一般ユーザでもesptoolの実行に成功した
pcuser@ubuntu:~$ /home/pcuser/.arduino15/packages/esp32/tools/esptool_py/5.1.0/esptool --port /dev/ttyACM0 chip-id
esptool v5.1.0
Connected to ESP32-C3 on /dev/ttyACM0:
Chip type: ESP32-C3 (QFN32) (revision v0.4)
Features: Wi-Fi, BT 5 (LE), Single Core, 160MHz, Embedded Flash 4MB (XMC)
Crystal frequency: 40MHz
USB mode: USB-Serial/JTAG
MAC: ac:eb:e6:6d:6b:b0
Stub flasher running.
Warning: ESP32-C3 has no chip ID. Reading MAC address instead.
MAC: ac:eb:e6:6d:6b:b0
Hard resetting via RTS pin...
pcuser@ubuntu:~$
ただ、これだと、1回抜き差しすると/dev/ttyACM0は再作成されるので権限が元に戻ってしまう
pcuser@ubuntu:~$ ls -l /dev/ttyACM0
crw-rw---- 1 root dialout 166, 0 4月 8 11:53 /dev/ttyACM0
pcuser@ubuntu:~$
簡単に解決する方法は、上記/dev/ttyACM0のグループ権限にある「dialout」に、一般ユーザを追加すること
pcuser@ubuntu:~$ sudo usermod -aG dialout pcuser
[sudo] pcuser のパスワード:
pcuser@ubuntu:~$
設定後、一回ログアウトする必要がある。ログアウトしないと古い権限が適用され使用できない
pcuser@ubuntu:~$ ls -l /dev/ttyACM0
crw-rw---- 1 root dialout 166, 0 4月 8 11:53 /dev/ttyACM0
pcuser@ubuntu:~$ /home/pcuser/.arduino15/packages/esp32/tools/esptool_py/5.1.0/esptool --port /dev/ttyACM0 chip-id
Usage: esptool [OPTIONS] COMMAND [ARGS]...
Try 'esptool -h' for help
lq Error qqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqk
x Invalid value for '--port' / '-p': Path '/dev/ttyACM0' is not readable. x
mqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqj
pcuser@ubuntu:~$
ログインしなおすと、使えるようになる
pcuser@ubuntu:~$ ls -l /dev/ttyACM0
crw-rw---- 1 root dialout 166, 0 4月 8 11:53 /dev/ttyACM0
pcuser@ubuntu:~$ /home/pcuser/.arduino15/packages/esp32/tools/esptool_py/5.1.0/esptool --port /dev/ttyACM0 chip-id
esptool v5.1.0
Connected to ESP32-C3 on /dev/ttyACM0:
Chip type: ESP32-C3 (QFN32) (revision v0.4)
Features: Wi-Fi, BT 5 (LE), Single Core, 160MHz, Embedded Flash 4MB (XMC)
Crystal frequency: 40MHz
USB mode: USB-Serial/JTAG
MAC: ac:eb:e6:6d:6b:b0
Stub flasher running.
Warning: ESP32-C3 has no chip ID. Reading MAC address instead.
MAC: ac:eb:e6:6d:6b:b0
Hard resetting via RTS pin...
pcuser@ubuntu:~$ id
uid=1000(pcuser) gid=1000(pcuser) groups=1000(pcuser),4(adm),20(dialout),24(cdrom),27(sudo),30(dip),46(plugdev),101(lxd)
pcuser@ubuntu:~$
シリアル出力をしない設定がある
debugのために下記の様な感じでシリアル出力を書いた
#define LED_PIN (8)
void setup() {
Serial.begin(9600);
Serial.print("start");
pinMode(LED_PIN, OUTPUT);
while(1)
{
digitalWrite(LED_PIN, LOW);
delay(500);
digitalWrite(LED_PIN, HIGH);
delay(100);
}
}
void loop() {
Serial.println("loop test");
delay(3000);
}
しかし、シリアルモニタに何も出力されない
調べると「esp32 c3系でシリアルモニタに出力されない」に「USB CDC On Boot」が「Disabled」になってると出力されない、という話があった
確認すると、Disabledであった

しかし「Enabled」に変えてから書き込みを行ってもシリアル出力はされない状態
arduiono 1.8.19 on ubuntu 24.04
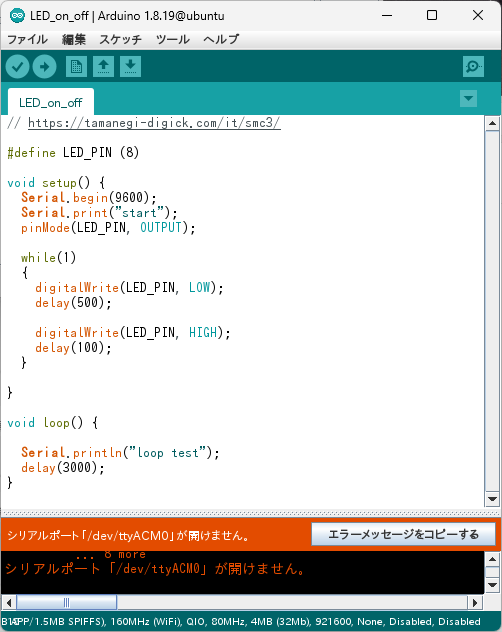
他の事例「ESP32C3 Super Mini doen’t communicate with Serial Monitor in one setup, but it does in another setup — why?」には「ESP32C3 Dev Module」ではなく「LOLIN C3 Mini」を選んで「USB CDC On Boot:Enabled」で書き込め、ということでやってみたが、ダメだった
claudeに「esp32 c3 super mini にて シリアル出力が出てこない」と聞いてみたら「USB CDC の初期化待ち(重要!)」だそうな
ということでSerial.begin(9600);の次にdelay(2000)を追加したところ、とりあえずsetup内のserial.printについては出力はされたが、loop無いのやつが出力されない…って、あ、setup内でループしてんじゃん
#define LED_PIN (8)
void setup() {
Serial.begin(9600);
delay(2000);
Serial.print("start");
pinMode(LED_PIN, OUTPUT);
//while(1)
//{
// digitalWrite(LED_PIN, LOW);
// delay(500);
// digitalWrite(LED_PIN, HIGH);
// delay(100);
//}
}
void loop() {
Serial.println("loop test");
delay(3000);
}
ということで動作を確認