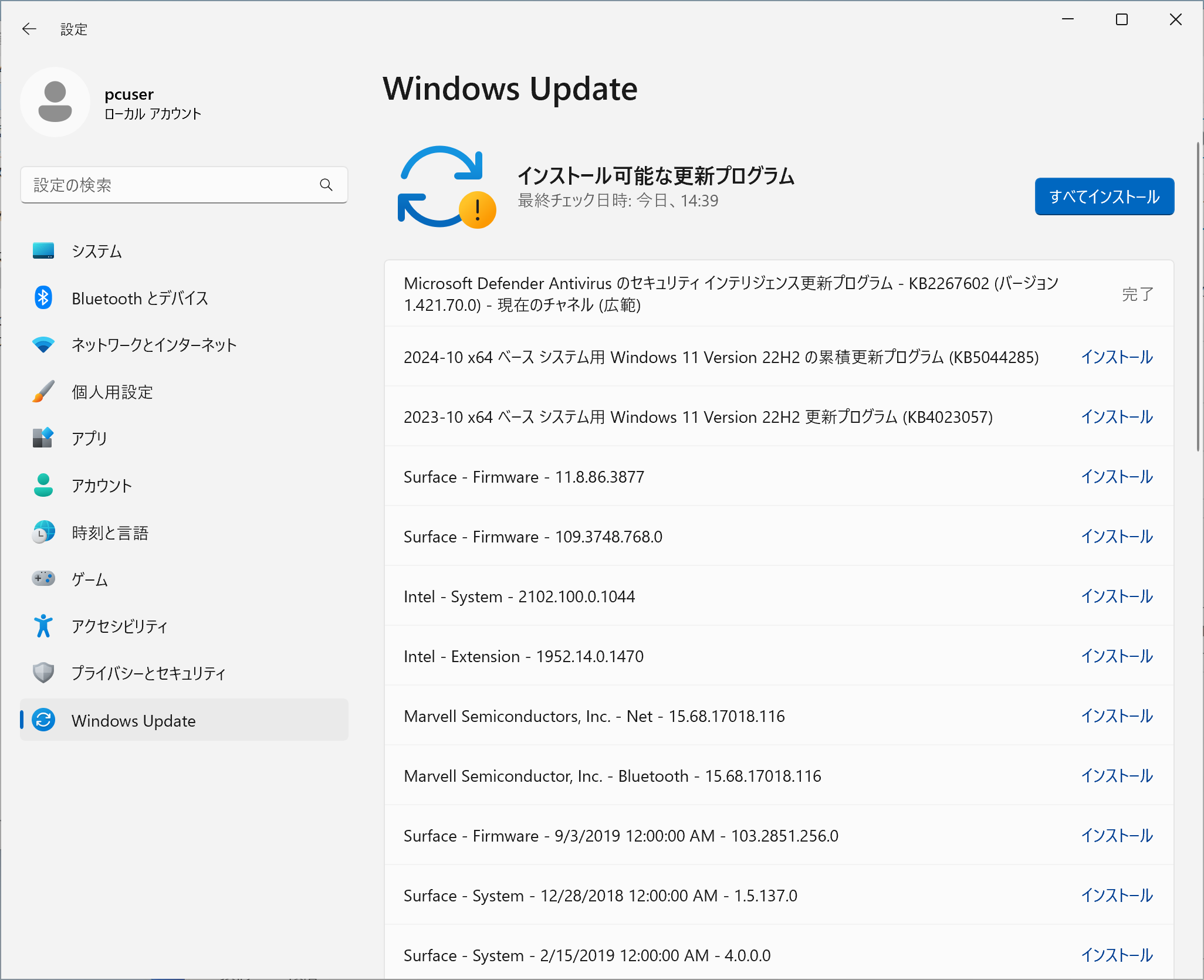
Proxmox VE環境でcephによるストレージ領域を作成して、物理的にディスクを共有していない状態で複数サーバ間を1ファイルシステムで運用できる環境についての試験中。
Proxmox VEクラスタをUPS連動で停止する場合の処理について確認しているのだが、公式ドキュメントにそのまま使えるようなものがないので、情報を集めているところ・・・
Proxmox VE公式ドキュメント:Shutdown Proxmox VE + Ceph HCI cluster
これはceph側の処理だけかかれていて、ceph側を止める前には仮想マシンを停止しなければならないのに、そこについて触れていない。
Proxmox VEフォーラムを探す
Clean shutdown of whole cluster (2023/01/16)
Shutdown of the Hyper-Converged Cluster (CEPH) (2020/04/05)
ここらのスクリプトが使えそうだが、仮想マシン/コンテナを停止するのは「各ノードで pvenode stopallを実行」ではなく、「APIを使ってすべてを停止する」が推奨される模様。
ここから試験
「pvesh get /nodes」でノードリストを作って、「ssh ホスト名 pvenode stopall」で仮想マシンを停止できるか試してみたが、管理Web上は「VMとコンテナの一括シャットダウン」と出力されるのだが、仮想マシンの停止が実行されなかった。
3.11.3. Bulk Guest Power Management を見ると止まっても良さそうなんだけど・・・
pvesh コマンドを調べるとこちらでも停止させることができる模様なので下記で実施
for hostname in `pvesh ls /nodes/|awk '{ print $2 }'`; do for vmid in `pvesh ls /nodes/$hostname/qemu/|awk '{ print $2 }'`; do pvesh create /nodes/$hostname/qemu/$vmid/status/shutdown; done; done
実行例
root@pve36:~# for hostname in `pvesh ls /nodes/|awk '{ print $2 }'`
> do for vmid in `pvesh ls /nodes/$hostname/qemu/|awk '{ print $2 }'`
> do
> pvesh create /nodes/$hostname/qemu/$vmid/status/shutdown
> done
> done
VM 102 not running
Requesting HA stop for VM 102
UPID:pve36:00014A47:0018FC0A:6731A591:hastop:102:root@pam:
VM 100 not running
Requesting HA stop for VM 100"UPID:pve37:00013A71:0018FDDC:6731A597:hastop:100:root@pam:"
VM 101 not running
Requesting HA stop for VM 101"UPID:pve38:000144BF:00192F03:6731A59D:hastop:101:root@pam:"
Requesting HA stop for VM 103"UPID:pve38:000144DC:0019305D:6731A5A0:hastop:103:root@pam:"
root@pve36:~#
これで、停止することを確認
次に仮想マシンの停止確認
root@pve36:~# pvesh get /nodes/pve36/qemu
lqqqqqqqqqwqqqqqqwqqqqqqwqqqqqqwqqqqqqqqqqqwqqqqqqqqqqwqqqqqqqqqwqqqqqwqqqqqqqqqqqwqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqwqqqqqqwqqqqqqqqk
x status x vmid x cpus x lock x maxdisk x maxmem x name x pid x qmpstatus x running-machine x running-qemu x tags x uptime x
tqqqqqqqqqnqqqqqqnqqqqqqnqqqqqqnqqqqqqqqqqqnqqqqqqqqqqnqqqqqqqqqnqqqqqnqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqu
x stopped x 102 x 2 x x 32.00 GiB x 2.00 GiB x testvm2 x x x x x x 0s x
mqqqqqqqqqvqqqqqqvqqqqqqvqqqqqqvqqqqqqqqqqqvqqqqqqqqqqvqqqqqqqqqvqqqqqvqqqqqqqqqqqvqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqvqqqqqqvqqqqqqqqj
root@pve36:~#
ヘッダーを付けない形式で出力
root@pve36:~# pvesh get /nodes/pve36/qemu --noborder --noheader
stopped 102 2 32.00 GiB 2.00 GiB testvm2 0s
root@pve36:~#
“stopped” となってない行があればまだ停止していない、ということになるので「pvesh get /nodes/pve36/qemu –noborder –noheader|grep -v “stopped”」の出力結果があるかどうかで判断できそう
また、これらはqemu仮想マシンについてのみなので、lxcコンテナについては含まれないので、そちらについても対応する
停止
for hostname in `pvesh ls /nodes/|awk '{ print $2 }'`; do for vmid in `pvesh ls /nodes/$hostname/lxc/|awk '{ print $2 }'`; do pvesh create /nodes/$hostname/lxc/$vmid/status/shutdown;done;done
仮想マシンが止まったかを判断するには、すべての仮想マシンの状態が”stopped”になっているか、で判定するなら下記
for hostname in `pvesh ls /nodes/|awk '{ print $2 }'`; do echo "=== $hostname ==="; flag=0; while [ $flag -eq 0 ]; do pvesh get /nodes/$hostname/qemu --noborder --noheader|grep -v "stopped" > /dev/null; flag=$?; echo $flag; done; done
すべての仮想マシンの状態で”running”がないことなら
for hostname in pvesh ls /nodes/|awk '{ print $2 }'; do echo “=== $hostname ===”; flag=0; while [ $flag -eq 0 ]; do pvesh get /nodes/$hostname/qemu –noborder –noheader|grep “running” > /dev/null ; flag=$?; echo $flag; done; done
どっちがいいかは悩むところ
Cephの停止についてはRedHatの「2.10. Red Hat Ceph Storage クラスターの電源をオフにして再起動」とProxmoxの「Shutdown Proxmox VE + Ceph HCI cluster 」を確認
Proxmox VE側だと下記だけ
ceph osd set noout
ceph osd set norecover
ceph osd set norebalance
ceph osd set nobackfill
ceph osd set nodown
ceph osd set pause
RedHat側にはこれらを実行する前にcephfsを停止するための手順が追加されている。
ceph fs set FS_NAME max_mds 1
ceph mds deactivate FS_NAME:1 # rank 2 of 2
ceph status # wait for rank 1 to finish stopping
ceph fs set FS_NAME cluster_down true
ceph mds fail FS_NAME:0
ceph fs setで設定しているmax_mdsとcluster_downの値はどうなっているのかを確認
root@pve36:~# ceph fs get cephfs
Filesystem 'cephfs' (1)
fs_name cephfs
epoch 65
flags 12 joinable allow_snaps allow_multimds_snaps
created 2024-11-05T14:29:45.941671+0900
modified 2024-11-11T11:04:06.223151+0900
tableserver 0
root 0
session_timeout 60
session_autoclose 300
max_file_size 1099511627776
max_xattr_size 65536
required_client_features {}
last_failure 0
last_failure_osd_epoch 3508
compat compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,7=mds uses inline data,8=no anchor table,9=file layout v2,10=snaprealm v2}
max_mds 1
in 0
up {0=784113}
failed
damaged
stopped
data_pools [3]
metadata_pool 4
inline_data disabled
balancer
bal_rank_mask -1
standby_count_wanted 1
[mds.pve36{0:784113} state up:active seq 29 addr [v2:172.17.44.36:6800/1472122357,v1:172.17.44.36:6801/1472122357] compat {c=[1],r=[1],i=[7ff]}]
root@pve36:~#
cluster_downはない?
root@pve36:~# ceph mds stat
cephfs:1 {0=pve36=up:active} 1 up:standby
root@pve36:~# ceph mds compat show
compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,8=no anchor table,9=file layout v2,10=snaprealm v2}
root@pve36:~#
んー? ceph fsのcluster_down を実行してみる
root@pve36:~# ceph fs set cephfs cluster_down true
cephfs marked not joinable; MDS cannot join as newly active. WARNING: cluster_down flag is deprecated and will be removed in a future version. Please use "joinable".
root@pve36:~#
joinableを使えとあるので、この記述は古いらしい
おや?と思って再度探したところRedHatのドキュメントが古かった。RedHat「2.5. Red Hat Ceph Storage クラスターの電源をオフにして再起動」、もしくはIBMの「Ceph File System ・クラスターの停止」
ceph fs set FS_NAME max_mds 1
ceph fs fail FS_NAME
ceph status
ceph fs set FS_NAME joinable false
IBM手順の方だとmax_mdsの操作は行わずに実施している
root@pve36:~# ceph fs status
cephfs - 4 clients
======
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active pve36 Reqs: 0 /s 21 20 16 23
POOL TYPE USED AVAIL
cephfs_metadata metadata 244M 122G
cephfs_data data 31.8G 122G
STANDBY MDS
pve37
MDS version: ceph version 18.2.4 (2064df84afc61c7e63928121bfdd74c59453c893) reef (stable)
root@pve36:~# ceph fs fail cephfs
cephfs marked not joinable; MDS cannot join the cluster. All MDS ranks marked failed.
root@pve36:~# ceph fs status
cephfs - 0 clients
======
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 failed
POOL TYPE USED AVAIL
cephfs_metadata metadata 244M 122G
cephfs_data data 31.8G 122G
STANDBY MDS
pve37
pve36
MDS version: ceph version 18.2.4 (2064df84afc61c7e63928121bfdd74c59453c893) reef (stable)
root@pve36:~# ceph fs fail cephfs
cephfs marked not joinable; MDS cannot join the cluster. All MDS ranks marked failed.
root@pve36:~# echo $?
0
root@pve36:~# ceph fs set cephfs joinable false
cephfs marked not joinable; MDS cannot join as newly active.
root@pve36:~# echo $?
0
root@pve36:~# ceph fs status
cephfs - 0 clients
======
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 failed
POOL TYPE USED AVAIL
cephfs_metadata metadata 244M 122G
cephfs_data data 31.8G 122G
STANDBY MDS
pve37
pve36
MDS version: ceph version 18.2.4 (2064df84afc61c7e63928121bfdd74c59453c893) reef (stable)
root@pve36:~#
…止めてしまったら、dfコマンドが実行できなくなるので注意
root@pve36:~# ceph osd stat
16 osds: 16 up (since 6h), 16 in (since 3d); epoch: e3599
root@pve36:~# ceph osd set noout
noout is set
root@pve36:~# ceph osd set norecover
norecover is set
root@pve36:~# ceph osd set norebalance
norebalance is set
root@pve36:~# ceph osd set nobackfill
nobackfill is set
root@pve36:~# ceph osd set nodown
nodown is set
root@pve36:~# ceph osd set pause
pauserd,pausewr is set
root@pve36:~# ceph osd stat
16 osds: 16 up (since 6h), 16 in (since 3d); epoch: e3605
flags pauserd,pausewr,nodown,noout,nobackfill,norebalance,norecover
root@pve36:~#
ドキュメントに「重要 上記の例は、OSD ノード内のサービスと各 OSD を停止する場合のみであり、各 OSD ノードで繰り返す必要があります。」とあるので、各サーバで確認してみたが、別に各サーバで実行する必要はなさそうである。
root@pve36:~# ceph osd stat
16 osds: 16 up (since 6h), 16 in (since 3d); epoch: e3605
flags pauserd,pausewr,nodown,noout,nobackfill,norebalance,norecover
root@pve36:~# ssh pve37 ceph osd stat
16 osds: 16 up (since 6h), 16 in (since 3d); epoch: e3605
flags pauserd,pausewr,nodown,noout,nobackfill,norebalance,norecover
root@pve36:~# ssh pve38 ceph osd stat
16 osds: 16 up (since 6h), 16 in (since 3d); epoch: e3605
flags pauserd,pausewr,nodown,noout,nobackfill,norebalance,norecover
root@pve36:~# ssh pve39 ceph osd stat
16 osds: 16 up (since 6h), 16 in (since 3d); epoch: e3605
flags pauserd,pausewr,nodown,noout,nobackfill,norebalance,norecover
root@pve36:~#
このあと、各サーバに対してshutdown -h nowを実行して止めた
起動後
root@pve36:~# ceph status
cluster:
id: 4647497d-17da-46f4-8e7b-231365d96e42
health: HEALTH_ERR
1 filesystem is degraded
1 filesystem is offline
pauserd,pausewr,nodown,noout,nobackfill,norebalance,norecover flag(s) set
services:
mon: 3 daemons, quorum pve36,pve37,pve38 (age 41s)
mgr: pve38(active, since 30s), standbys: pve37, pve36
mds: 0/1 daemons up (1 failed), 2 standby
osd: 16 osds: 16 up (since 48s), 16 in (since 3d)
flags pauserd,pausewr,nodown,noout,nobackfill,norebalance,norecover
data:
volumes: 0/1 healthy, 1 failed
pools: 4 pools, 193 pgs
objects: 17.68k objects, 69 GiB
usage: 206 GiB used, 434 GiB / 640 GiB avail
pgs: 193 active+clean
root@pve36:~# ceph osd stat
16 osds: 16 up (since 69s), 16 in (since 3d); epoch: e3621
flags pauserd,pausewr,nodown,noout,nobackfill,norebalance,norecover
root@pve36:~#
root@pve36:~# ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
root@pve36:~# ceph fs status
cephfs - 0 clients
======
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 failed
POOL TYPE USED AVAIL
cephfs_metadata metadata 244M 125G
cephfs_data data 31.8G 125G
STANDBY MDS
pve37
pve36
MDS version: ceph version 18.2.4 (2064df84afc61c7e63928121bfdd74c59453c893) reef (stable)
root@pve36:~#
復帰のためのコマンド群1
root@pve36:~# ceph osd unset noout
noout is unset
root@pve36:~# ceph osd unset norecover
norecover is unset
root@pve36:~# ceph osd unset norebalance
norebalance is unset
root@pve36:~# ceph osd unset nobackfill
nobackfill is unset
root@pve36:~# ceph osd unset nodown
nodown is unset
root@pve36:~# ceph osd unset pause
pauserd,pausewr is unset
root@pve36:~# ceph osd stat
16 osds: 16 up (since 100s), 16 in (since 3d); epoch: e3627
root@pve36:~# ceph status
cluster:
id: 4647497d-17da-46f4-8e7b-231365d96e42
health: HEALTH_ERR
1 filesystem is degraded
1 filesystem is offline
services:
mon: 3 daemons, quorum pve36,pve37,pve38 (age 102s)
mgr: pve38(active, since 90s), standbys: pve37, pve36
mds: 0/1 daemons up (1 failed), 2 standby
osd: 16 osds: 16 up (since 108s), 16 in (since 3d)
data:
volumes: 0/1 healthy, 1 failed
pools: 4 pools, 193 pgs
objects: 17.68k objects, 69 GiB
usage: 206 GiB used, 434 GiB / 640 GiB avail
pgs: 193 active+clean
io:
client: 21 KiB/s rd, 0 B/s wr, 9 op/s rd, 1 op/s wr
root@pve36:~#
ファイルシステム再開
root@pve36:~# ceph fs set cephfs joinable true
cephfs marked joinable; MDS may join as newly active.
root@pve36:~# ceph fs status
cephfs - 4 clients
======
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 reconnect pve36 10 10 6 0
POOL TYPE USED AVAIL
cephfs_metadata metadata 244M 125G
cephfs_data data 31.8G 125G
STANDBY MDS
pve37
MDS version: ceph version 18.2.4 (2064df84afc61c7e63928121bfdd74c59453c893) reef (stable)
root@pve36:~# ceph osd stat
16 osds: 16 up (since 2m), 16 in (since 3d); epoch: e3627
root@pve36:~# cpeh status
-bash: cpeh: command not found
root@pve36:~# ceph status
cluster:
id: 4647497d-17da-46f4-8e7b-231365d96e42
health: HEALTH_WARN
1 filesystem is degraded
services:
mon: 3 daemons, quorum pve36,pve37,pve38 (age 2m)
mgr: pve38(active, since 2m), standbys: pve37, pve36
mds: 1/1 daemons up, 1 standby
osd: 16 osds: 16 up (since 2m), 16 in (since 3d)
data:
volumes: 0/1 healthy, 1 recovering
pools: 4 pools, 193 pgs
objects: 17.68k objects, 69 GiB
usage: 206 GiB used, 434 GiB / 640 GiB avail
pgs: 193 active+clean
root@pve36:~#
root@pve36:~# ceph fs status
cephfs - 4 clients
======
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 rejoin pve36 10 10 6 0
POOL TYPE USED AVAIL
cephfs_metadata metadata 244M 125G
cephfs_data data 31.8G 125G
STANDBY MDS
pve37
MDS version: ceph version 18.2.4 (2064df84afc61c7e63928121bfdd74c59453c893) reef (stable)
root@pve36:~# df
Filesystem 1K-blocks Used Available Use% Mounted on
udev 8156156 0 8156156 0% /dev
tmpfs 1638000 1124 1636876 1% /run
/dev/mapper/pve-root 28074060 14841988 11780656 56% /
tmpfs 8189984 73728 8116256 1% /dev/shm
tmpfs 5120 0 5120 0% /run/lock
/dev/fuse 131072 36 131036 1% /etc/pve
tmpfs 8189984 28 8189956 1% /var/lib/ceph/osd/ceph-2
tmpfs 8189984 28 8189956 1% /var/lib/ceph/osd/ceph-0
tmpfs 8189984 28 8189956 1% /var/lib/ceph/osd/ceph-1
tmpfs 8189984 28 8189956 1% /var/lib/ceph/osd/ceph-3
tmpfs 1637996 0 1637996 0% /run/user/0
root@pve36:~# ceph fs status
cephfs - 0 clients
======
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active pve36 Reqs: 0 /s 10 10 6 0
POOL TYPE USED AVAIL
cephfs_metadata metadata 244M 125G
cephfs_data data 31.8G 125G
STANDBY MDS
pve37
MDS version: ceph version 18.2.4 (2064df84afc61c7e63928121bfdd74c59453c893) reef (stable)
root@pve36:~# df
Filesystem 1K-blocks Used Available Use% Mounted on
udev 8156156 0 8156156 0% /dev
tmpfs 1638000 1128 1636872 1% /run
/dev/mapper/pve-root 28074060 14841992 11780652 56% /
tmpfs 8189984 73728 8116256 1% /dev/shm
tmpfs 5120 0 5120 0% /run/lock
/dev/fuse 131072 36 131036 1% /etc/pve
tmpfs 8189984 28 8189956 1% /var/lib/ceph/osd/ceph-2
tmpfs 8189984 28 8189956 1% /var/lib/ceph/osd/ceph-0
tmpfs 8189984 28 8189956 1% /var/lib/ceph/osd/ceph-1
tmpfs 8189984 28 8189956 1% /var/lib/ceph/osd/ceph-3
tmpfs 1637996 0 1637996 0% /run/user/0
172.17.44.36,172.17.44.37,172.17.44.38:/ 142516224 11116544 131399680 8% /mnt/pve/cephfs
root@pve36:~#
ただ、これだと通常のPVE起動プロセスで実行される「VMとコンテナの一括起動」で仮想マシンが実行されなかった。おや?と思ったら、設定が変わってた
root@pve36:~# ha-manager status
quorum OK
master pve39 (active, Mon Nov 11 18:24:13 2024)
lrm pve36 (idle, Mon Nov 11 18:24:15 2024)
lrm pve37 (idle, Mon Nov 11 18:24:18 2024)
lrm pve38 (idle, Mon Nov 11 18:24:18 2024)
lrm pve39 (idle, Mon Nov 11 18:24:15 2024)
service vm:100 (pve37, stopped)
service vm:101 (pve38, stopped)
service vm:102 (pve36, stopped)
service vm:103 (pve38, stopped)
root@pve36:~# ha-manager config
vm:100
state stopped
vm:101
state stopped
vm:102
state stopped
vm:103
state stopped
root@pve36:~#