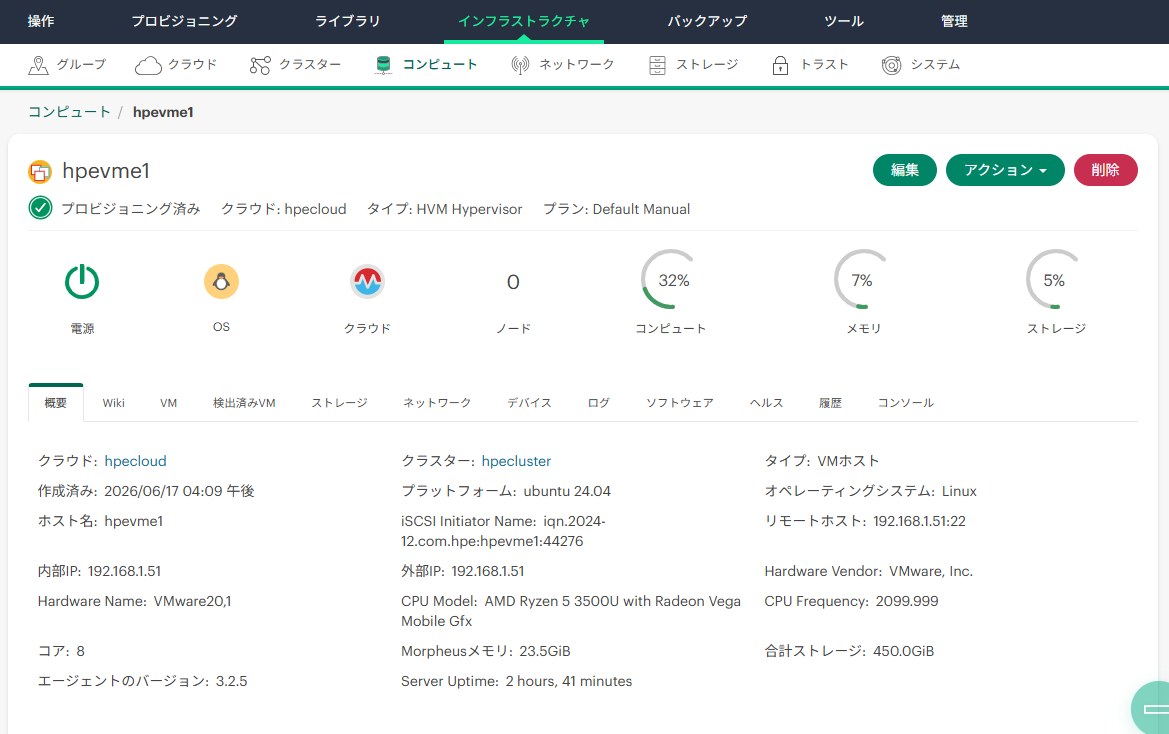
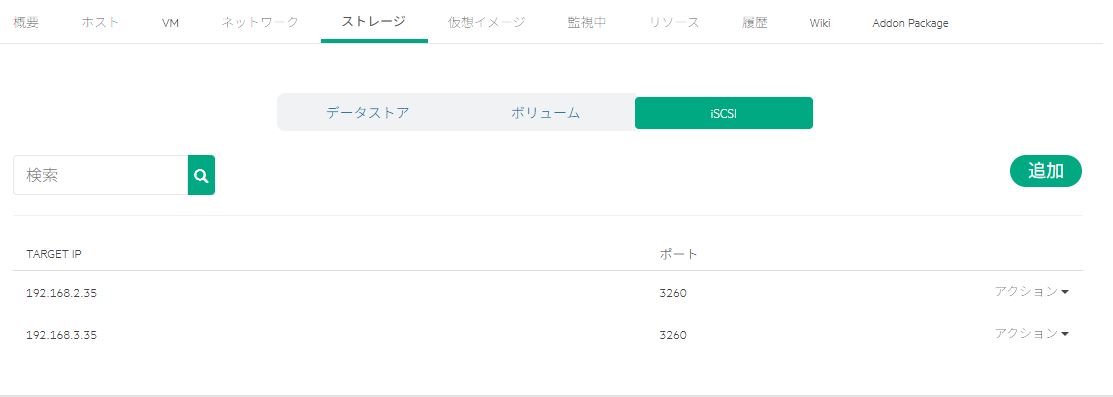
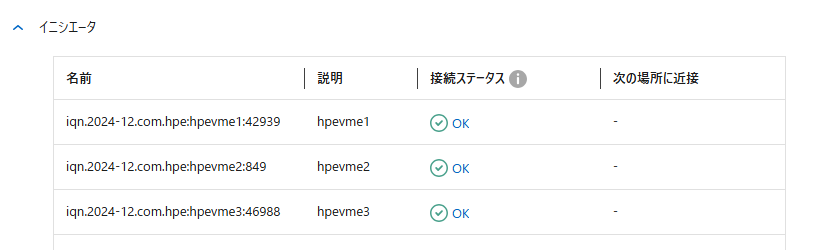
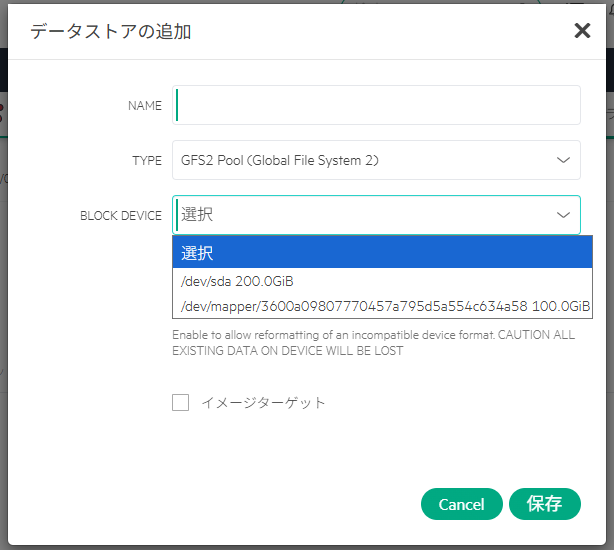
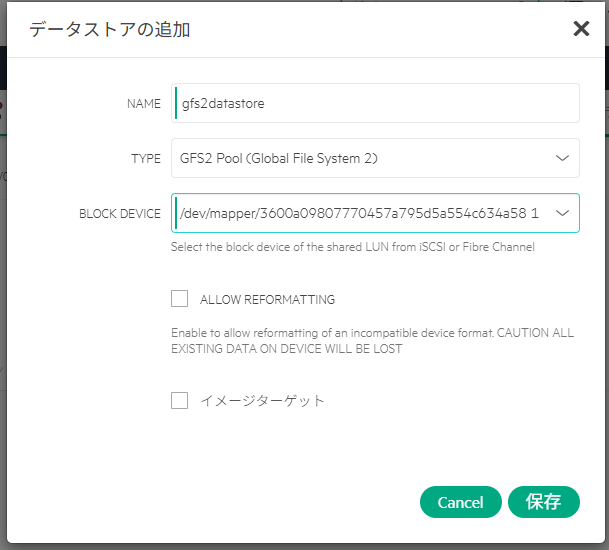
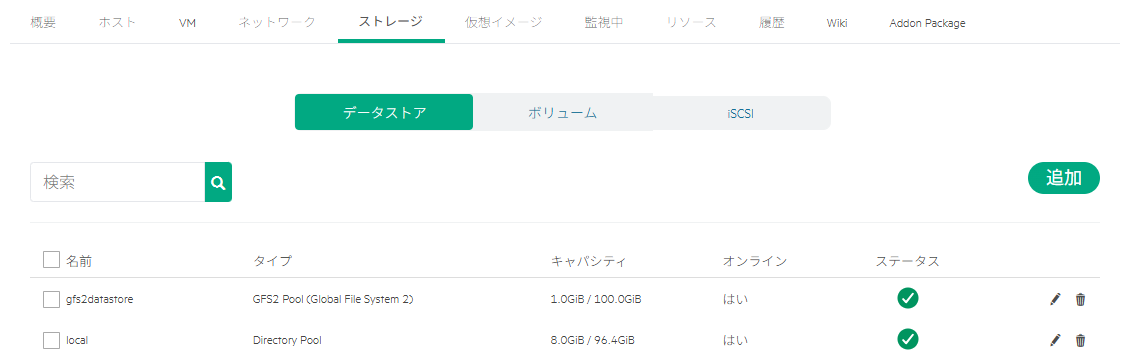
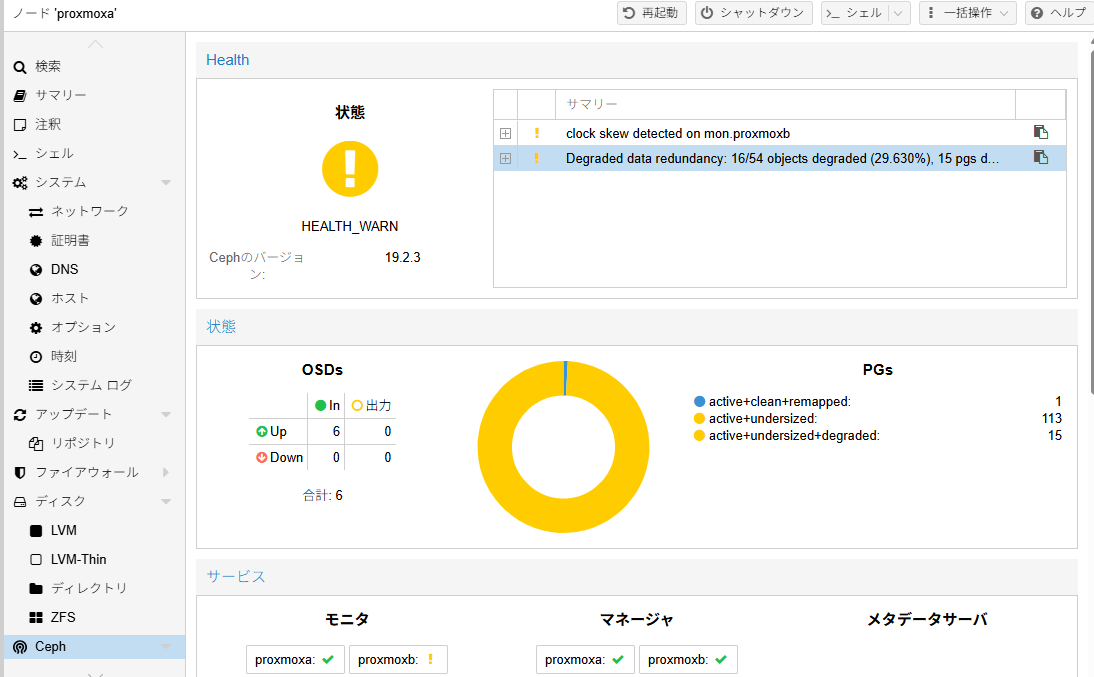
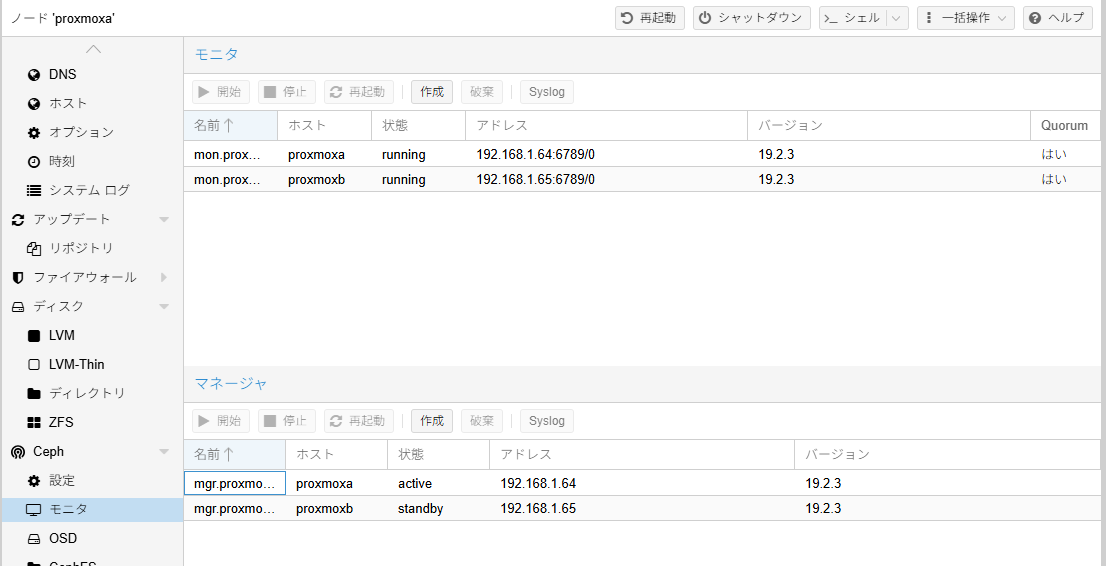
今度は「Active Directory Web サービスが実行されていない」ことがエラーの原因とされている。
Active Directory Web サービス について確認すると、どうやらsamba では提供されていないようだ。
2021年4月13日に作成されたsamba wikiのページ「ADWS / AD Powershell compatibility」に、「Samba does not support many of the AD PowerShell commands that manipulate AD objects,」とある
Connected to service
* List APIs: "help api list"
* List Plugins: "help pi list"
* Launch BASH: "shell"
Command> shell
Shell access is granted to root
root@vcsa [ ~ ]#
(3)dir-cliコマンドで現在のアカウント状態を確認
/usr/lib/vmware-vmafd/bin/dir-cli user find-by-name –account アカウント名 –level 2 「Password never expires:」が「FALSE」となっているとパスワード有効期限設定が有効で「Password expiry」にある日付で無効化される状態です。
/usr/lib/vmware-vmafd/bin/dir-cli user modify –account アカウント名 –password-never-expires
root@vcsa [ ~ ]# /usr/lib/vmware-vmafd/bin/dir-cli user modify --account backupuser --password-never-expires
Enter password for administrator@vsphere.local:
Password set to never expire for [backupuser].
root@vcsa [ ~ ]#
(5)dir-cliコマンドでアカウント状態が変更されたことを確認
/usr/lib/vmware-vmafd/bin/dir-cli user find-by-name –account アカウント名 –level 2 「Password never expires:」が「TRUE」となっているとパスワード有効期限設定が無効です 「Password expiry:N/A」と有効期限も未設定となっています
root@vcsa [ ~ ]# /usr/lib/vmware-vmafd/bin/dir-cli user find-by-name --account backupuser --level 2
Enter password for administrator@vsphere.local:
Account: backupuser
UPN: backupuser@VSPHERE.LOCAL
Account disabled: FALSE
Account locked: FALSE
Password never expires: TRUE
Password expired: FALSE
Password expiry: N/A
root@vcsa [ ~ ]#
ちなみにlevel 2オプションなしで実行した場合は下記情報しかみれません
root@vcsa [ ~ ]# /usr/lib/vmware-vmafd/bin/dir-cli user find-by-name –account backupuser Enter password for administrator@vsphere.local: Account: backupuser UPN: backupuser@VSPHERE.LOCAL root@vcsa [ ~ ]#
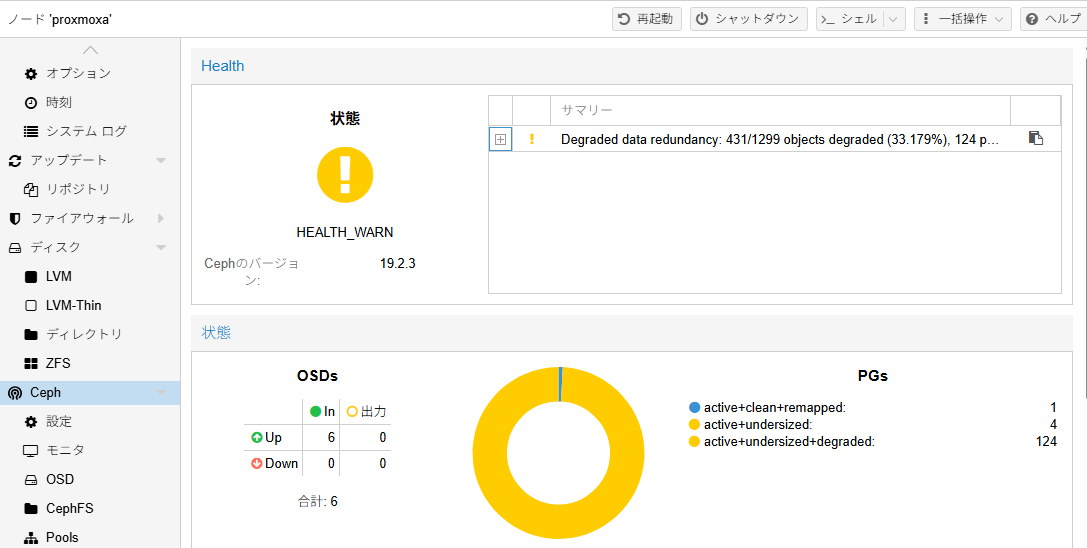
root@proxmoxa:~# ceph health
HEALTH_WARN clock skew detected on mon.proxmoxb; Degraded data redundancy: 28/90 objects degraded (31.111%), 25 pgs degraded, 128 pgs undersized
root@proxmoxa:~# ceph health detail
HEALTH_WARN clock skew detected on mon.proxmoxb; Degraded data redundancy: 39/123 objects degraded (31.707%), 35 pgs degraded, 128 pgs undersized
[WRN] MON_CLOCK_SKEW: clock skew detected on mon.proxmoxb
mon.proxmoxb clock skew 0.305298s > max 0.05s (latency 0.00675958s)
[WRN] PG_DEGRADED: Degraded data redundancy: 39/123 objects degraded (31.707%), 35 pgs degraded, 128 pgs undersized
pg 2.0 is stuck undersized for 26m, current state active+undersized, last acting [3,1]
pg 2.1 is stuck undersized for 26m, current state active+undersized, last acting [2,5]
pg 2.2 is stuck undersized for 26m, current state active+undersized, last acting [5,1]
pg 2.3 is stuck undersized for 26m, current state active+undersized, last acting [5,2]
pg 2.4 is stuck undersized for 26m, current state active+undersized+degraded, last acting [1,4]
pg 2.5 is stuck undersized for 26m, current state active+undersized, last acting [3,0]
pg 2.6 is stuck undersized for 26m, current state active+undersized, last acting [1,3]
pg 2.7 is stuck undersized for 26m, current state active+undersized+degraded, last acting [3,2]
pg 2.8 is stuck undersized for 26m, current state active+undersized, last acting [3,0]
pg 2.9 is stuck undersized for 26m, current state active+undersized, last acting [1,4]
pg 2.a is stuck undersized for 26m, current state active+undersized+degraded, last acting [1,4]
pg 2.b is stuck undersized for 26m, current state active+undersized, last acting [3,0]
pg 2.c is stuck undersized for 26m, current state active+undersized, last acting [2,3]
pg 2.d is stuck undersized for 26m, current state active+undersized, last acting [1,3]
pg 2.e is stuck undersized for 26m, current state active+undersized+degraded, last acting [2,3]
pg 2.f is stuck undersized for 26m, current state active+undersized, last acting [4,0]
pg 2.10 is stuck undersized for 26m, current state active+undersized, last acting [2,4]
pg 2.11 is stuck undersized for 26m, current state active+undersized, last acting [4,1]
pg 2.1c is stuck undersized for 26m, current state active+undersized+degraded, last acting [4,2]
pg 2.1d is stuck undersized for 26m, current state active+undersized, last acting [3,0]
pg 2.1e is stuck undersized for 26m, current state active+undersized+degraded, last acting [2,5]
pg 2.1f is stuck undersized for 26m, current state active+undersized+degraded, last acting [0,3]
pg 2.20 is stuck undersized for 26m, current state active+undersized+degraded, last acting [5,1]
pg 2.21 is stuck undersized for 26m, current state active+undersized, last acting [2,4]
pg 2.22 is stuck undersized for 26m, current state active+undersized, last acting [3,2]
pg 2.23 is stuck undersized for 26m, current state active+undersized, last acting [0,3]
pg 2.24 is stuck undersized for 26m, current state active+undersized, last acting [5,1]
pg 2.25 is stuck undersized for 26m, current state active+undersized, last acting [4,1]
pg 2.26 is stuck undersized for 26m, current state active+undersized, last acting [5,2]
pg 2.27 is stuck undersized for 26m, current state active+undersized, last acting [3,0]
pg 2.28 is stuck undersized for 26m, current state active+undersized, last acting [2,3]
pg 2.29 is stuck undersized for 26m, current state active+undersized+degraded, last acting [3,1]
pg 2.2a is stuck undersized for 26m, current state active+undersized, last acting [5,0]
pg 2.2b is stuck undersized for 26m, current state active+undersized, last acting [2,4]
pg 2.2c is stuck undersized for 26m, current state active+undersized, last acting [2,5]
pg 2.2d is stuck undersized for 26m, current state active+undersized, last acting [5,2]
pg 2.2e is stuck undersized for 26m, current state active+undersized+degraded, last acting [5,0]
pg 2.2f is stuck undersized for 26m, current state active+undersized+degraded, last acting [5,0]
pg 2.30 is stuck undersized for 26m, current state active+undersized+degraded, last acting [4,0]
pg 2.31 is stuck undersized for 26m, current state active+undersized, last acting [0,5]
pg 2.32 is stuck undersized for 26m, current state active+undersized, last acting [5,1]
pg 2.33 is stuck undersized for 26m, current state active+undersized, last acting [3,1]
pg 2.34 is stuck undersized for 26m, current state active+undersized+degraded, last acting [5,0]
pg 2.35 is stuck undersized for 26m, current state active+undersized, last acting [1,3]
pg 2.36 is stuck undersized for 26m, current state active+undersized, last acting [1,4]
pg 2.37 is stuck undersized for 26m, current state active+undersized, last acting [3,1]
pg 2.38 is stuck undersized for 26m, current state active+undersized+degraded, last acting [0,5]
pg 2.39 is stuck undersized for 26m, current state active+undersized, last acting [1,5]
pg 2.7d is stuck undersized for 26m, current state active+undersized, last acting [0,4]
pg 2.7e is stuck undersized for 26m, current state active+undersized+degraded, last acting [0,4]
pg 2.7f is stuck undersized for 26m, current state active+undersized+degraded, last acting [4,1]
root@proxmoxa:~#
root@proxmoxa:~# ceph health
HEALTH_WARN Degraded data redundancy: 426/1284 objects degraded (33.178%), 124 pgs degraded, 128 pgs undersized
root@proxmoxa:~# ceph health detail
HEALTH_WARN Degraded data redundancy: 422/1272 objects degraded (33.176%), 124 pgs degraded, 128 pgs undersized
[WRN] PG_DEGRADED: Degraded data redundancy: 422/1272 objects degraded (33.176%), 124 pgs degraded, 128 pgs undersized
pg 2.0 is stuck undersized for 39m, current state active+undersized+degraded, last acting [3,1]
pg 2.1 is stuck undersized for 39m, current state active+undersized+degraded, last acting [2,5]
pg 2.2 is stuck undersized for 39m, current state active+undersized+degraded, last acting [5,1]
pg 2.3 is stuck undersized for 39m, current state active+undersized+degraded, last acting [5,2]
pg 2.4 is stuck undersized for 39m, current state active+undersized+degraded, last acting [1,4]
pg 2.5 is stuck undersized for 39m, current state active+undersized+degraded, last acting [3,0]
pg 2.6 is stuck undersized for 39m, current state active+undersized+degraded, last acting [1,3]
pg 2.7 is stuck undersized for 39m, current state active+undersized+degraded, last acting [3,2]
pg 2.8 is stuck undersized for 39m, current state active+undersized+degraded, last acting [3,0]
pg 2.9 is stuck undersized for 39m, current state active+undersized+degraded, last acting [1,4]
pg 2.a is stuck undersized for 39m, current state active+undersized+degraded, last acting [1,4]
pg 2.b is stuck undersized for 39m, current state active+undersized+degraded, last acting [3,0]
pg 2.c is stuck undersized for 39m, current state active+undersized+degraded, last acting [2,3]
pg 2.d is stuck undersized for 39m, current state active+undersized+degraded, last acting [1,3]
pg 2.e is stuck undersized for 39m, current state active+undersized+degraded, last acting [2,3]
pg 2.f is stuck undersized for 39m, current state active+undersized+degraded, last acting [4,0]
pg 2.10 is stuck undersized for 39m, current state active+undersized+degraded, last acting [2,4]
pg 2.11 is active+undersized+degraded, acting [4,1]
pg 2.1c is stuck undersized for 39m, current state active+undersized+degraded, last acting [4,2]
pg 2.1d is stuck undersized for 39m, current state active+undersized+degraded, last acting [3,0]
pg 2.1e is stuck undersized for 39m, current state active+undersized+degraded, last acting [2,5]
pg 2.1f is stuck undersized for 39m, current state active+undersized+degraded, last acting [0,3]
pg 2.20 is stuck undersized for 39m, current state active+undersized+degraded, last acting [5,1]
pg 2.21 is stuck undersized for 39m, current state active+undersized+degraded, last acting [2,4]
pg 2.22 is stuck undersized for 39m, current state active+undersized+degraded, last acting [3,2]
pg 2.23 is stuck undersized for 39m, current state active+undersized+degraded, last acting [0,3]
pg 2.24 is stuck undersized for 39m, current state active+undersized+degraded, last acting [5,1]
pg 2.25 is stuck undersized for 39m, current state active+undersized+degraded, last acting [4,1]
pg 2.26 is stuck undersized for 39m, current state active+undersized+degraded, last acting [5,2]
pg 2.27 is stuck undersized for 39m, current state active+undersized, last acting [3,0]
pg 2.28 is stuck undersized for 39m, current state active+undersized+degraded, last acting [2,3]
pg 2.29 is stuck undersized for 39m, current state active+undersized+degraded, last acting [3,1]
pg 2.2a is stuck undersized for 39m, current state active+undersized+degraded, last acting [5,0]
pg 2.2b is stuck undersized for 39m, current state active+undersized+degraded, last acting [2,4]
pg 2.2c is stuck undersized for 39m, current state active+undersized+degraded, last acting [2,5]
pg 2.2d is stuck undersized for 39m, current state active+undersized+degraded, last acting [5,2]
pg 2.2e is stuck undersized for 39m, current state active+undersized+degraded, last acting [5,0]
pg 2.2f is stuck undersized for 39m, current state active+undersized+degraded, last acting [5,0]
pg 2.30 is stuck undersized for 39m, current state active+undersized+degraded, last acting [4,0]
pg 2.31 is stuck undersized for 39m, current state active+undersized+degraded, last acting [0,5]
pg 2.32 is stuck undersized for 39m, current state active+undersized+degraded, last acting [5,1]
pg 2.33 is stuck undersized for 39m, current state active+undersized+degraded, last acting [3,1]
pg 2.34 is stuck undersized for 39m, current state active+undersized+degraded, last acting [5,0]
pg 2.35 is stuck undersized for 39m, current state active+undersized+degraded, last acting [1,3]
pg 2.36 is stuck undersized for 39m, current state active+undersized+degraded, last acting [1,4]
pg 2.37 is stuck undersized for 39m, current state active+undersized+degraded, last acting [3,1]
pg 2.38 is stuck undersized for 39m, current state active+undersized+degraded, last acting [0,5]
pg 2.39 is stuck undersized for 39m, current state active+undersized+degraded, last acting [1,5]
pg 2.7d is stuck undersized for 39m, current state active+undersized+degraded, last acting [0,4]
pg 2.7e is stuck undersized for 39m, current state active+undersized+degraded, last acting [0,4]
pg 2.7f is stuck undersized for 39m, current state active+undersized+degraded, last acting [4,1]
root@proxmoxa:~#
root@proxmoxa:~# ceph osd pool autoscale-status
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE BULK
.mgr 452.0k 3.0 98280M 0.0000 1.0 1 on False
cephpool 2234M 20480M 3.0 98280M 0.6252 1.0 128 on False
root@proxmoxa:~#
root@proxmoxa:~# ceph config get osd osd_pool_default_size
3
root@proxmoxa:~# ceph config get osd osd_pool_default_min_size
0
root@proxmoxa:~#
root@proxmoxa:~# ceph config set osd osd_pool_default_size 2
root@proxmoxa:~# ceph config set osd osd_pool_default_min_size 1
root@proxmoxa:~# ceph config get osd osd_pool_default_size
2
root@proxmoxa:~# ceph config get osd osd_pool_default_min_size
1
root@proxmoxa:~#
状態に変化はなさそう
root@proxmoxa:~# ceph -s
cluster:
id: 26b59237-5bed-45fe-906e-aa3b13033b86
health: HEALTH_WARN
Degraded data redundancy: 885/2661 objects degraded (33.258%), 128 pgs degraded, 128 pgs undersized
services:
mon: 2 daemons, quorum proxmoxa,proxmoxb (age 2h)
mgr: proxmoxa(active, since 2h), standbys: proxmoxb
osd: 6 osds: 6 up (since 2h), 6 in (since 2h); 1 remapped pgs
data:
pools: 2 pools, 129 pgs
objects: 887 objects, 3.4 GiB
usage: 7.1 GiB used, 89 GiB / 96 GiB avail
pgs: 885/2661 objects degraded (33.258%)
2/2661 objects misplaced (0.075%)
128 active+undersized+degraded
1 active+clean+remapped
root@proxmoxa:~# ceph osd pool autoscale-status
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE BULK
.mgr 452.0k 3.0 98280M 0.0000 1.0 1 on False
cephpool 2319M 20480M 3.0 98280M 0.6252 1.0 128 on False
root@proxmoxa:~# ceph osd pool stats
pool .mgr id 1
2/6 objects misplaced (33.333%)
pool cephpool id 2
885/2655 objects degraded (33.333%)
client io 170 B/s wr, 0 op/s rd, 0 op/s wr
root@proxmoxa:~# ceph osd pool ls detail
pool 1 '.mgr' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 18 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr read_balance_score 6.06
pool 2 'cephpool' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 128 pgp_num 128 autoscale_mode on last_change 39 flags hashpspool,selfmanaged_snaps stripe_width 0 target_size_bytes 21474836480 application rbd read_balance_score 1.41
removed_snaps_queue [2~1]
root@proxmoxa:~#
ceph osd pool get コマンドで、各プールのsizeとmin_sizeを確認
root@proxmoxa:~# ceph osd pool get cephpool size
size: 3
root@proxmoxa:~# ceph osd pool get cephpool min_size
min_size: 2
root@proxmoxa:~#
設定を変更
root@proxmoxa:~# ceph osd pool set cephpool size 2
set pool 2 size to 2
root@proxmoxa:~# ceph osd pool set cephpool min_size 1
set pool 2 min_size to 1
root@proxmoxa:~# ceph osd pool get cephpool size
size: 2
root@proxmoxa:~# ceph osd pool get cephpool min_size
min_size: 1
root@proxmoxa:~#
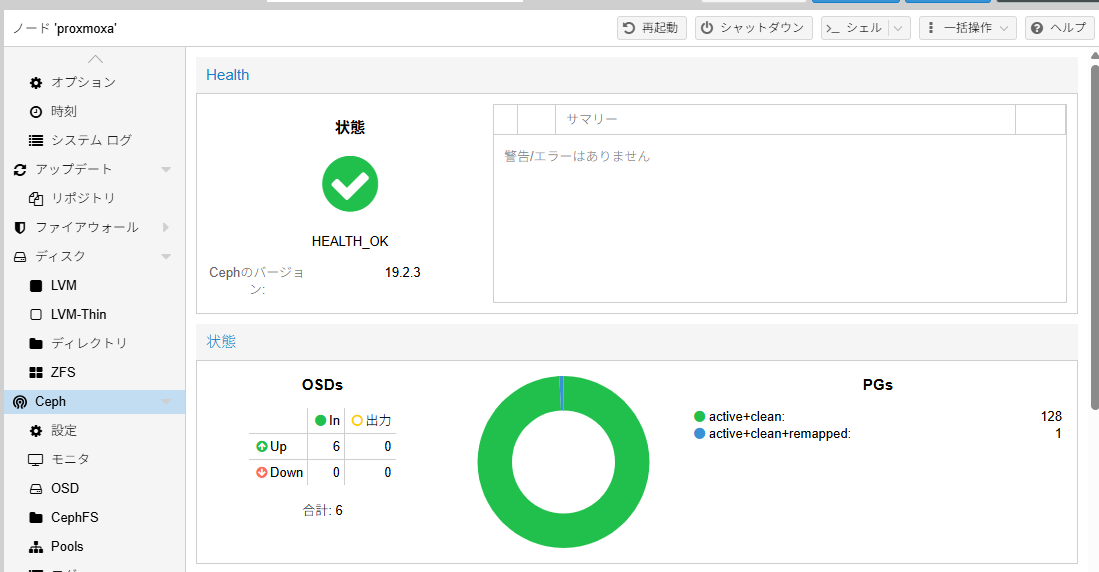
状態確認すると、ceph health がHEALTH_OKになっている
root@proxmoxa:~# ceph health
HEALTH_OK
root@proxmoxa:~# ceph health detail
HEALTH_OK
root@proxmoxa:~#
他のステータスは?と確認してみると、問題無く見える
root@proxmoxa:~# ceph -s
cluster:
id: 26b59237-5bed-45fe-906e-aa3b13033b86
health: HEALTH_OK
services:
mon: 2 daemons, quorum proxmoxa,proxmoxb (age 2h)
mgr: proxmoxa(active, since 2h), standbys: proxmoxb
osd: 6 osds: 6 up (since 2h), 6 in (since 2h); 1 remapped pgs
data:
pools: 2 pools, 129 pgs
objects: 887 objects, 3.4 GiB
usage: 7.1 GiB used, 89 GiB / 96 GiB avail
pgs: 2/1776 objects misplaced (0.113%)
128 active+clean
1 active+clean+remapped
io:
recovery: 1.3 MiB/s, 0 objects/s
root@proxmoxa:~# ceph osd pool autoscale-status
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE BULK
.mgr 452.0k 3.0 98280M 0.0000 1.0 1 on False
cephpool 3479M 20480M 2.0 98280M 0.4168 1.0 128 on False
root@proxmoxa:~# ceph osd pool stats
pool .mgr id 1
2/6 objects misplaced (33.333%)
pool cephpool id 2
nothing is going on
root@proxmoxa:~# ceph osd pool ls detail
pool 1 '.mgr' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 18 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr read_balance_score 6.06
pool 2 'cephpool' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 128 pgp_num 128 autoscale_mode on last_change 42 flags hashpspool,selfmanaged_snaps stripe_width 0 target_size_bytes 21474836480 application rbd read_balance_score 1.17
root@proxmoxa:~#
GUIもHEALTH_OK
障害テスト
片側を停止してどうなるか?
PVEのクラスタ側は生きている
root@proxmoxa:~# ha-manager status
quorum OK
master proxmoxa (active, Wed Jan 21 17:43:39 2026)
lrm proxmoxa (active, Wed Jan 21 17:43:40 2026)
lrm proxmoxb (old timestamp - dead?, Wed Jan 21 17:43:08 2026)
service vm:100 (proxmoxa, started)
root@proxmoxa:~# pvecm status
Cluster information
-------------------
Name: cephcluster
Config Version: 3
Transport: knet
Secure auth: on
Quorum information
------------------
Date: Wed Jan 21 17:44:11 2026
Quorum provider: corosync_votequorum
Nodes: 1
Node ID: 0x00000001
Ring ID: 1.3b
Quorate: Yes
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 2
Quorum: 2
Flags: Quorate Qdevice
Membership information
----------------------
Nodeid Votes Qdevice Name
0x00000001 1 A,V,NMW 192.168.2.64 (local)
0x00000000 1 Qdevice
root@proxmoxa:~#
しかし、cephのステータスは死んでいる
「ceph helth」コマンドを実行してみると返事が返ってこない
root@proxmoxa:~# ceph health
ダメそうなので、停止したノードを復帰
ceph osd poolの.mgrについてもsizeとmin_sizeを変更
root@proxmoxa:~# ceph osd pool ls
.mgr
cephpool
root@proxmoxa:~# ceph osd pool get .mgr size
size: 3
root@proxmoxa:~# ceph osd pool get .mgr min_size
min_size: 2
root@proxmoxa:~# ceph osd pool set .mgr size 2
set pool 1 size to 2
root@proxmoxa:~# ceph osd pool set .mgr min_size 1
set pool 1 min_size to 1
root@proxmoxa:~# ceph osd pool get .mgr size
size: 2
root@proxmoxa:~# ceph osd pool get .mgr min_size
min_size: 1
root@proxmoxa:~#
で、先のブログにあるようにmonパラメータも変更するため、現在値を確認
root@proxmoxa:~# ceph config get mon mon_osd_min_down_reporters
2
root@proxmoxa:~# ceph config get mon mon_osd_down_out_interval
600
root@proxmoxa:~# ceph config get mon mon_osd_report_timeout
900
root@proxmoxa:~#
これをそれぞれ変更
root@proxmoxa:~# ceph config set mon mon_osd_min_down_reporters 1
root@proxmoxa:~# ceph config set mon mon_osd_down_out_interval 120
root@proxmoxa:~# ceph config set mon mon_osd_report_timeout 90
root@proxmoxa:~# ceph config get mon mon_osd_min_down_reporters
1
root@proxmoxa:~# ceph config get mon mon_osd_down_out_interval
120
root@proxmoxa:~# ceph config get mon mon_osd_report_timeout
90
root@proxmoxa:~#
root@proxmoxa:~# ceph osd pool ls
.mgr
cephpool
root@proxmoxa:~# ceph osd pool get .mgr size
size: 2
root@proxmoxa:~# ceph osd pool get .mgr min_size
min_size: 1
root@proxmoxa:~# ceph osd pool set .mgr size 4
set pool 1 size to 4
root@proxmoxa:~# ceph osd pool set .mgr min_size 2
set pool 1 min_size to 2
root@proxmoxa:~# ceph osd pool get .mgr size
size: 4
root@proxmoxa:~# ceph osd pool get .mgr min_size
min_size: 2
root@proxmoxa:~# ceph osd pool get cephpool size
size: 2
root@proxmoxa:~# ceph osd pool get cephpool min_size
min_size: 1
root@proxmoxa:~# ceph osd pool set cephpool size 4
set pool 2 size to 4
root@proxmoxa:~# ceph osd pool set cephpool min_size 2
set pool 2 min_size to 2
root@proxmoxa:~# ceph osd pool get cephpool size
size: 4
root@proxmoxa:~# ceph osd pool get cephpool min_size
min_size: 2
root@proxmoxa:~#
この状態でceph osd pool statsを取ると先ほどまで33.333%だったものが50.0% なった
root@proxmoxa:~# ceph osd pool stats
pool .mgr id 1
4/8 objects degraded (50.000%)
pool cephpool id 2
1770/3540 objects degraded (50.000%)
root@proxmoxa:~# ceph -s
cluster:
id: 26b59237-5bed-45fe-906e-aa3b13033b86
health: HEALTH_WARN
Degraded data redundancy: 1774/3548 objects degraded (50.000%), 129 pgs degraded, 129 pgs undersized
services:
mon: 2 daemons, quorum proxmoxa,proxmoxb (age 6h)
mgr: proxmoxb(active, since 6h), standbys: proxmoxa
osd: 6 osds: 6 up (since 6h), 6 in (since 24h)
data:
pools: 2 pools, 129 pgs
objects: 887 objects, 3.4 GiB
usage: 7.0 GiB used, 89 GiB / 96 GiB avail
pgs: 1774/3548 objects degraded (50.000%)
129 active+undersized+degraded
root@proxmoxa:~#
root@proxmoxa:~# ceph health
HEALTH_WARN Degraded data redundancy: 1774/3548 objects degraded (50.000%), 129 pgs degraded, 129 pgs undersized
root@proxmoxa:~# ceph health detail
HEALTH_WARN Degraded data redundancy: 1774/3548 objects degraded (50.000%), 129 pgs degraded, 129 pgs undersized
[WRN] PG_DEGRADED: Degraded data redundancy: 1774/3548 objects degraded (50.000%), 129 pgs degraded, 129 pgs undersized
pg 1.0 is stuck undersized for 5m, current state active+undersized+degraded, last acting [3,0]
pg 2.0 is stuck undersized for 5m, current state active+undersized+degraded, last acting [3,1]
pg 2.1 is stuck undersized for 5m, current state active+undersized+degraded, last acting [2,5]
pg 2.2 is stuck undersized for 5m, current state active+undersized+degraded, last acting [5,1]
pg 2.3 is stuck undersized for 5m, current state active+undersized+degraded, last acting [5,2]
pg 2.4 is stuck undersized for 5m, current state active+undersized+degraded, last acting [1,4]
pg 2.5 is stuck undersized for 5m, current state active+undersized+degraded, last acting [4,0]
pg 2.6 is stuck undersized for 5m, current state active+undersized+degraded, last acting [1,3]
pg 2.7 is stuck undersized for 5m, current state active+undersized+degraded, last acting [3,2]
pg 2.8 is stuck undersized for 5m, current state active+undersized+degraded, last acting [3,0]
pg 2.9 is stuck undersized for 5m, current state active+undersized+degraded, last acting [1,4]
pg 2.a is stuck undersized for 5m, current state active+undersized+degraded, last acting [1,4]
pg 2.b is stuck undersized for 5m, current state active+undersized+degraded, last acting [3,0]
pg 2.c is stuck undersized for 5m, current state active+undersized+degraded, last acting [2,3]
pg 2.d is stuck undersized for 5m, current state active+undersized+degraded, last acting [2,3]
pg 2.e is stuck undersized for 5m, current state active+undersized+degraded, last acting [2,3]
pg 2.f is stuck undersized for 5m, current state active+undersized+degraded, last acting [4,0]
pg 2.10 is active+undersized+degraded, acting [2,4]
pg 2.1c is stuck undersized for 5m, current state active+undersized+degraded, last acting [4,2]
pg 2.1d is stuck undersized for 5m, current state active+undersized+degraded, last acting [3,0]
pg 2.1e is stuck undersized for 5m, current state active+undersized+degraded, last acting [2,5]
pg 2.1f is stuck undersized for 5m, current state active+undersized+degraded, last acting [0,3]
pg 2.20 is stuck undersized for 5m, current state active+undersized+degraded, last acting [5,1]
pg 2.21 is stuck undersized for 5m, current state active+undersized+degraded, last acting [2,4]
pg 2.22 is stuck undersized for 5m, current state active+undersized+degraded, last acting [3,2]
pg 2.23 is stuck undersized for 5m, current state active+undersized+degraded, last acting [0,3]
pg 2.24 is stuck undersized for 5m, current state active+undersized+degraded, last acting [5,1]
pg 2.25 is stuck undersized for 5m, current state active+undersized+degraded, last acting [4,2]
pg 2.26 is stuck undersized for 5m, current state active+undersized+degraded, last acting [5,2]
pg 2.27 is stuck undersized for 5m, current state active+undersized+degraded, last acting [3,0]
pg 2.28 is stuck undersized for 5m, current state active+undersized+degraded, last acting [2,3]
pg 2.29 is stuck undersized for 5m, current state active+undersized+degraded, last acting [3,1]
pg 2.2a is stuck undersized for 5m, current state active+undersized+degraded, last acting [5,0]
pg 2.2b is stuck undersized for 5m, current state active+undersized+degraded, last acting [2,4]
pg 2.2c is stuck undersized for 5m, current state active+undersized+degraded, last acting [2,5]
pg 2.2d is stuck undersized for 5m, current state active+undersized+degraded, last acting [5,2]
pg 2.2e is stuck undersized for 5m, current state active+undersized+degraded, last acting [5,0]
pg 2.2f is stuck undersized for 5m, current state active+undersized+degraded, last acting [5,0]
pg 2.30 is stuck undersized for 5m, current state active+undersized+degraded, last acting [4,0]
pg 2.31 is stuck undersized for 5m, current state active+undersized+degraded, last acting [0,5]
pg 2.32 is stuck undersized for 5m, current state active+undersized+degraded, last acting [5,1]
pg 2.33 is stuck undersized for 5m, current state active+undersized+degraded, last acting [3,1]
pg 2.34 is stuck undersized for 5m, current state active+undersized+degraded, last acting [5,0]
pg 2.35 is stuck undersized for 5m, current state active+undersized+degraded, last acting [1,3]
pg 2.36 is stuck undersized for 5m, current state active+undersized+degraded, last acting [1,4]
pg 2.37 is stuck undersized for 5m, current state active+undersized+degraded, last acting [3,1]
pg 2.38 is stuck undersized for 5m, current state active+undersized+degraded, last acting [0,5]
pg 2.39 is stuck undersized for 5m, current state active+undersized+degraded, last acting [1,5]
pg 2.7d is stuck undersized for 5m, current state active+undersized+degraded, last acting [0,4]
pg 2.7e is stuck undersized for 5m, current state active+undersized+degraded, last acting [0,4]
pg 2.7f is stuck undersized for 5m, current state active+undersized+degraded, last acting [4,1]
root@proxmoxa:~#
このときのceph osd treeは下記の状態
root@proxmoxa:~# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.09357 root default
-5 0.04678 host proxmoxa
3 ssd 0.01559 osd.3 up 1.00000 1.00000
4 ssd 0.01559 osd.4 up 1.00000 1.00000
5 ssd 0.01559 osd.5 up 1.00000 1.00000
-3 0.04678 host proxmoxb
0 ssd 0.01559 osd.0 up 1.00000 1.00000
1 ssd 0.01559 osd.1 up 1.00000 1.00000
2 ssd 0.01559 osd.2 up 1.00000 1.00000
root@proxmoxa:~#
次にCRUSH Structureを2個作る
root@proxmoxa:~# ceph osd crush add-bucket room1 room
added bucket room1 type room to crush map
root@proxmoxa:~# ceph osd crush add-bucket room2 room
added bucket room2 type room to crush map
root@proxmoxa:~# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-8 0 room room2
-7 0 room room1
-1 0.09357 root default
-5 0.04678 host proxmoxa
3 ssd 0.01559 osd.3 up 1.00000 1.00000
4 ssd 0.01559 osd.4 up 1.00000 1.00000
5 ssd 0.01559 osd.5 up 1.00000 1.00000
-3 0.04678 host proxmoxb
0 ssd 0.01559 osd.0 up 1.00000 1.00000
1 ssd 0.01559 osd.1 up 1.00000 1.00000
2 ssd 0.01559 osd.2 up 1.00000 1.00000
root@proxmoxa:~#
で、移動?
root@proxmoxa:~# ceph osd crush move room1 root=default
moved item id -7 name 'room1' to location {root=default} in crush map
root@proxmoxa:~# ceph osd crush move room2 root=default
moved item id -8 name 'room2' to location {root=default} in crush map
root@proxmoxa:~# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.09357 root default
-5 0.04678 host proxmoxa
3 ssd 0.01559 osd.3 up 1.00000 1.00000
4 ssd 0.01559 osd.4 up 1.00000 1.00000
5 ssd 0.01559 osd.5 up 1.00000 1.00000
-3 0.04678 host proxmoxb
0 ssd 0.01559 osd.0 up 1.00000 1.00000
1 ssd 0.01559 osd.1 up 1.00000 1.00000
2 ssd 0.01559 osd.2 up 1.00000 1.00000
-7 0 room room1
-8 0 room room2
root@proxmoxa:~#
次にノードをそれぞれ別のroomに移動
root@proxmoxa:~# ceph osd crush move proxmoxa room=room1
moved item id -5 name 'proxmoxa' to location {room=room1} in crush map
root@proxmoxa:~# ceph osd crush move proxmoxb room=room2
moved item id -3 name 'proxmoxb' to location {room=room2} in crush map
root@proxmoxa:~# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.09357 root default
-7 0.04678 room room1
-5 0.04678 host proxmoxa
3 ssd 0.01559 osd.3 up 1.00000 1.00000
4 ssd 0.01559 osd.4 up 1.00000 1.00000
5 ssd 0.01559 osd.5 up 1.00000 1.00000
-8 0.04678 room room2
-3 0.04678 host proxmoxb
0 ssd 0.01559 osd.0 up 1.00000 1.00000
1 ssd 0.01559 osd.1 up 1.00000 1.00000
2 ssd 0.01559 osd.2 up 1.00000 1.00000
root@proxmoxa:~#
CRUSH ruleを作成
root@proxmoxa:~# ceph osd getcrushmap > crush.map.bin
25
root@proxmoxa:~# ls -l crush.map.bin
-rw-r--r-- 1 root root 1104 Jan 22 16:31 crush.map.bin
root@proxmoxa:~# crushtool -d crush.map.bin -o crush.map.txt
root@proxmoxa:~# ls -l crush.map*
-rw-r--r-- 1 root root 1104 Jan 22 16:31 crush.map.bin
-rw-r--r-- 1 root root 1779 Jan 22 16:31 crush.map.txt
root@proxmoxa:~#
crush.map.bin はバイナリファイルなので、crushtoolでテキストにしたものを作成
現状の内容は下記だった
root@proxmoxa:~# cat crush.map.txt
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices
device 0 osd.0 class ssd
device 1 osd.1 class ssd
device 2 osd.2 class ssd
device 3 osd.3 class ssd
device 4 osd.4 class ssd
device 5 osd.5 class ssd
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
# buckets
host proxmoxa {
id -5 # do not change unnecessarily
id -6 class ssd # do not change unnecessarily
# weight 0.04678
alg straw2
hash 0 # rjenkins1
item osd.3 weight 0.01559
item osd.4 weight 0.01559
item osd.5 weight 0.01559
}
room room1 {
id -7 # do not change unnecessarily
id -10 class ssd # do not change unnecessarily
# weight 0.04678
alg straw2
hash 0 # rjenkins1
item proxmoxa weight 0.04678
}
host proxmoxb {
id -3 # do not change unnecessarily
id -4 class ssd # do not change unnecessarily
# weight 0.04678
alg straw2
hash 0 # rjenkins1
item osd.0 weight 0.01559
item osd.1 weight 0.01559
item osd.2 weight 0.01559
}
room room2 {
id -8 # do not change unnecessarily
id -9 class ssd # do not change unnecessarily
# weight 0.04678
alg straw2
hash 0 # rjenkins1
item proxmoxb weight 0.04678
}
root default {
id -1 # do not change unnecessarily
id -2 class ssd # do not change unnecessarily
# weight 0.09357
alg straw2
hash 0 # rjenkins1
item room1 weight 0.04678
item room2 weight 0.04678
}
# rules
rule replicated_rule {
id 0
type replicated
step take default
step chooseleaf firstn 0 type host
step emit
}
# end crush map
root@proxmoxa:~#
root@proxmoxa:~# ceph osd pool stats
pool .mgr id 1
4/8 objects misplaced (50.000%)
pool cephpool id 2
448/3540 objects degraded (12.655%)
1272/3540 objects misplaced (35.932%)
root@proxmoxa:~# ceph osd pool get cephpool pgp_num
pgp_num: 128
root@proxmoxa:~# ceph osd pool set cephpool pgp_num 32
set pool 2 pgp_num to 32
root@proxmoxa:~# ceph osd pool get cephpool pgp_num
pgp_num: 128
root@proxmoxa:~#
# samba-tool domain level show
Domain and forest function level for domain 'DC=adsample,DC=local'
Forest function level: (Windows) 2008 R2
Domain function level: (Windows) 2008 R2
Lowest function level of a DC: (Windows) 2008 R2
#
# samba-tool domain level raise --forest-level=2012_R2
ERROR: Forest function level can't be higher than the domain function level(s). Please raise it/them first!
# samba-tool domain level raise --domain-level=2012_R2
ERROR: Domain function level can't be higher than the lowest function level of a DC!
#
# /usr/local/samba/bin/testparm -s --section-name=global --parameter-name="ad dc functional level"
Load smb config files from /usr/local/samba/etc/smb.conf
Loaded services file OK.
Weak crypto is allowed by GnuTLS (e.g. NTLM as a compatibility fallback)
2008_R2
#
この結果を受けて/usr/local/samba/etc/smb.conf のglobalセクションに「ad dc functional level = 2016」という記述を追加する
# cat /usr/local/samba/etc/smb.conf
# Global parameters
[global]
dns forwarder = 8.8.8.8
netbios name = ADSERVER
realm = ADSAMPLE.LOCAL
server role = active directory domain controller
workgroup = ADSAMPLE
idmap_ldb:use rfc2307 = yes
ad dc functional level = 2016
[sysvol]
path = /usr/local/samba/var/locks/sysvol
read only = No
[netlogon]
path = /usr/local/samba/var/locks/sysvol/adsample.local/scripts
read only = No
#
testparamで記述が反映されているかを確認
# /usr/local/samba/bin/testparm -s --section-name=global --parameter-name="ad dc functional level"
Load smb config files from /usr/local/samba/etc/smb.conf
Loaded services file OK.
Weak crypto is allowed by GnuTLS (e.g. NTLM as a compatibility fallback)
2016
#
sambaを再起動して、機能レベルがどうなったのかを確認
# systemctl restart samba-ad-dc
# samba-tool domain level show
Domain and forest function level for domain 'DC=adsample,DC=local'
Forest function level: (Windows) 2008 R2
Domain function level: (Windows) 2008 R2
Lowest function level of a DC: (Windows) 2016
#
Lowest function level of a DC が変更されたので、上2つも変更できるようになった
まずはドメインの機能レベルを変更
# samba-tool domain level raise --domain-level=2012_R2
Domain function level changed!
All changes applied successfully!
# samba-tool domain level show
Domain and forest function level for domain 'DC=adsample,DC=local'
Forest function level: (Windows) 2008 R2
Domain function level: (Windows) 2012 R2
Lowest function level of a DC: (Windows) 2016
#
続いてフォレストの機能レベルを変更
# samba-tool domain level raise --forest-level=2012_R2
Forest function level changed!
All changes applied successfully!
# samba-tool domain level show
Domain and forest function level for domain 'DC=adsample,DC=local'
Forest function level: (Windows) 2012 R2
Domain function level: (Windows) 2012 R2
Lowest function level of a DC: (Windows) 2016
#