現在はてなブログで運用しているけど、画像付きでのエクスポートができない、とかいう話を聞いた。
ローカルに静的コンテンツとして取り込もう
とりあえず、本文と画像をダウンロードすればいいだろう、と、まずは簡単に下記でコンテンツ取得をかけた。
wget --mirror \
--page-requisites \
--quiet --show-progress \
--no-parent \
--convert-links \
--adjust-extension \
--execute robots=off \
https://retoge-mag.hatenablog.com/
適当なWebサーバに配置して見てみると、HTMLのみで、そしてサイト内リンクもhttpsからフルで指定されているタイプだったので、URL書き換えを雑に実施。
他にもHTML書き換えが必要だろう、ということでダウンロードしてきたやつではなく、閲覧用のHTMLを別に用意することにして、下記の様に実行した。
cp -r retoge-mag.hatenablog.com viewpage
for file in `find ./viewpage -name \*.html -print`
do
sed -i -e "s/retoge-mag.hatenablog.com/retoge-mag.websa.jp\/old\/viewpage/g" $file
done
これでまずはHTMLのみがコピーされた状態だが、リンクをいくつかクリックしてみると404 not foundとなるものがある。
日付ごとのまとめはダウンロードされていないが、これについては無視することとした。
個別記事のリンクで、末尾が数字で終わっているものがいくつかあり、それで404が発生していた。それらのコンテンツは数字.htmlという形でダウンロードされていたので .htaccess に下記の設定を行った。
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{REQUEST_FILENAME} !-f
RewriteRule ^(.*)$ $1.html [L]
</IfModule>
次に画像のダウンロードを行った。
HTMLからhttp か httpsで始まるリンクっぽいものを集めてみると画像は st-hatena.com というドメイン名の所に置いてあるようだった。
なので、下記スクリプトを実行して、該当するURLを全てダウンロードしてきた。
for file in `find ./viewpage -name \*.html -print`
do
grep -oE 'http(s?)://[0-9a-zA-Z?=#+_&:;/.%\-]+' $file >> urllists.txt
done
sort urllists.txt | uniq > urllists2.txt
grep st-hatena.com urllists2.txt > urllists3.txt
wget --mirror --page-requisites --quiet --show-progress --no-parent --convert-links --adjust-extension -i urllists3.txt
なお、最初は「grep -oE ‘http(s?)://[0-9a-zA-Z?=#+_&:/.%-]+’ $file >> urllists.txt」だったのだが、縮小処理をかけた画像のURLに;が含まれていたので、追加している。
画像はローカルにダウンロードできたものの、HTMLの方は書き換わっていないため、以下で書き換えを実施した。
for file in `find ./viewpage -name \*.html -print`
do
sed -i -e "s/b.st-hatena.com/retoge-mag.websa.jp\/old\/b.st-hatena.com/g" $file
sed -i -e "s/cdn-ak.f.st-hatena.com/retoge-mag.websa.jp\/old\/cdn-ak.f.st-hatena.com/g" $file
sed -i -e "s/cdn.blog.st-hatena.com/retoge-mag.websa.jp\/old\/cdn.blog.st-hatena.com/g" $file
sed -i -e "s/cdn.pool.st-hatena.com/retoge-mag.websa.jp\/old\/cdn.pool.st-hatena.com/g" $file
sed -i -e "s/cdn.profile-image.st-hatena.com/retoge-mag.websa.jp\/old\/cdn.profile-image.st-hatena.com/g" $file
sed -i -e "s/cdn.user.blog.st-hatena.com/retoge-mag.websa.jp\/old\/cdn.user.blog.st-hatena.com/g" $file
sed -i -e "s/usercss.blog.st-hatena.com/retoge-mag.websa.jp\/old\/usercss.blog.st-hatena.com/g" $file
done
これで、見栄えは悪いものの画像ファイル含めてローカルにコンテンツ自体はコピーされた。
WordPressに取り込もう
あまりにも見栄えが悪いので、やっぱりWordpressに取り込むべきか、とインポート用XMLファイルを作ることにする。
WordPressのサイトを調べたのだがインポート用XMLファイルの仕様がよくわからなかった。
まず、Wordpressで適当に記事とカテゴリを作成して、それをエクスポートしたXMLを作成した。
結構いらない要素が多い感じがしたので最小限の記述はなにか探したところ「Simple WordPress Import Structure XML Example」を発見。
<?xml version="1.0" encoding="UTF-8" ?>
<rss version="2.0"
xmlns:excerpt="http://wordpress.org/export/1.2/excerpt/"
xmlns:content="http://purl.org/rss/1.0/modules/content/"
xmlns:wfw="http://wellformedweb.org/CommentAPI/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:wp="http://wordpress.org/export/1.2/"
>
<channel>
<wp:wxr_version>1.2</wp:wxr_version>
<wp:author></wp:author>
<item>
<title>Test 1</title>
<description></description>
<content:encoded><![CDATA[Test Post 1]]></content:encoded>
<excerpt:encoded><![CDATA[]]></excerpt:encoded>
<wp:status>publish</wp:status>
<wp:post_type>post</wp:post_type>
<category domain="post_tag" nicename="redy"><![CDATA[redy]]></category>
<category domain="category" nicename="teory"><![CDATA[Teory]]></category>
<category domain="category" nicename="tree"><![CDATA[Tree]]></category>
</item>
<item>
<title>Test 2</title>
<description></description>
<content:encoded><![CDATA[Test Post 2]]></content:encoded>
<excerpt:encoded><![CDATA[]]></excerpt:encoded>
<wp:status>publish</wp:status>
<wp:post_type>post</wp:post_type>
<category domain="category" nicename="test-category"><![CDATA[Test Category]]></category>
</item>
</channel>
</rss>
これをベースに作成することにした。
はてなブログが出力したHTMLから下記の要素を抜き出してXMLタグを出力する test.plを作成した。
#!/bin/perl
#
use strict;
use warnings;
my $sourcefile=$ARGV[0];
if(!-f $sourcefile){
print "file not found\n";
exit 1;
}
my $i=0;
my @bodys;
open(FILE,$sourcefile);
while(<FILE>){
$bodys[$i]=$_;
$i++;
}
close(FILE);
my $maxline=$i;
my $line;
my ($st,$ed,$tmp);
my $createdate="";
my $modifydate="";
my $title="";
my $categorys="";
my $categoryssub="";
my $categorysterm="";
my $author="";
my $contents="";
my $description="";
$i=0;
while($i<$maxline){
$line=$bodys[$i];
if(($line =~ /<time datetime=/)&&($createdate eq "")){
# 作成日取得
# 下の方に他のページのdatetimeもあるので1個目だけ採用
$st=index($line,"datetime=");
$st=index($line,"\"",$st)+length("\"");
$ed=index($line,"\"",$st);
$createdate=substr($line,$st,$ed-$st);
#}elsif(($line =~ /entry-footer-time/)&&($line =~ /class=\"updated\"/)){
}elsif($line =~ /dateModified/){
# 更新日取得
$st=index($line,"dateModified");
$st=index($line,":",$st);
$st=index($line,"\"",$st)+length("\"");
$ed=index($line,"\"",$st);
$modifydate=substr($line,$st,$ed-$st);
}elsif($line =~ /entry-title-link/){
# タイトル取得
$st=index($line,">")+length(">");
$ed=index($line,"</",$st);
$title=substr($line,$st,$ed-$st);
}elsif($line =~ /entry-categories/){
# カテゴリ取得
my $flag=0;
while($flag==0){
$i++;
$line=$bodys[$i];
if($line =~/<\/div>/){
# カテゴリ終了
$flag=1;
}elsif($line =~ /entry-category-link/){
$st=index($line,">")+length(">");
$ed=index($line,"</",$st);
$tmp=substr($line,$st,$ed-$st);
$categorys.="<category domain=\"category\" nicename=\"".$tmp."\" ><![CDATA[".$tmp."]]></category>";
}
}
}elsif($line =~ /author vcard/){
# 作者取得
$ed=index($line,"</");
$st=rindex($line,">",$ed)+length(">");
$author=substr($line,$st,$ed-$st);
}elsif($line =~ /entry-content/){
# 本文取得
my $flag=0;
while($flag==0){
$i++;
$line=$bodys[$i];
if($line =~/entry-footer/){
# 本文終了
$flag=1;
}else{
$contents.=$line;
}
}
}elsif($line =~ /og:description/){
# description取得
$st=index($line,"content=\"")+length("content=\"");
$ed=index($line,"\"",$st);
$description=substr($line,$st,$ed-$st);
}
$i++;
}
# URL変換処理
$contents =~ s/b.st-hatena.com/retoge-mag.websa.jp\/old\/b.st-hatena.com/g;
$contents =~ s/cdn-ak.f.st-hatena.com/retoge-mag.websa.jp\/old\/cdn-ak.f.st-hatena.com/g;
$contents =~ s/cdn.blog.st-hatena.com/retoge-mag.websa.jp\/old\/cdn.blog.st-hatena.com/g;
$contents =~ s/cdn.pool.st-hatena.com/retoge-mag.websa.jp\/old\/cdn.pool.st-hatena.com/g;
$contents =~ s/cdn.profile-image.st-hatena.com/retoge-mag.websa.jp\/old\/cdn.profile-image.st-hatena.com/g;
$contents =~ s/cdn.user.blog.st-hatena.com/retoge-mag.websa.jp\/old\/cdn.user.blog.st-hatena.com/g;
$contents =~ s/usercss.blog.st-hatena.com/retoge-mag.websa.jp\/old\/usercss.blog.st-hatena.com/g;
#
print "<item>\n";
print "<description>".$description."</description>\n";
print "<excerpt:encoded><![CDATA[]]></excerpt:encoded>\n";
print "<wp:status>publish</wp:status>\n";
print "<wp:post_type>post</wp:post_type>\n";
print "<wp:post_date_gmt>".$createdate."</wp:post_date_gmt>\n";
#print "<wp:post_modified_gmt>".$modifydate."</wp:post_modified_gmt>\n";
print "<wp:post_modified>".$modifydate."</wp:post_modified>\n";
print "<title><![CDATA[".$title."]]></title>\n";
print $categorys."\n";
#print "<dc:creator><![CDATA[".$author."]]></dc:creator>\n";
print "<dc:creator><![CDATA[pc88multi2]]></dc:creator>\n";
#print "<content:encoded><![CDATA[<!-- wp:paragraph -->\n".$contents."<!-- /wp:paragraph -->]]></content:encoded>\n";
print "<content:encoded><![CDATA[".$contents."]]></content:encoded>\n";
print "</item>\n";
このtest.pl は単体ファイルに対してのみ実行されるので、対象ファイル群に対して実行するために下記の別スクリプトを用意して実行した。
echo '<?xml version="1.0" encoding="UTF-8" ?>' > wordpress.xml
echo '<rss version="2.0" xmlns:excerpt="http://wordpress.org/export/1.2/excerpt/" xmlns:content="http://purl.org/rss/1.0/modules/content/" xmlns:wfw="http://wellformedweb.org/CommentAPI/" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:wp="http://wordpress.org/export/1.2/" >' >> wordpress.xml
echo '<channel><wp:wxr_version>1.2</wp:wxr_version>' >> wordpress.xml
echo '<wp:author></wp:author>' >> wordpress.xml
for file in `find retoge-mag.hatenablog.com/entry/* -name \*.html`
do echo --- $file ---
./test.pl $file >> wordpress.xml
done
echo '</channel>' >> wordpress.xml
echo '</rss>' >> wordpress.xml
こうして出力されたwordpress.xmlをWordpressにてインポートすることで取り込みは完了した。
なお、画像ファイルについてはXMLへどうかけばいいのかが分からなかったため、ローカルにコピーした際のURLをそのまま利用し、Wordpress管理下には置かなかった。
2021/11/30追記
この手法で取り込むとWordpress上は「クラシック」形式での状態となっていた。
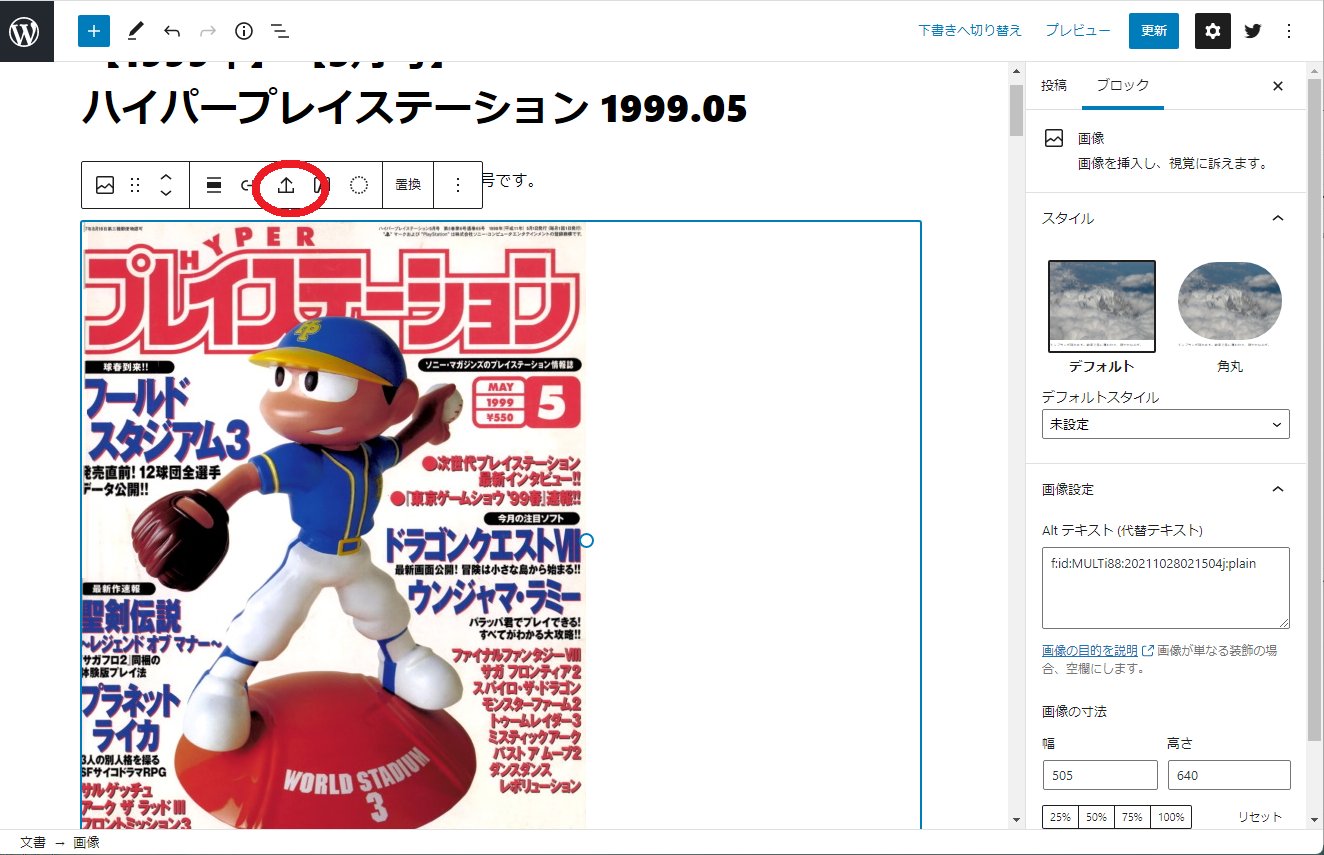
各記事で「ブロックへ変換」を行ったあと
各画像でを選択し「↑」ボタンをクリックすると画像がWordpress管理下にあるwp-contentsディレクトリ内にダウンロードされ、Wordpressで管理できるようになった。