Covia FLEAZ F4をCP-F03aからの乗り換えキャンペーンで入手した!
<注意:「FLEAZ F4」についての記事です。「FLEAZ F4s」についてではありません>
月曜にCP-F03aの送り先情報が来て、火曜に発送して、水曜夕方に先方に到着し、木曜にFLEAZ F4が発送され、金曜に手元に到着、というなかなかのスケジュールで届きました。

先代のCP-F03aは、手元にないので、CP-D02との比較写真
左:CP-D02、右:FLEAZ F4


まぁ、ほぼ同じ大きさです。
で・・・USBデバグを有効にして、パソコンに接続。
adb接続で使うUSBデバイス名は「VID_0A5C&PID_E688&MI_01」なので、ADB Interfaceを割り当てましょう。
電源を入れるとこの画面。
まぁ、Android 4.4的なやつですね。
入っているアプリは・・・
最小限ですね。
まだファームウェアアップデートはないようです。
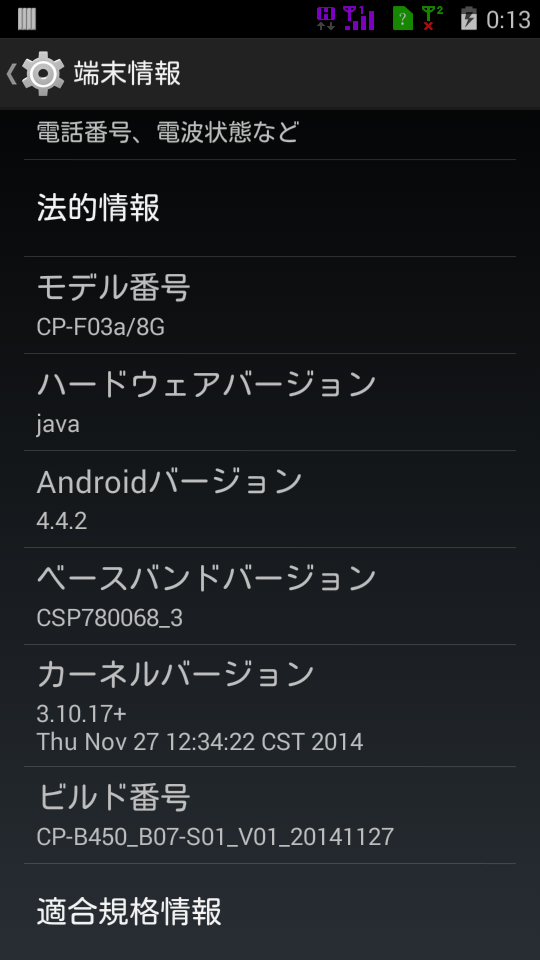
端末情報はこんな感じです。
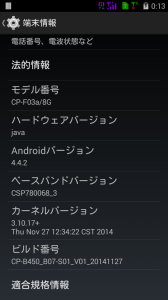
モデル番号:CP-F03a/8G
ハードウェアバージョン:Java
Androidバージョン:4.4.2
ベースバンドバージョン:CSP780068_3
カーネルバージョン:3.10.17+ Thu Nov 27 12:34:22 CST 2014
ビルド番号:CP-B450_B07-S01_V01_20141127
APNはどこもMNVO系を各種取り揃えていました。
exite, biglobe_3g
bmobile_aeon, bmobile_amazon, bmobile_fair, bmobile_cameleon, bmobile_4g, bmobile_denwa, bmobile_yodo
rakuten_lte, serverman_lte, hito_lte, iijmio
docomo_mopera, docomo_flat, sonet_lte, unext
asahi_lte, ocn_mobile_one
うちは、iijmioだったので、自動認識しました。
で・・・この設定画面
これと、ベースバンドバージョンの書き方から考えると、この端末はBroadcom系チップの模様。
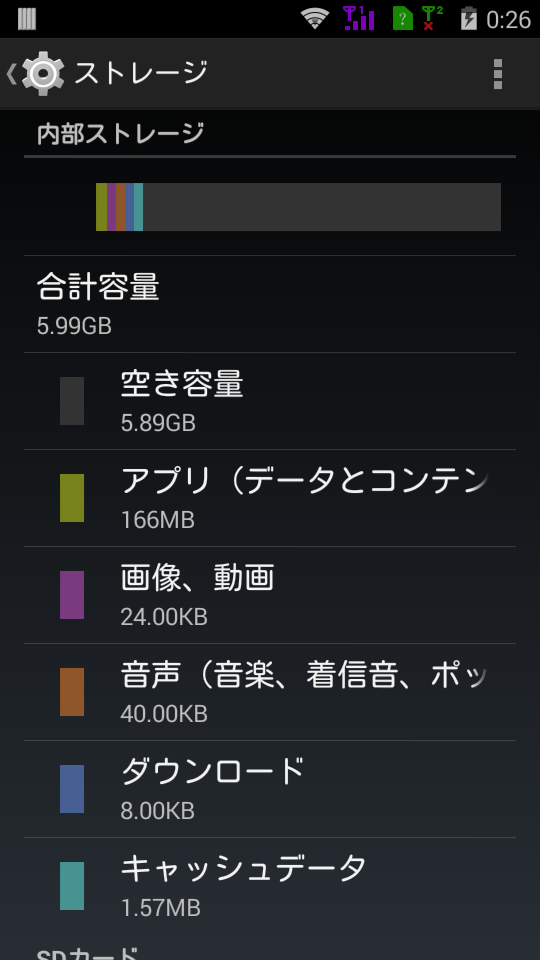
初期状態のストレージ利用量はこのような感じ。
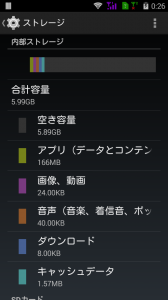
dfコマンドの出力結果としては・・・
shell@java_c_edn000:/ $ df
Filesystem Size Used Free Blksize
/dev 478.8M 128.0K 478.7M 4096
/sys/fs/cgroup 478.8M 12.0K 478.8M 4096
/mnt/secure 478.8M 0.0K 478.8M 4096
/mnt/asec 478.8M 0.0K 478.8M 4096
/mnt/obb 478.8M 0.0K 478.8M 4096
/system 678.0M 605.0M 73.1M 4096
/cache 143.6M 160.0K 143.5M 4096
/data 6.0G 85.0M 5.9G 4096
/dev/usb-ffs/adb: Permission denied
/mnt/shell/emulated 6.0G 85.0M 5.9G 4096
/mnt/media_rw/sdcard1: Permission denied
/mnt/secure/asec: Permission denied
/storage/sdcard1 7.4G 4.6G 2.8G 32768
1|shell@java_c_edn000:/ $
そして、/default.prop
#
# ADDITIONAL_DEFAULT_PROPERTIES
#
ro.secure=1
ro.allow.mock.location=0
ro.debuggable=0
persist.sys.usb.config=mtp
persist.brcm.log=auto
persist.brcm.cp_crash=auto
persist.brcm.ap_crash=auto
ro.adb.secure=1
/system/build.propはこんな感じ。
# begin build properties
# autogenerated by buildinfo.sh
ro.build.id=KOT49H
ro.build.display.id=CP-B450_B07-S01_V01_20141127
ro.build.version.incremental=eng.lijian.20141127.123747
ro.build.version.sdk=19
ro.build.version.codename=REL
ro.build.version.release=4.4.2
ro.build.date=Thu Nov 27 12:42:27 CST 2014
ro.build.date.utc=1417063347
ro.build.type=user
ro.build.user=lijian
ro.build.host=mtk-ui3
ro.build.tags=release-keys
ro.product.model=CP-F03a/8G
ro.product.brand=BRCM
ro.product.name=java_c_edn000
ro.product.device=java_c_edn000
ro.product.board=java
ro.product.cpu.abi=armeabi-v7a
ro.product.cpu.abi2=armeabi
ro.product.manufacturer=BROADCOM
ro.product.locale.language=en
ro.product.locale.region=US
ro.wifi.channels=
ro.board.platform=java
# ro.build.product is obsolete; use ro.product.device
ro.build.product=java_c_edn000
# Do not try to parse ro.build.description or .fingerprint
ro.build.description=java_c_edn000-user 4.4.2 KOT49H eng.lijian.20141127.123747release-keys
ro.build.fingerprint=BRCM/java_c_edn000/java_c_edn000:4.4.2/KOT49H/5476AAAB:user/release-keys
ro.build.characteristics=default
# end build properties
#
# from device/broadcom/java_garnet/java_c_edn000/system.prop
#
#
# system.prop for java garnet edn000
#
#If this property set to "1", DUT will power off with no confirmation
#If this property set to "0", DUT will prompt dialogue for power off
factory.long_press_power_off=0
# Show EAP-SIM/AKA menu on Settings application
ro.wifi.eap_simaka=true
# When AP panic or CP assertion:
# 0: Only reboot without dump in final product
# 1: Dump + reboot in development(default)
persist.sys.panic.dump.debug=0
#
# ADDITIONAL_BUILD_PROPERTIES
#
ro.storage.switch_primary=0
ro.mms.copy_to_sim=1
ro.config.builtin_cdrom=1
sys.storage.asec.external=1
persist.sys.timezone=Asia/Tokyo
ro.config.ringtone_2=Ring_Synth_04.ogg
ro.config.ringtone=Ring_Synth_04.ogg
ro.sys.phonenumber.minmatch=7
ro.config.notification_sound=pixiedust.ogg
persist.sys.language=ja
ro.storage.internal.reserved.mb=50
ro.config.fontscale=1.15
ro.sys.ime=com.pm9.flickwnn/.OpenWnnJAJP
persist.sys.country=JP
ro.sys.auto_timezone=1
ro.config.alarm_alert=Alarm_Classic.ogg
ro.setupwizard.mode=OPTIONAL
ro.com.google.gmsversion=4.1_r1
ro.addon.type=gapps
ro.addon.platform=kk
ro.addon.version=gapps-kk-20140105
ro.addon.minimumversion=4.4.2
ro.opengles.version=131072
wifi.interface=wlan0
ro.com.android.dataroaming=false
af.resampler.quality=4
ro.com.google.clientidbase=android-acme
dalvik.vm.heapstartsize=5m
dalvik.vm.heapgrowthlimit=48m
dalvik.vm.heapsize=128m
dalvik.vm.heaptargetutilization=0.75
dalvik.vm.heapminfree=512k
dalvik.vm.heapmaxfree=2m
ro.bt.bdaddr_path=/data/misc/bluetooth/.bt.mac.info
drm.service.enabled=true
dalvik.vm.jniopts=warnonly
ro.max_fb_resolution=1280x720
rild.libpath=/system/lib/libbrcm_ril.so
ro.sf.lcd_density=240
ro.product.multi_touch_enabled=true
ro.product.max_num_touch=2
awesome.lateness=200
nuplayer.eos.timeout=3
sf.metadata_use_plat_sw_codecs=1
sf.metadata_retrv_hw_codecs=1
persist.audio.pcmout1.sweq=ON
persist.audio.pcmout2.sweq=ON
ro.loudspk.primarymic=ANALOG
debug.nativeofinterest=1
ro.com.android.mobiledata=false
persist.sys.cmas.enable=1
keyguard.no_require_sim=true
ro.com.android.dateformat=MM-dd-yyyy
ro.carrier=unknown
persist.sys.dalvik.vm.lib=libdvm.so
dalvik.vm.dexopt-flags=m=y
net.bt.name=Android
dalvik.vm.stack-trace-file=/data/anr/traces.txt
NFCがなくなったけど、やっぱりBroadcomで、マジでCP-F03aの後継機でした!
ということは・・・と、CP-F03aが充電できなかったAnker 40W 5ポート USB急速充電器 PowerIQ搭載 ホワイトにつないでみると、やっぱり充電できない・・・
Broadcom系共通の問題なんでしょうかねぇ・・・
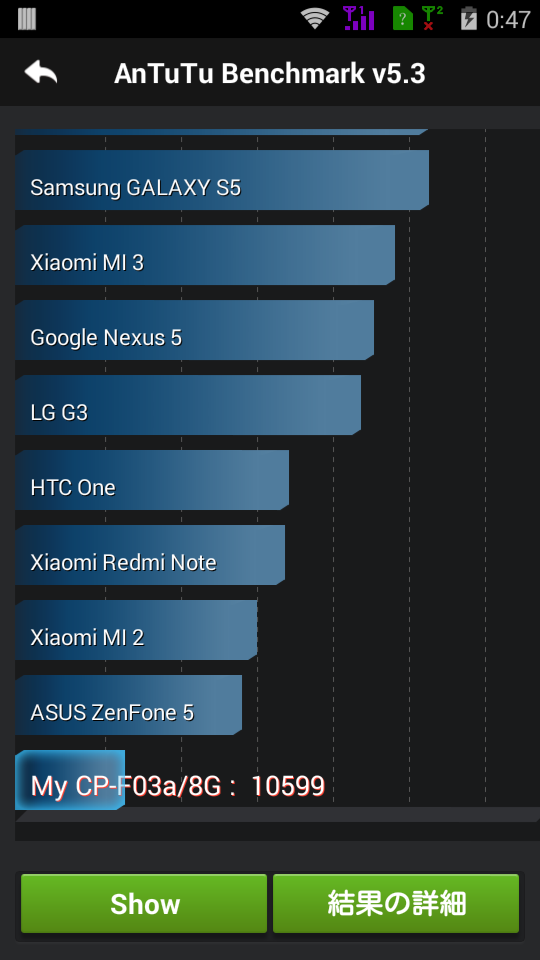
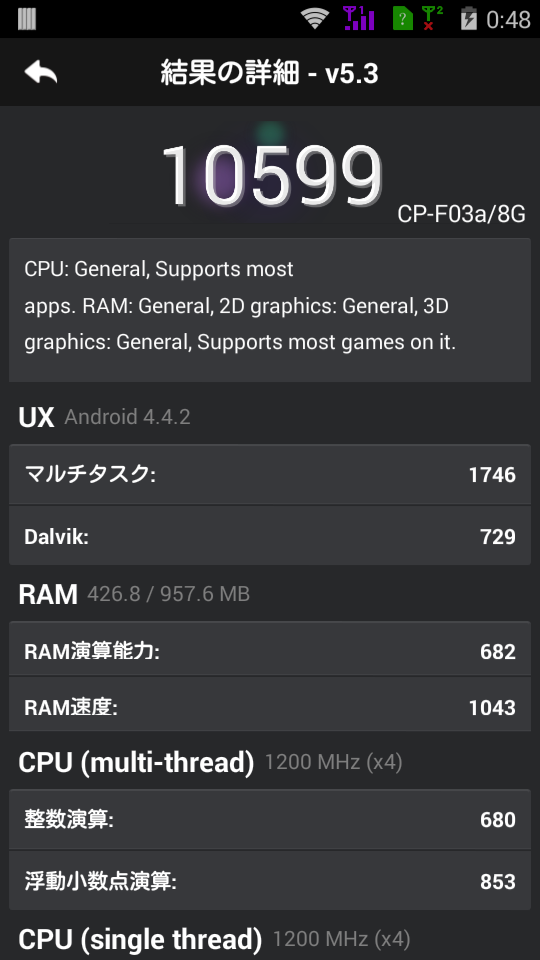
とりあえず、Antutuさんをインストールして・・・
測定結果は・・・

「10599」
詳細は・・・
まぁ、最初の雰囲気としては悪くはないですね。
これからいろいろ使ってみてどうなることやら・・・