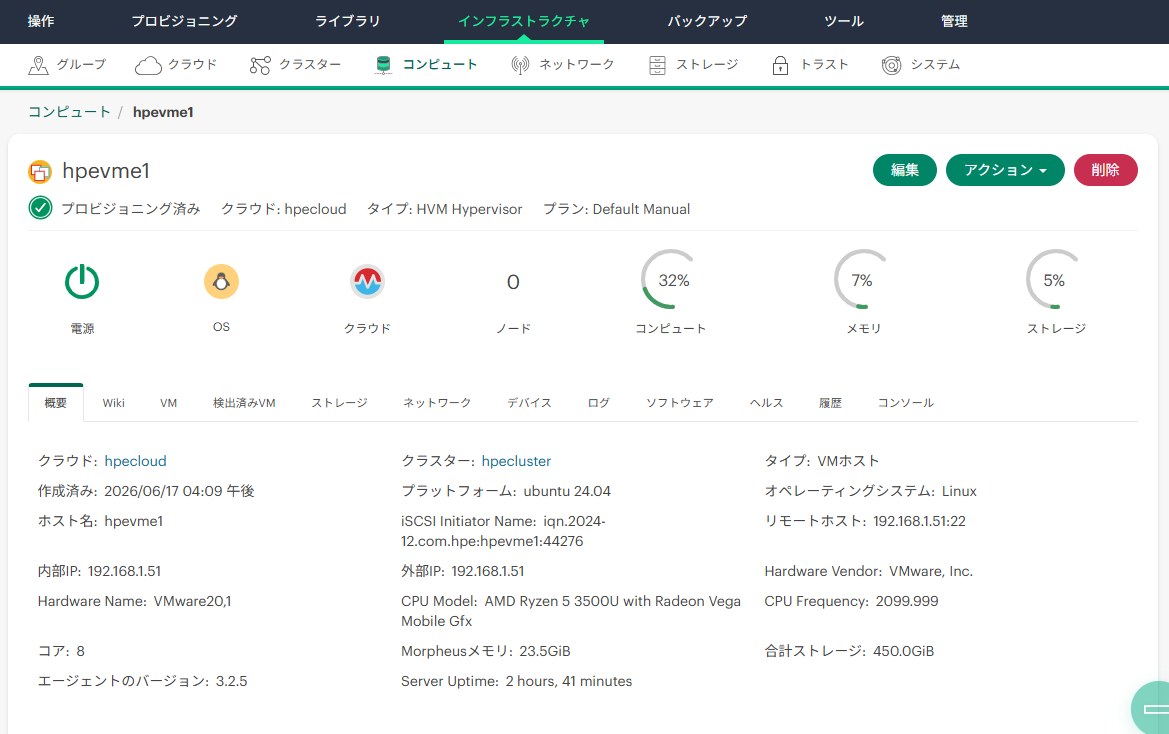
HPE VMEクラスタを作った場合、実際にクラスタ状態を制御してるのはなんなのか、というメモ
問題があった時に遭遇したものを書いてるだけなので、他にも仕組みがあるかもしれない
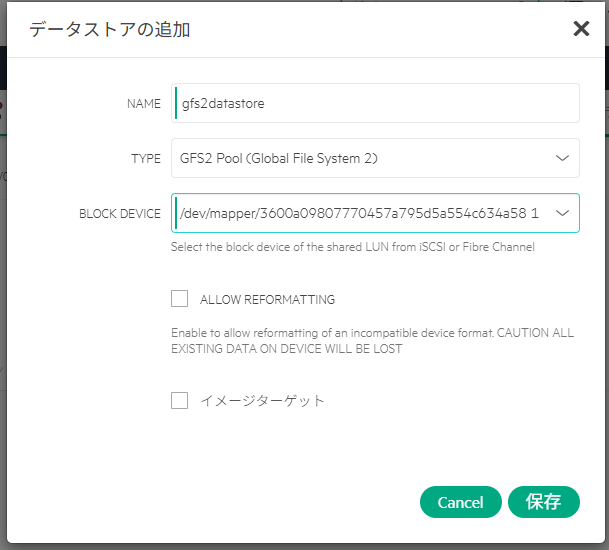
GFS2ファイルシステム周り
複数サーバでGFS2ファイルシステムを使う場合、制御に pacemaker+corosyncを利用していた。
サーバ3台構成で組んだ場合に、GFS2構築後に、停止状態から起動させると、しばらくGFS2ファイルシステムがマウントされていない状態になっている
これはpacemaker+corosyncにより所属サーバの過半数から得票がとれなければ正常に動作していないと判断され、GFS2ファイルシステムをマウントしない、ということから来ている。
GFS2ファイルシステムのマウント制御について確認する場合、まずは「sudo pcs status」コマンドを実行して、確認をする。下記は3サーバ構成で全て起動している場合のもの
pcuser@hpevme1:~$ sudo pcs status
Cluster name: 2rouf0rh0q94m4i
Cluster Summary:
* Stack: corosync (Pacemaker is running)
* Current DC: hpevme2 (version 2.1.6-6fdc9deea29) - partition with quorum
* Last updated: Wed Mar 4 10:57:03 2026 on hpevme1
* Last change: Fri Feb 27 17:56:49 2026 by root via cibadmin on hpevme3
* 3 nodes configured
* 7 resource instances configured
Node List:
* Online: [ hpevme1 hpevme2 hpevme3 ]
Full List of Resources:
* Clone Set: dlm-clone [dlm]:
* Started: [ hpevme1 hpevme2 hpevme3 ]
* hpevm_gfs2_scsi (stonith:fence_scsi_hpevm): Started hpevme1
* Clone Set: gfs2datastore_1ffa9-clone [gfs2datastore_1ffa9]:
* Started: [ hpevme1 hpevme2 hpevme3 ]
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
pcuser@hpevme1:~$
“Daemon Status”に表示されているようにcorosync, pacemakerが関連していることがわかる
「sudo pcs status –full」を実行すると詳細表示
pcuser@hpevme1:~$ sudo pcs status --full
Cluster name: 2rouf0rh0q94m4i
Cluster Summary:
* Stack: corosync (Pacemaker is running)
* Current DC: hpevme2 (2) (version 2.1.6-6fdc9deea29) - partition with quorum
* Last updated: Wed Mar 4 10:57:07 2026 on hpevme1
* Last change: Fri Feb 27 17:56:49 2026 by root via cibadmin on hpevme3
* 3 nodes configured
* 7 resource instances configured
Node List:
* Node hpevme1 (1): online, feature set 3.17.4
* Node hpevme2 (2): online, feature set 3.17.4
* Node hpevme3 (3): online, feature set 3.17.4
Full List of Resources:
* Clone Set: dlm-clone [dlm]:
* dlm (ocf:pacemaker:controld): Started hpevme2
* dlm (ocf:pacemaker:controld): Started hpevme1
* dlm (ocf:pacemaker:controld): Started hpevme3
* hpevm_gfs2_scsi (stonith:fence_scsi_hpevm): Started hpevme1
* Clone Set: gfs2datastore_1ffa9-clone [gfs2datastore_1ffa9]:
* gfs2datastore_1ffa9 (ocf:heartbeat:Filesystem): Started hpevme2
* gfs2datastore_1ffa9 (ocf:heartbeat:Filesystem): Started hpevme1
* gfs2datastore_1ffa9 (ocf:heartbeat:Filesystem): Started hpevme3
Migration Summary:
Fencing History:
* unfencing of hpevme2 successful: delegate=hpevme2, client=pacemaker-fenced.2051, origin=hpevme3, completed='2026-03-04 10:50:33.927998 +09:00'
* unfencing of hpevme1 successful: delegate=hpevme1, client=pacemaker-controld.1993, origin=hpevme2, completed='2026-03-04 10:50:33.860998 +09:00'
* unfencing of hpevme3 successful: delegate=hpevme3, client=pacemaker-controld.1993, origin=hpevme2, completed='2026-03-04 10:50:33.718998 +09:00'
Tickets:
PCSD Status:
hpevme1: Online
hpevme2: Online
hpevme3: Online
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
pcuser@hpevme1:~$
pcsコマンドの下層に、corosyncがある、という構造になっているので、corosync側のステータスを確認することもできる
過半数をどうやって調査しているか、という部分はcorosyncのquorumで行っているので、そのステータスを確認するために「sudo corosync-quorumtool -s」を実行
pcuser@hpevme1:~$ sudo corosync-quorumtool -s
Quorum information
------------------
Date: Wed Mar 4 11:04:48 2026
Quorum provider: corosync_votequorum
Nodes: 3
Node ID: 1
Ring ID: 1.3d
Quorate: Yes
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 3
Quorum: 2
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
1 1 hpevme1 (local)
2 1 hpevme2
3 1 hpevme3
pcuser@hpevme1:~$
corosyncで行う各サーバ間の通信がどのIPで行われているかは「sudo corosync-cfgtool -n」
pcuser@hpevme1:~$ sudo corosync-cfgtool -n
Local node ID 1, transport knet
nodeid: 2 reachable
LINK: 0 udp (192.168.1.51->192.168.1.52) enabled connected mtu: 1397
nodeid: 3 reachable
LINK: 0 udp (192.168.1.51->192.168.1.53) enabled connected mtu: 1397
pcuser@hpevme1:~$ sudo corosync-cfgtool -s
Local node ID 1, transport knet
LINK ID 0 udp
addr = 192.168.1.51
status:
nodeid: 1: localhost
nodeid: 2: connected
nodeid: 3: connected
pcuser@hpevme1:~$
なお、上記例では「192.168.1.0/24」のネットワークを使っているが、このIPアドレス帯はマネージメント用として各物理サーバおよびHPE VME Managerサーバに使用しているものとなる。(Webアクセスや、sshアクセスで使うもの)
corosync用のネットワークを別のサブネットに設定する、といった設定GUIはv8.0.13でもなかったような・・・
サーバ1台止めた場合のコマンド出力
「sudo pcs status」
pcuser@hpevme2:~$ sudo pcs status
[sudo] password for pcuser:
Cluster name: 2rouf0rh0q94m4i
Cluster Summary:
* Stack: corosync (Pacemaker is running)
* Current DC: hpevme2 (version 2.1.6-6fdc9deea29) - partition with quorum
* Last updated: Wed Mar 4 13:11:33 2026 on hpevme2
* Last change: Fri Feb 27 17:56:49 2026 by root via cibadmin on hpevme3
* 3 nodes configured
* 7 resource instances configured
Node List:
* Online: [ hpevme2 hpevme3 ]
* OFFLINE: [ hpevme1 ]
Full List of Resources:
* Clone Set: dlm-clone [dlm]:
* Started: [ hpevme2 hpevme3 ]
* Stopped: [ hpevme1 ]
* hpevm_gfs2_scsi (stonith:fence_scsi_hpevm): Started hpevme2
* Clone Set: gfs2datastore_1ffa9-clone [gfs2datastore_1ffa9]:
* Started: [ hpevme2 hpevme3 ]
* Stopped: [ hpevme1 ]
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
pcuser@hpevme2:~$
「sudo pcs status –full」
pcuser@hpevme2:~$ sudo pcs status --full
Cluster name: 2rouf0rh0q94m4i
Cluster Summary:
* Stack: corosync (Pacemaker is running)
* Current DC: hpevme2 (2) (version 2.1.6-6fdc9deea29) - partition with quorum
* Last updated: Wed Mar 4 13:12:26 2026 on hpevme2
* Last change: Fri Feb 27 17:56:49 2026 by root via cibadmin on hpevme3
* 3 nodes configured
* 7 resource instances configured
Node List:
* Node hpevme1 (1): OFFLINE
* Node hpevme2 (2): online, feature set 3.17.4
* Node hpevme3 (3): online, feature set 3.17.4
Full List of Resources:
* Clone Set: dlm-clone [dlm]:
* dlm (ocf:pacemaker:controld): Started hpevme2
* dlm (ocf:pacemaker:controld): Started hpevme3
* dlm (ocf:pacemaker:controld): Stopped
* hpevm_gfs2_scsi (stonith:fence_scsi_hpevm): Started hpevme2
* Clone Set: gfs2datastore_1ffa9-clone [gfs2datastore_1ffa9]:
* gfs2datastore_1ffa9 (ocf:heartbeat:Filesystem): Started hpevme2
* gfs2datastore_1ffa9 (ocf:heartbeat:Filesystem): Started hpevme3
* gfs2datastore_1ffa9 (ocf:heartbeat:Filesystem): Stopped
Migration Summary:
Fencing History:
* reboot of hpevme1 successful: delegate=hpevme2, client=stonith-api.30408, origin=hpevme2, completed='2026-03-04 13:05:43.082713 +09:00'
* unfencing of hpevme2 successful: delegate=hpevme2, client=pacemaker-fenced.2051, origin=hpevme3, completed='2026-03-04 10:50:33.986998 +09:00'
* unfencing of hpevme1 successful: delegate=hpevme1, client=pacemaker-controld.1993, origin=hpevme2, completed='2026-03-04 10:50:33.916998 +09:00'
* unfencing of hpevme3 successful: delegate=hpevme3, client=pacemaker-controld.1993, origin=hpevme2, completed='2026-03-04 10:50:33.773998 +09:00'
Tickets:
PCSD Status:
hpevme1: Offline
hpevme2: Online
hpevme3: Online
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
pcuser@hpevme2:~$
「sudo corosync-quorumtool -s」
pcuser@hpevme2:~$ sudo corosync-quorumtool -s
Quorum information
------------------
Date: Wed Mar 4 13:13:02 2026
Quorum provider: corosync_votequorum
Nodes: 2
Node ID: 2
Ring ID: 2.41
Quorate: Yes
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 2
Quorum: 2
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
2 1 hpevme2 (local)
3 1 hpevme3
pcuser@hpevme2:~$
「sudo corosync-cfgtool -n」
pcuser@hpevme2:~$ sudo corosync-cfgtool -n
Local node ID 2, transport knet
nodeid: 3 reachable
LINK: 0 udp (192.168.1.52->192.168.1.53) enabled connected mtu: 1397
pcuser@hpevme2:~$ sudo corosync-cfgtool -s
Local node ID 2, transport knet
LINK ID 0 udp
addr = 192.168.1.52
status:
nodeid: 1: disconnected
nodeid: 2: localhost
nodeid: 3: connected
pcuser@hpevme2:~$