AmazonでTRIGKEYのミニPCが1万円を切ってる、というので買ってみた
15899円になぜか6000円引きのクーポンがついてきて、1万円を切ってるというもの

速やかに到着・・・


なぜか箱をくるんでいるビニールに対して技適 210-173540 というシールが貼れているという・・・

箱の中身はこんな感じ

電源ユニット内蔵なので、謎のType-C形状電源とか不要でコンパクトに使える、というのがとても良いですね

ついでに中身確認

うーん・・・M.2 SATA SSD 256GBが黒いです。

フラッシュチップの記載が何も読めません

メモリにもかかれている「LKY」というのがメーカか何かなんですかね?
起動してみましょう
F2キーでUEFIに入れました。
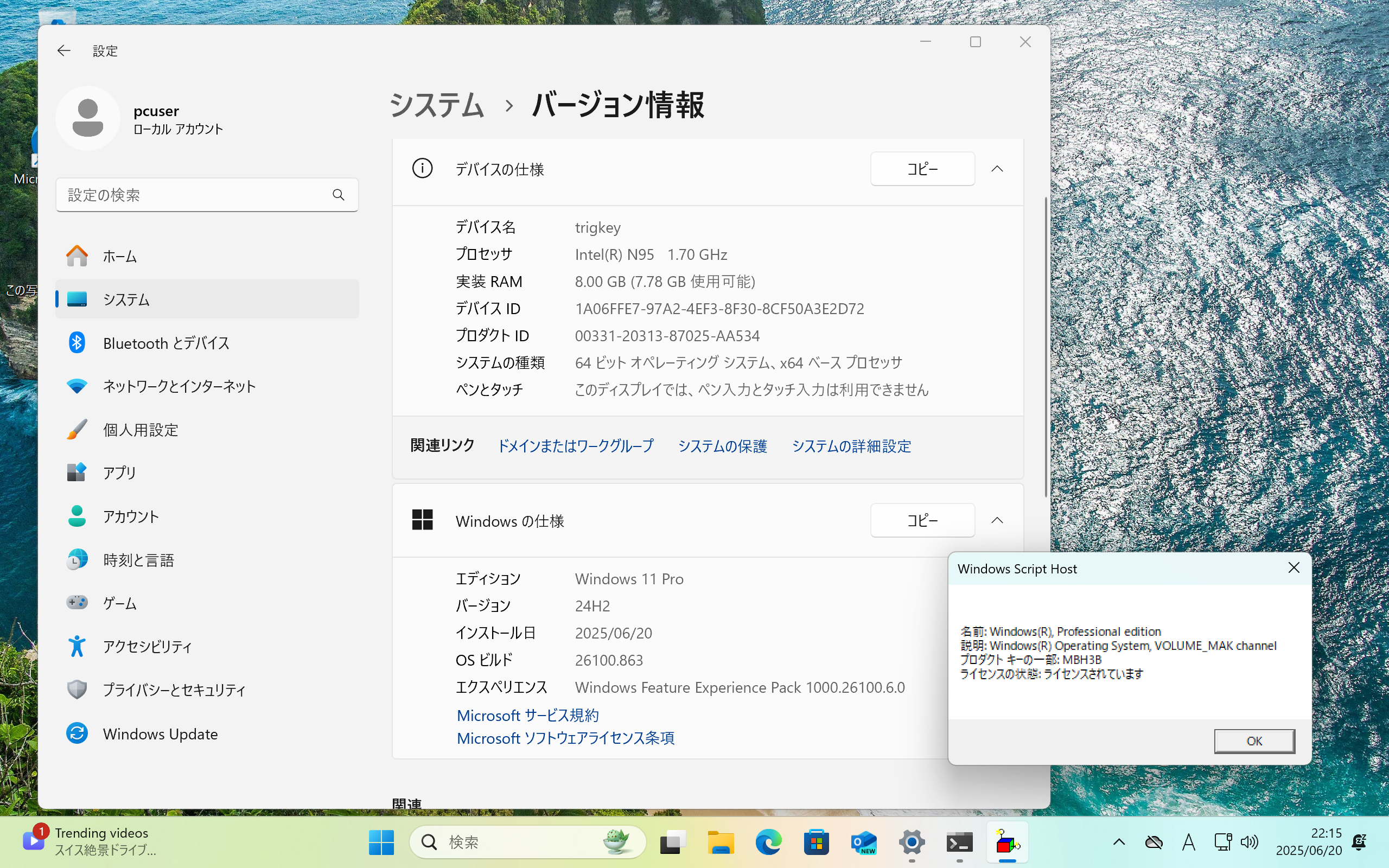
プレインストールのWindows 11 Proのセットアップを進めていって「slmgr /dli」を実行してWindowsのライセンス認識を確認してみます・・・
ライセンスは以下のようにVOLUME_MAKでした
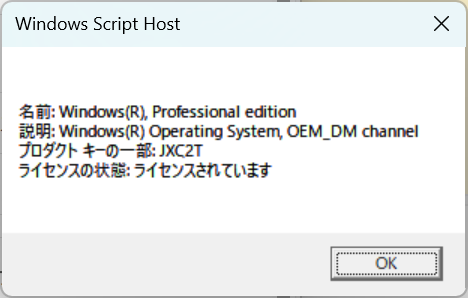
なので、Amazon経由で正式なライセンスをくれ、とメッセージを送ったところ4営業日でライセンスが発行され、適用したところ OEM_DM として認識されることを確認しました。
で・・・実は、なかなかライセンスが来なかったので、ライセンスが届く前にWindowsの再インストールを行ってみたところ予想外の事態が・・・
インストール時にライセンスは自動認識されないので、Windows 11 Proを手動で選択してインストールを終わらせてみたところ、すでにRETAILで認識されていたという・・・
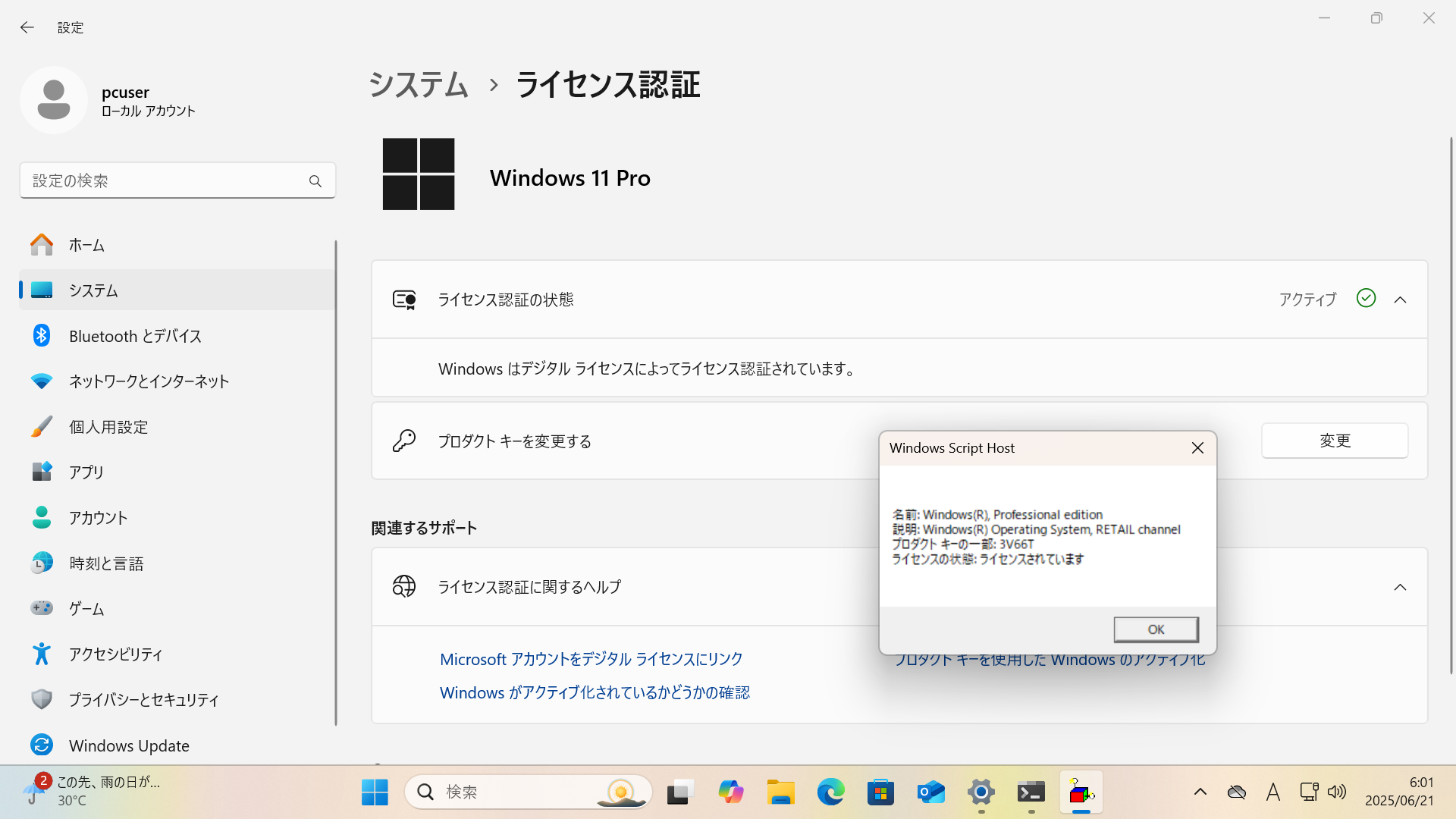
うーん・・・どういう状態なんですかねぇ・・・これ
とりあえずはWindows 11 Pro ライセンスがついてきて1万円を切っていた、というのは変わらないですね。
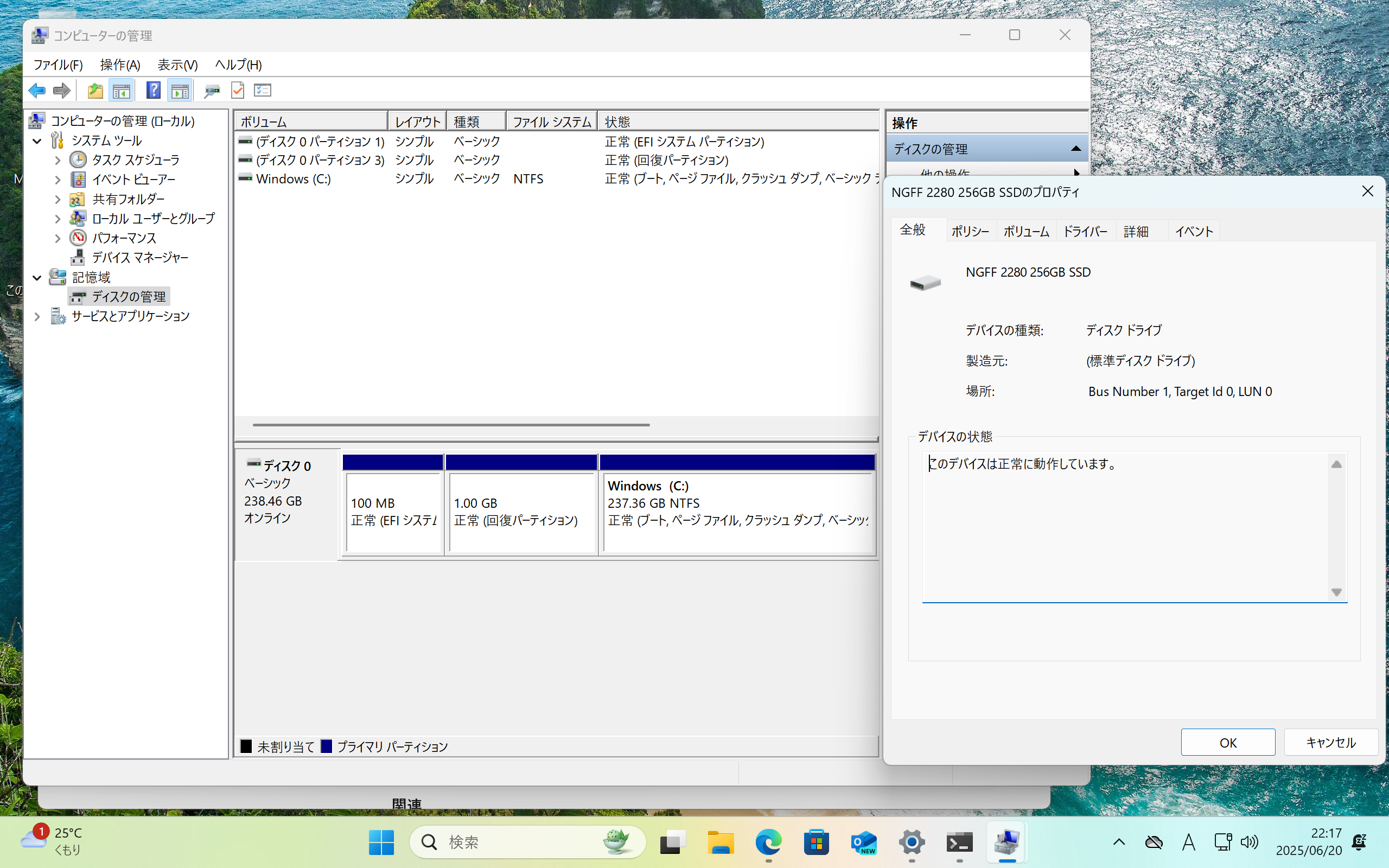
謎の真っ黒M.2 SATA SSDを確認
メーカー名なしで「NGFF 2280 256GB SSD」と認識のもの、というのは驚きです。
(NGFF 2280 は 物理的な形状のことを指している単語です)
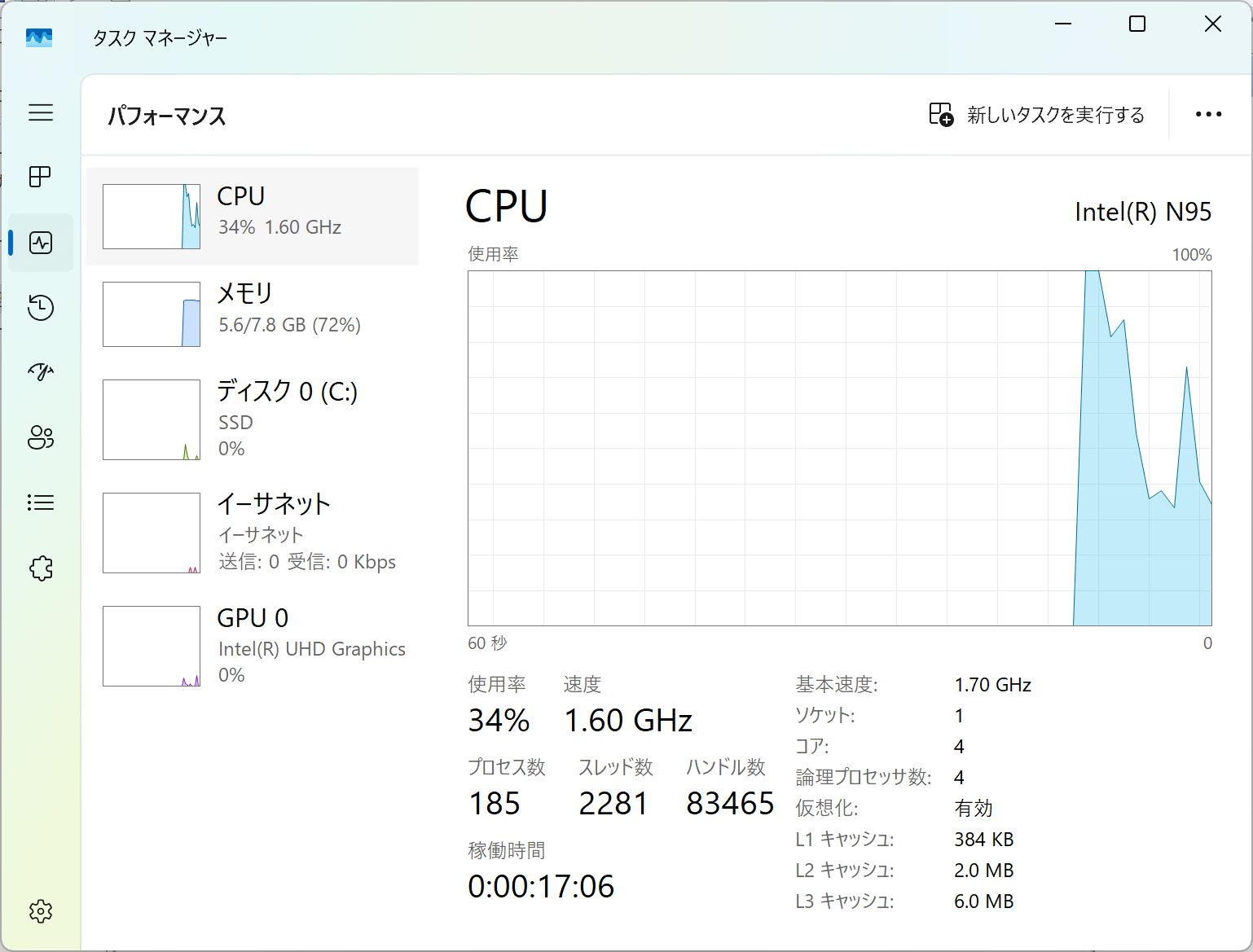
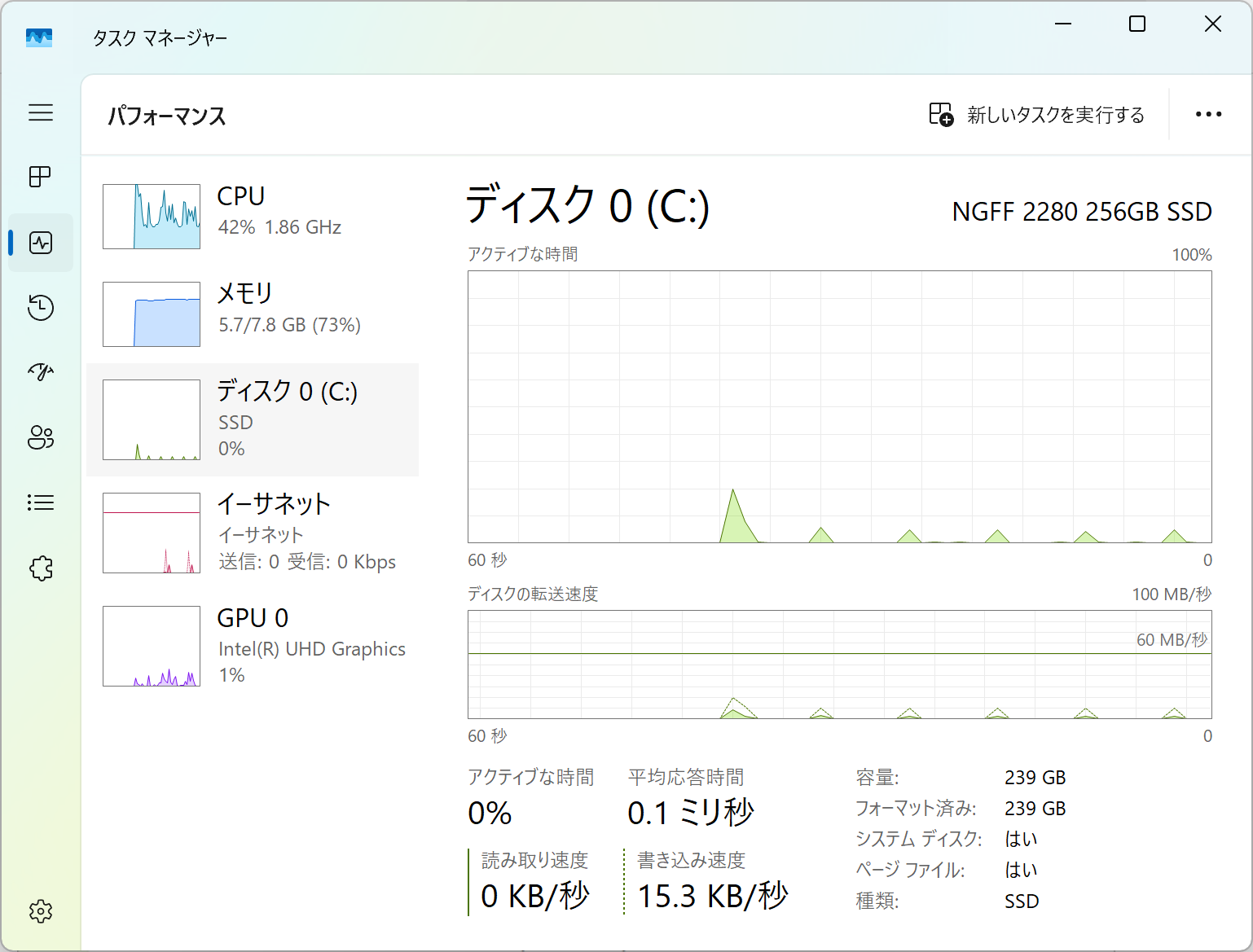
タスクマネージャー上の認識を確認。ちゃんとIntel N95で認識されている、と
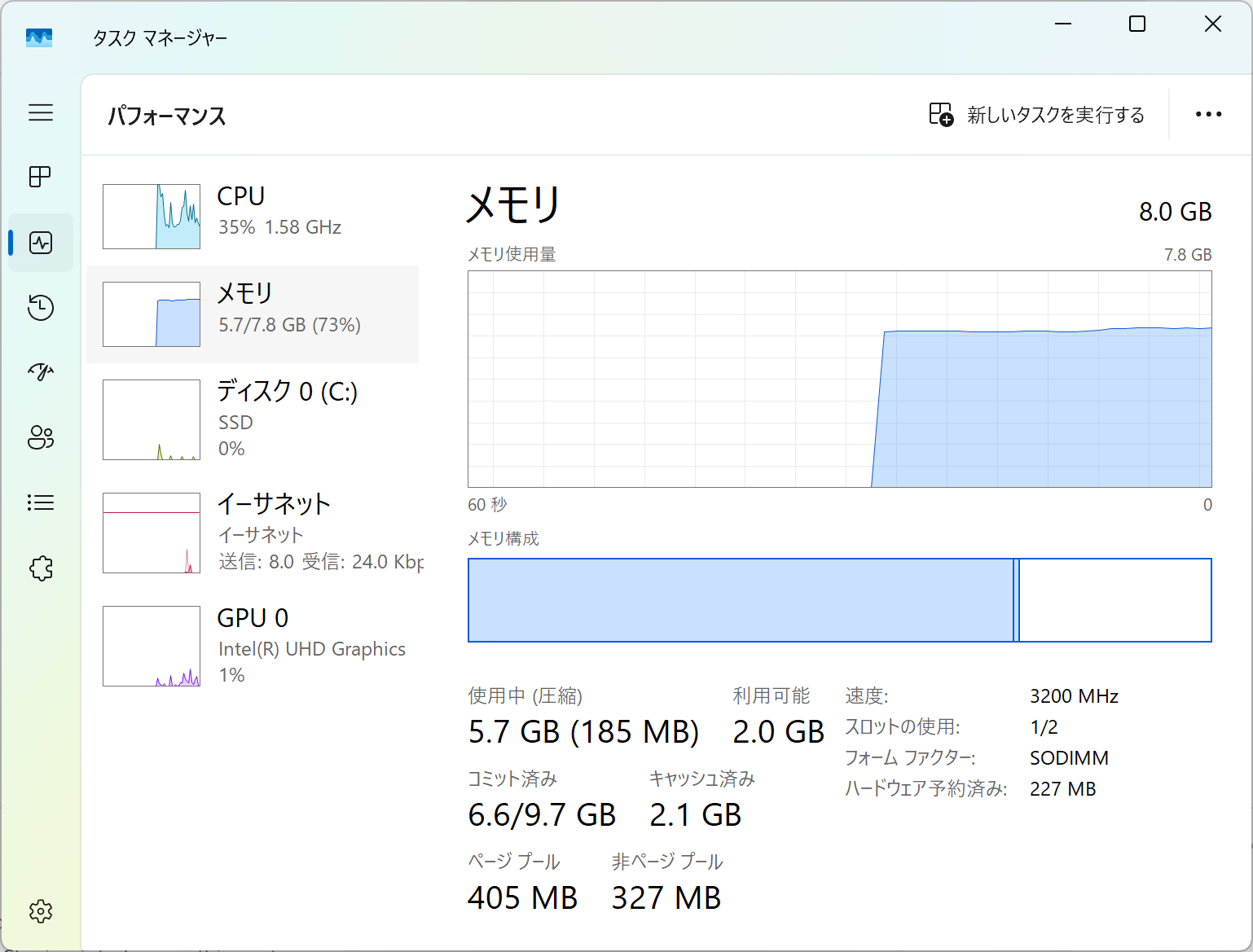
メモリはSO-DIMM DDR4 3200の8GBでした。なお、後述しますが32GBメモリが動作することも確認しました。
ディスクはメーカ、モデル名不詳のNGFF 2280 256GB SSD…まあ、256GBなので捨てちゃいましょう
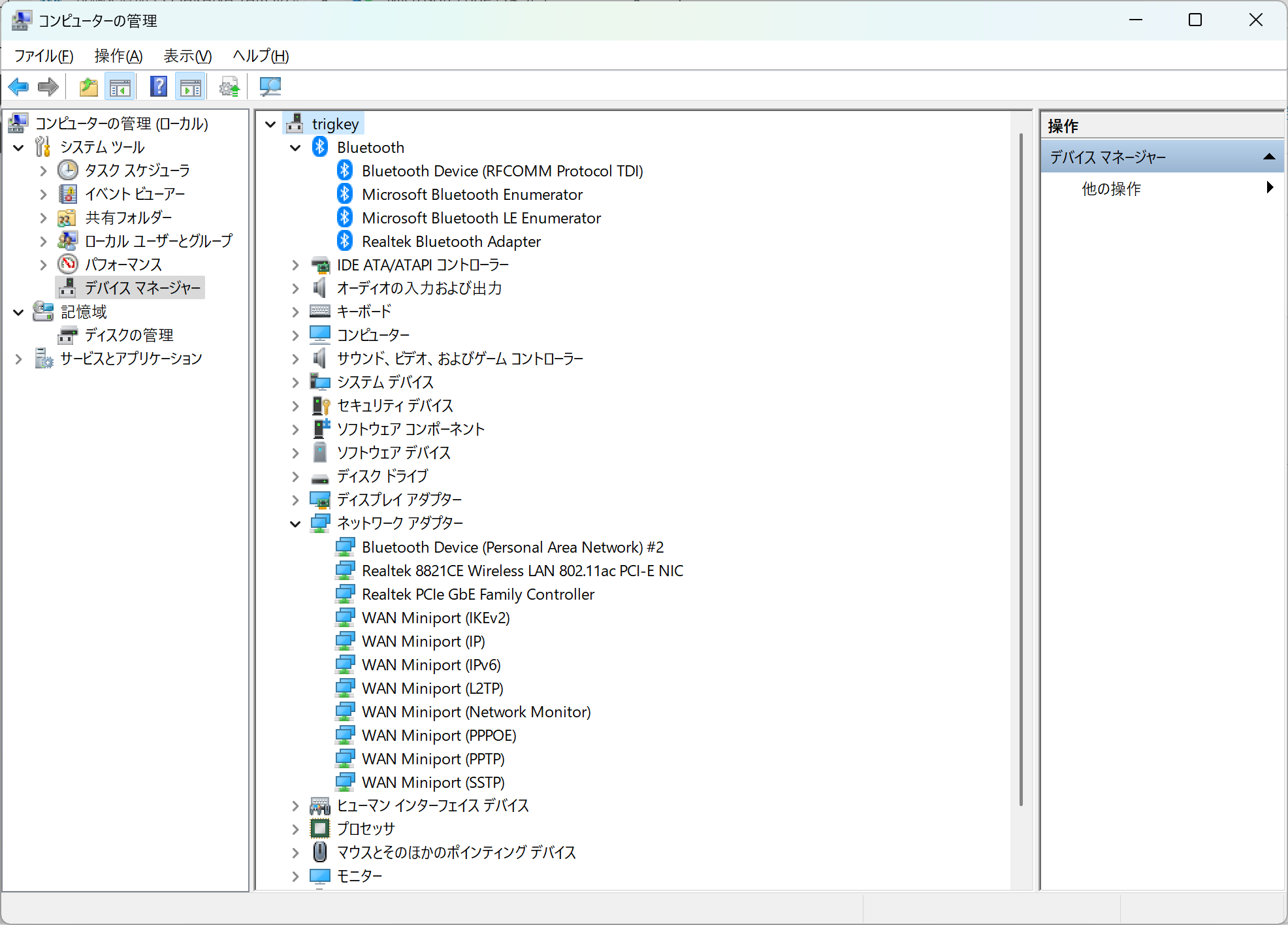
プレインストールのWindows 11 Proのドライバ認識を確認・・・もちろん未認識はなし。
プレインストールソフトについて
標準でインストールされているプログラムをスタートメニューで確認すると、Intel関連がいくつか登録されていた。


次にインストールされているアプリ一覧を確認



このうち「Intel Driver and Support Assistant」がドライバの更新があると教えてくれたので、実行してみるとブラウザが開いた
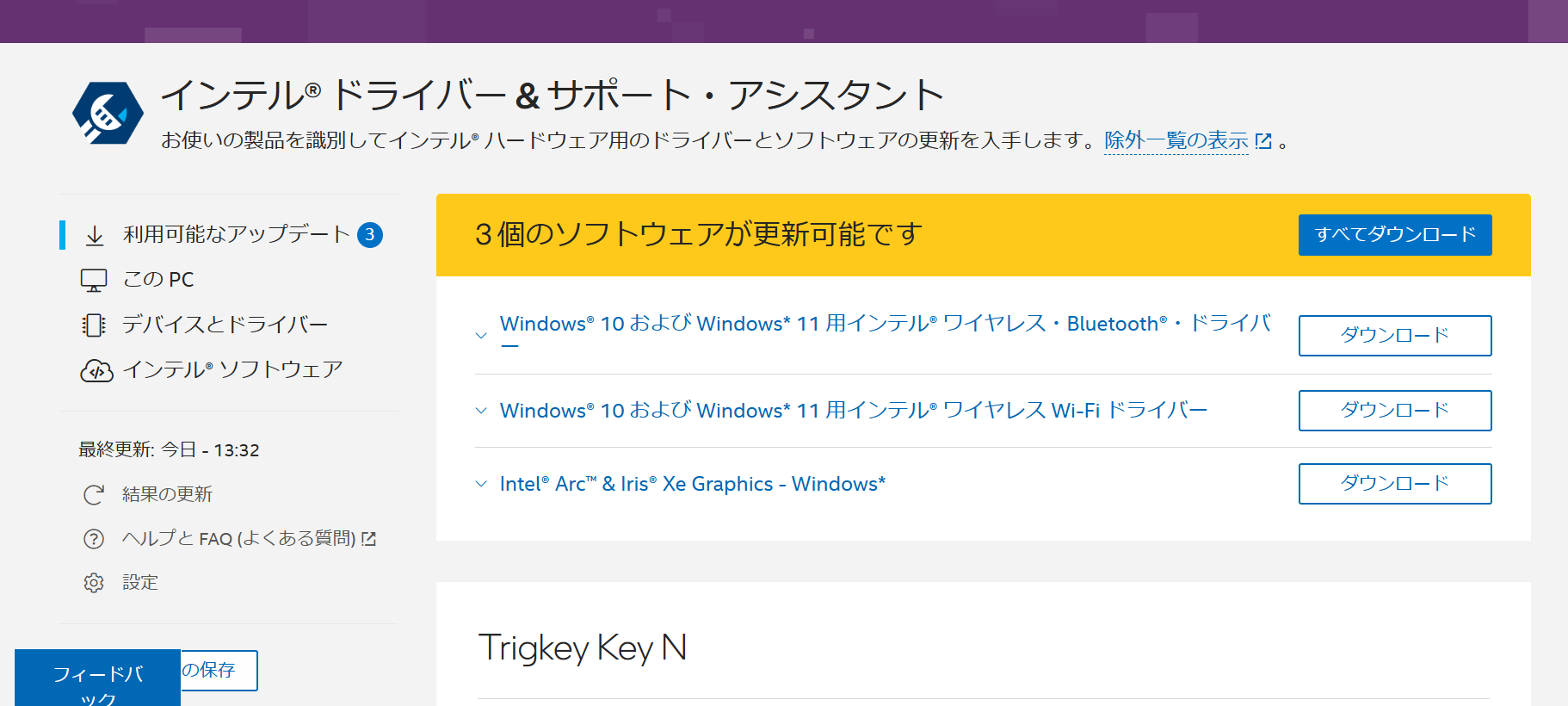
開いたURLはこれ : インテル® ドライバー & サポート・アシスタント
アップデートの詳細説明は下記のURL3つ
Windows® 10 および Windows* 11 用インテル® ワイヤレス Wi-Fi ドライバー
Windows® 10 および Windows* 11 用インテル® ワイヤレス・Bluetooth®・ドライバー
Intel® Arc™ & Iris® Xe Graphics – Windows*
Window 11 再インストール実施
SSDを別のものに交換してWindows 11 Pro を再インストールしてみたところ、標準では一部デバイスが認識していない。
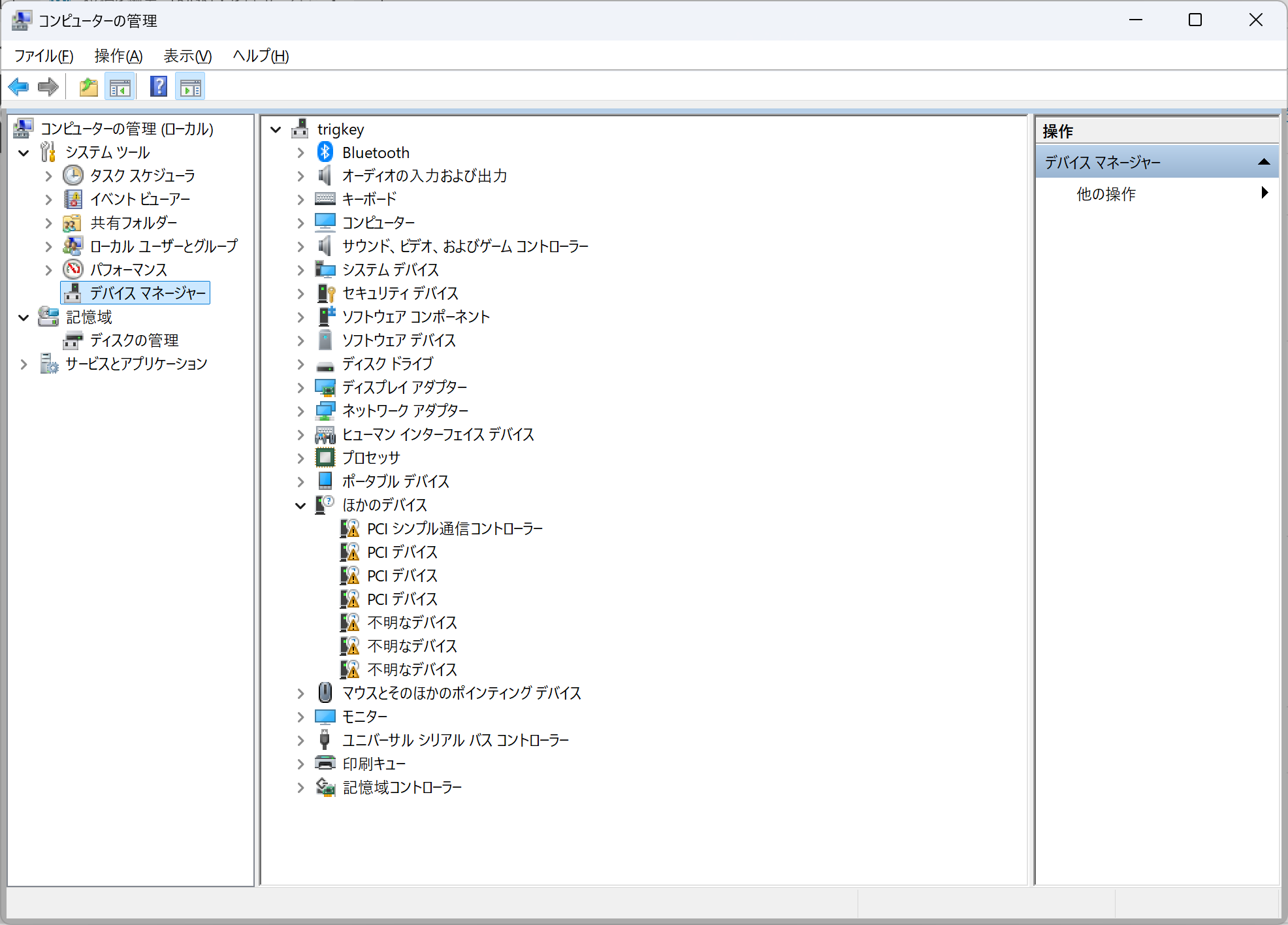
まずは認識していないものを確認しつつドライバを適用
PCI シンプル通信コントローラーPCI\VEN_8086&DEV_54A8&SUBSYS_72708086&REV_00\3&11583659&0&F0
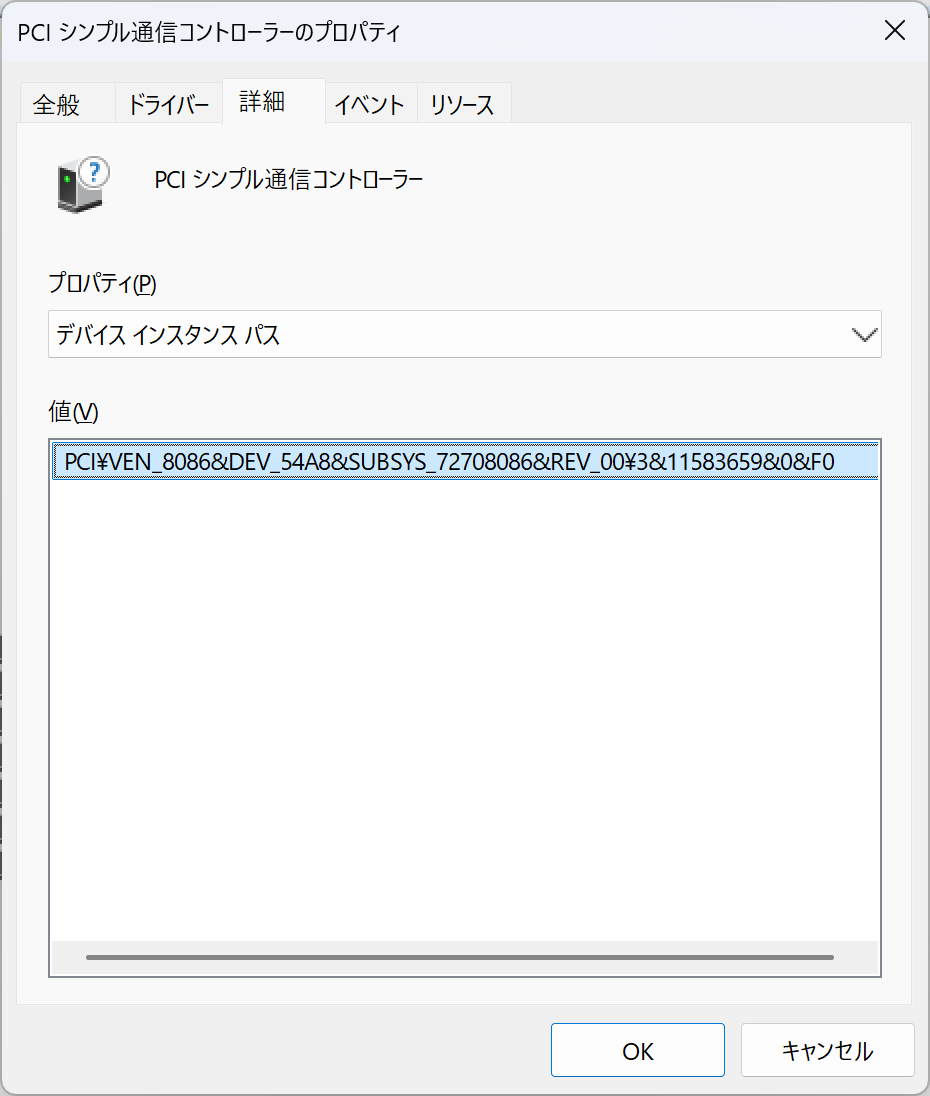
Microsoft Update カタログからドライバ適用
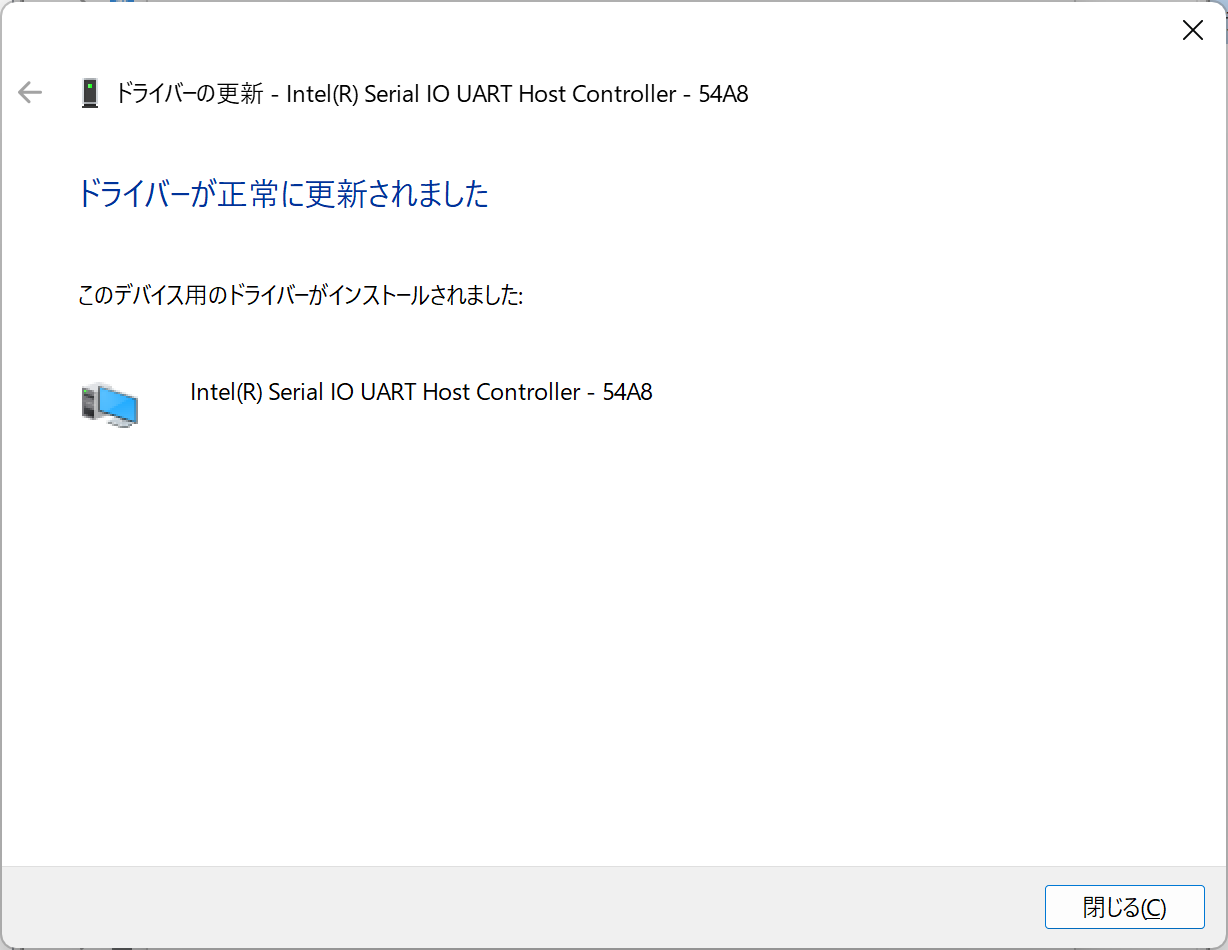
PCI デバイス
PCI\VEN_8086&DEV_54E8&SUBSYS_72708086&REV_00\3&11583659&0&A8
Microsoft Update カタログ からドライバ適用
PCI デバイス
PCI\VEN_8086&DEV_54E9&SUBSYS_72708086&REV_00\3&11583659&0&A9
Microsoft Update カタログのドライバ適用
PCI デバイス
PCI\VEN_8086&DEV_54AB&SUBSYS_72708086&REV_00\3&11583659&0&F3
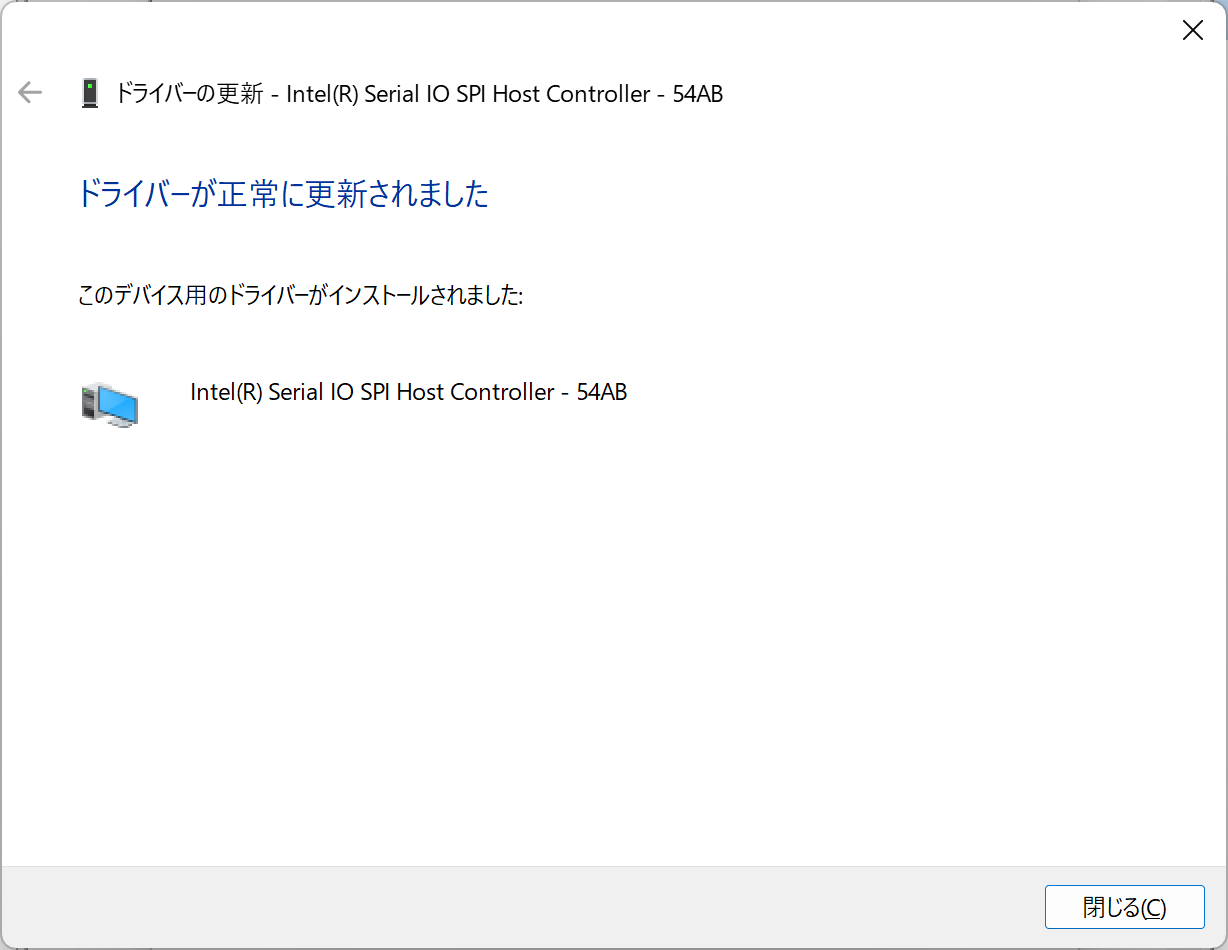
ここからのACPIの不明なデバイス3つを解消するにはMicrosoft Update Catalogで探す前にIntelページからドライバを入手する必要があった。
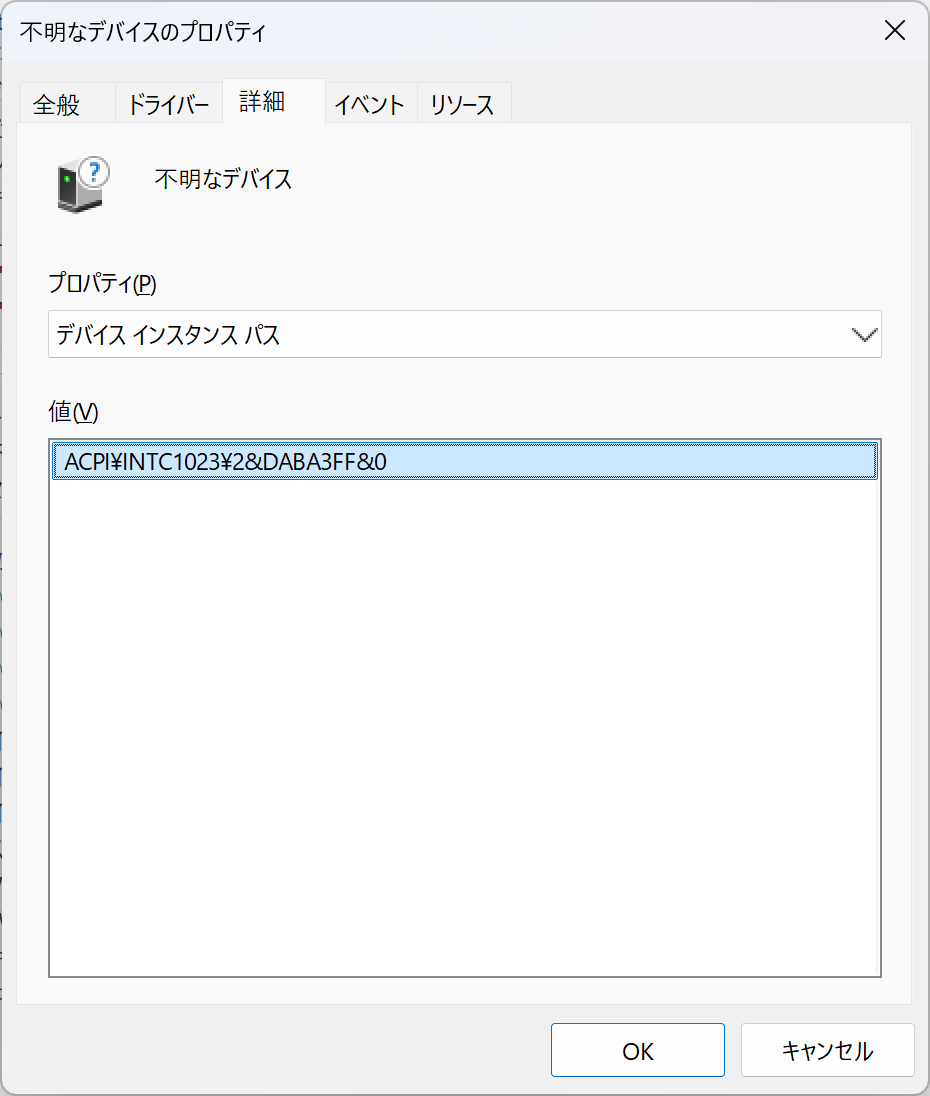
不明なデバイス
ACPI\INTC1023\2&DABA3FF&0
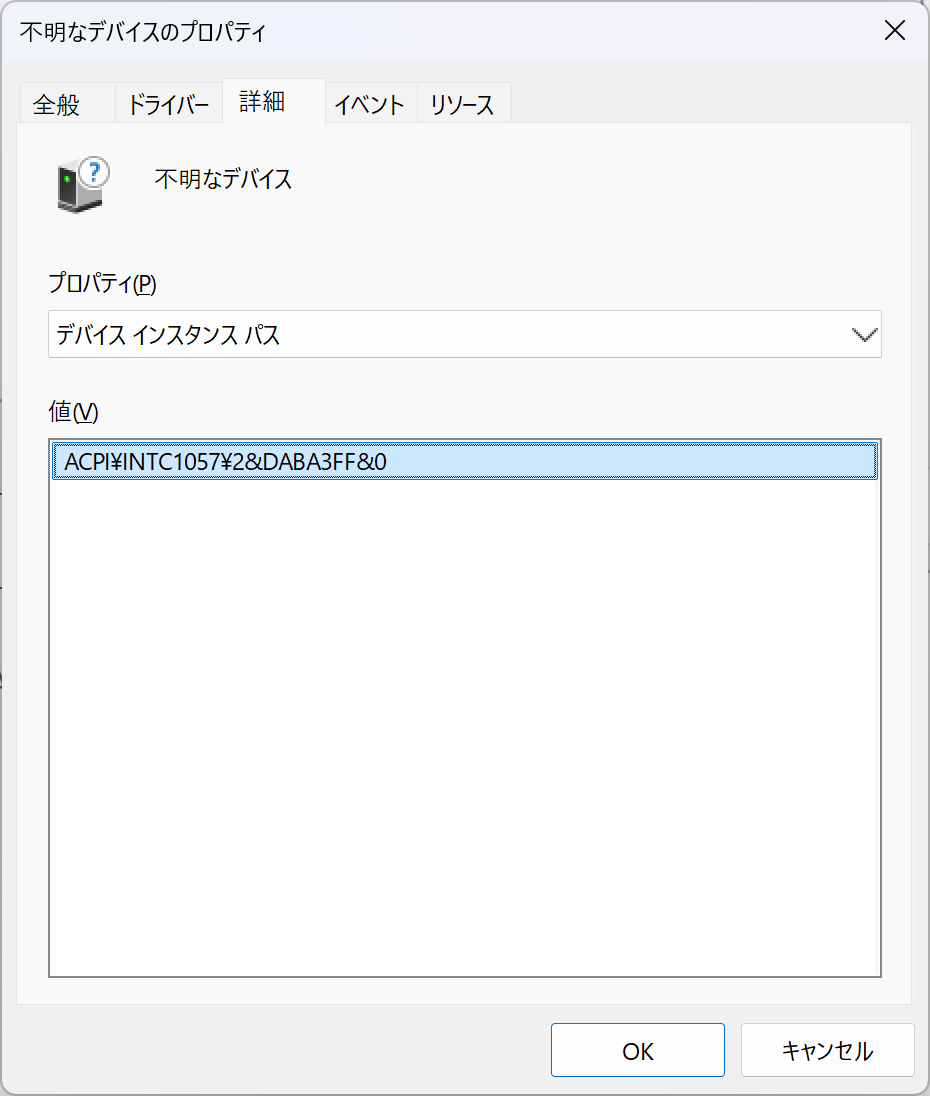
不明なデバイス
ACPI\INTC1057\2&DABA3FF&0
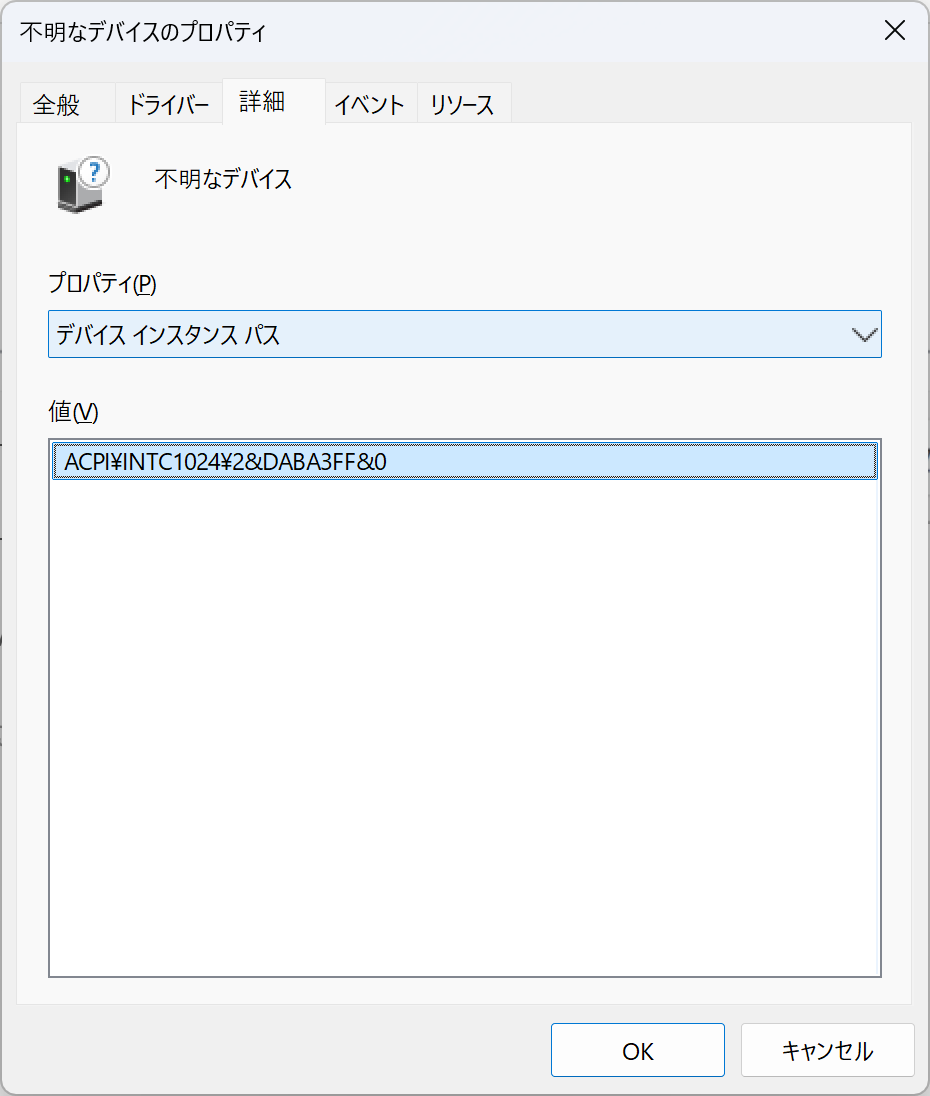
不明なデバイス
ACPI\INTC1024\2&DABA3FF&0
まずは、下記からINFをインストールすると、不明なデバイスが2つ消える。
ユーザーサポート インテル® Chipset Software Installation Utility
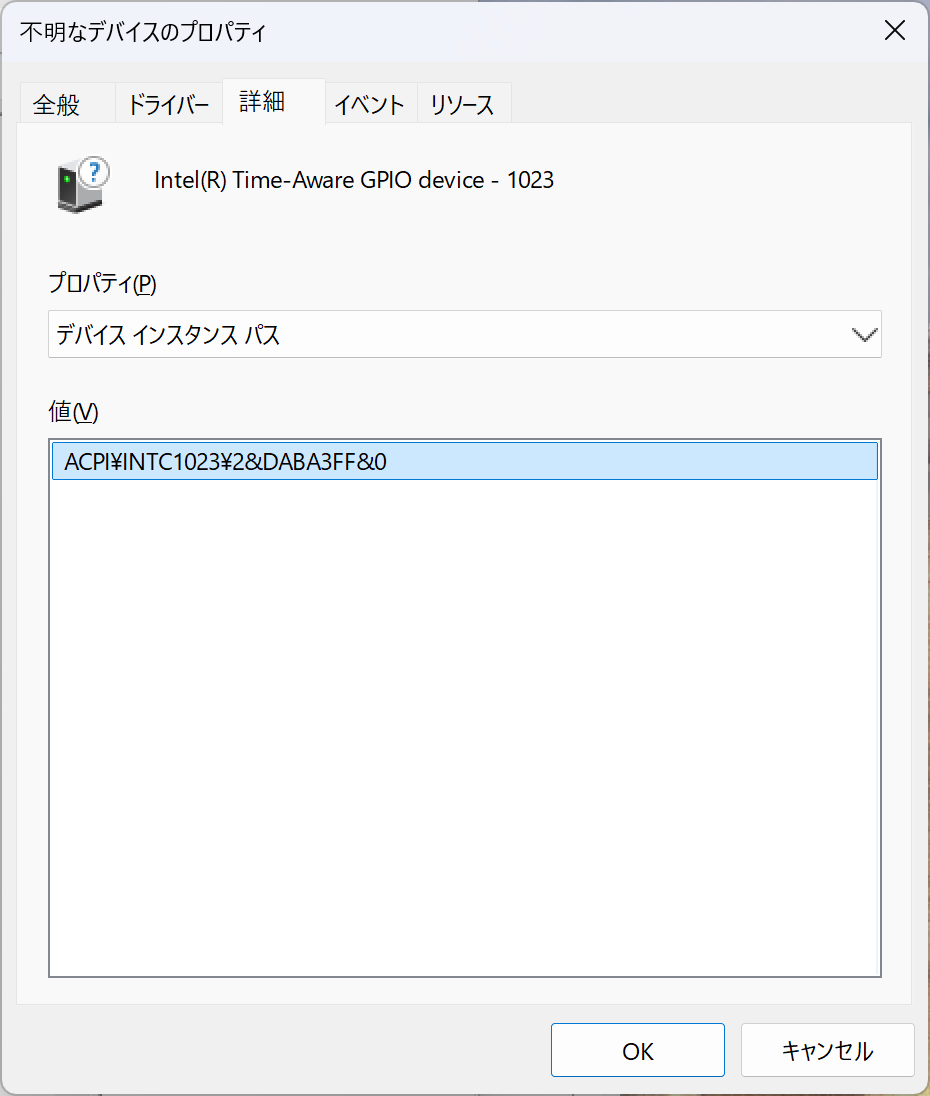
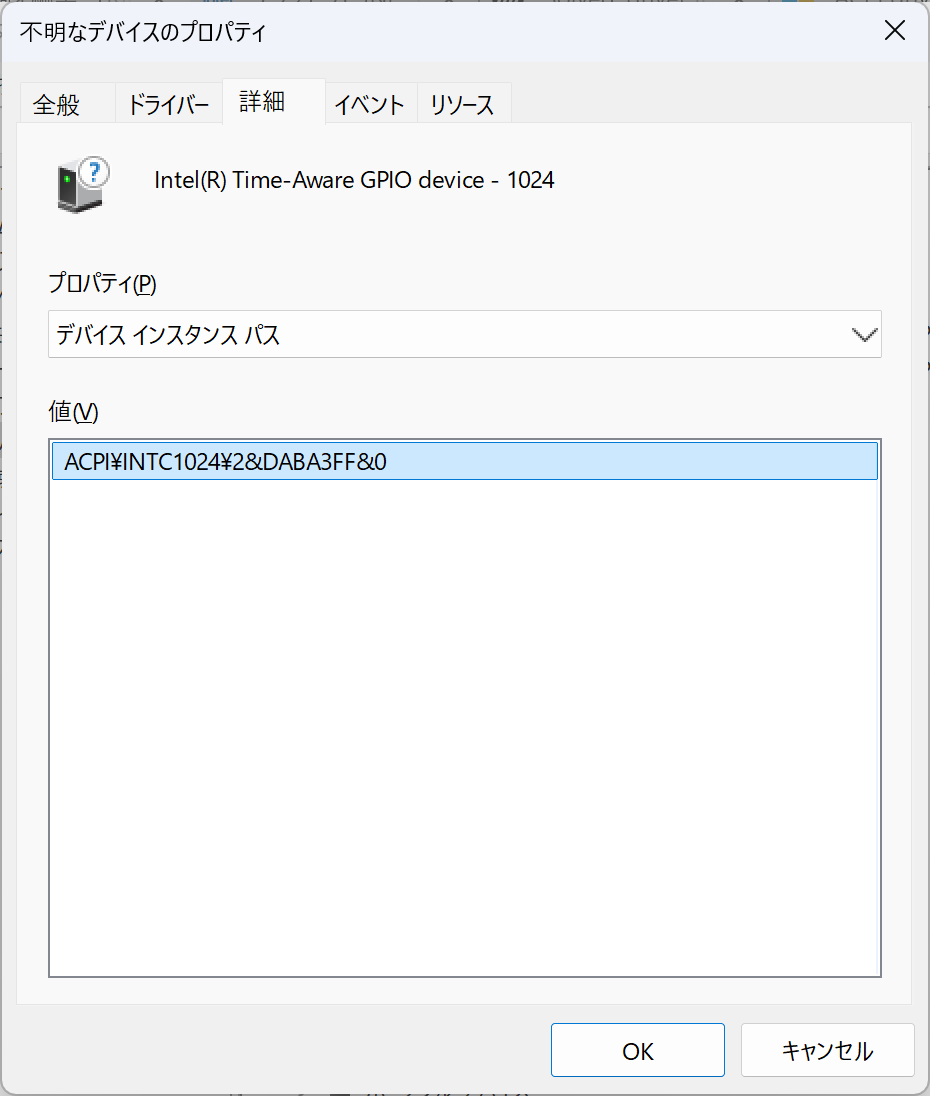
残ったものについてはMicrosoft Update Catalogで捜索する
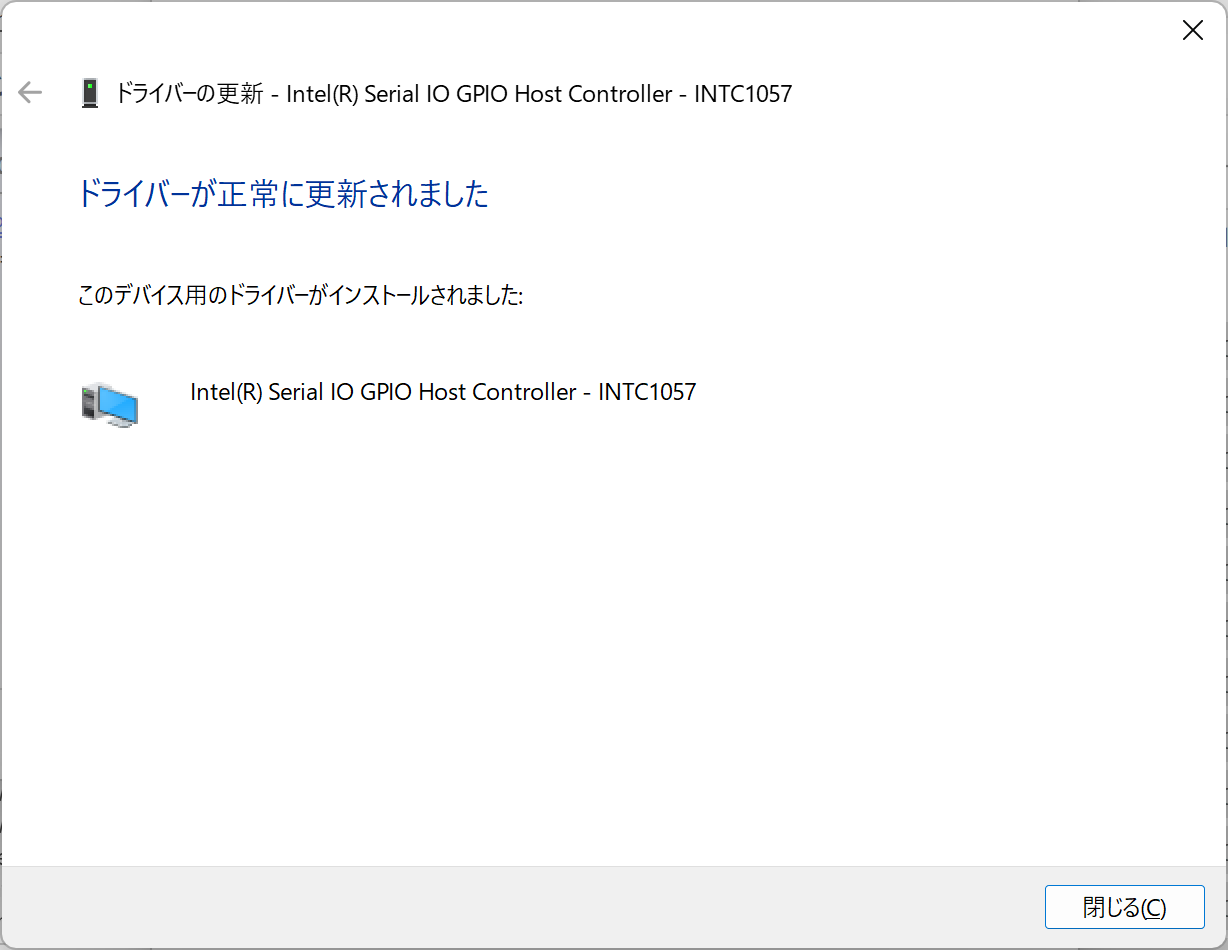
これでデバイスがすべて認識した。
再インストール後にアプリ一覧を比較すると、プレインストールに存在していたが、再インストール後にないもので、システムの動作に影響がありそうなものをあげると以下のものになる。
Intel(R) Arc Software & Drivers
Intel(R) Computing Improvement Program
Intel Arc Control
Intel Driver & Support Assistant
Intel Unison (なお、Unisonの提供は 2025/06で終了済)
Realtek High Definition Audio Driver
インテル グラフィクス・コマンド・センター
インテル シリアル IO
インテル マネージメント・エンジン・コンポーネント
逆に再インストールで追加されているものは以下の2つ。まあ、copilotなので無視。
Copilot
Microsoft 365 Copilot
足らないアプリケーションについて、まずは「インテル® ドライバー & サポート・アシスタント」をインストールして、実行
実行するとWifi/Bluetooth/グラフィックスドライバの更新がインストールされた。
リストを確認すると、更新と同時に”Intel(R) Computing Improvement Program” と “oneAPI Level Zero”がインストールされていた。どちらもGPUコンピューティング関連のソフトウェアと思われる。
プレインストールにあった「Intel ARC Control」は古いバージョンで、現在は Intel Graphics Softwareに統合されたみたいなので不要の模様(単体ではダウンロードできない)
インテル® グラフィックス・コマンド・センターはMicrosoft Storeからインストール
Realtek High Definition Audio Driver, インテル シリアル IO, インテル マネージメント・エンジン・コンポーネントについてはドライバが適用されてるのでわざわざ追加する必要はない。
これで、プレインストール状態と同等になり問題はないと思われる。
カスタマイズ
とりあえず標準で載っていたWifi 802.11ac/Bluetooth 5.0のRTL8821CE は見た目が怪しすぎるしそもそも仕様が古いということでIntel AX210NGW に交換し、WiFi-6E / Bluetooth 5.3 に対応させました。
SSDについては余っていた512GBのM.2 NVMe SSDとM.2 SATA SSDを使ってUbuntu Linuxのソフトウェアミラーリング設定を行って試験運転中です。
さらに、32GB SO-DIMMを買って、増設してみました。
今回買ったのはWINTENのSO-DIMM DDR4 3200 32GBです

他のPCにもさしてみるか、ということで2枚セットで購入して増設しました・・・
結果無事32GBを認識しました。
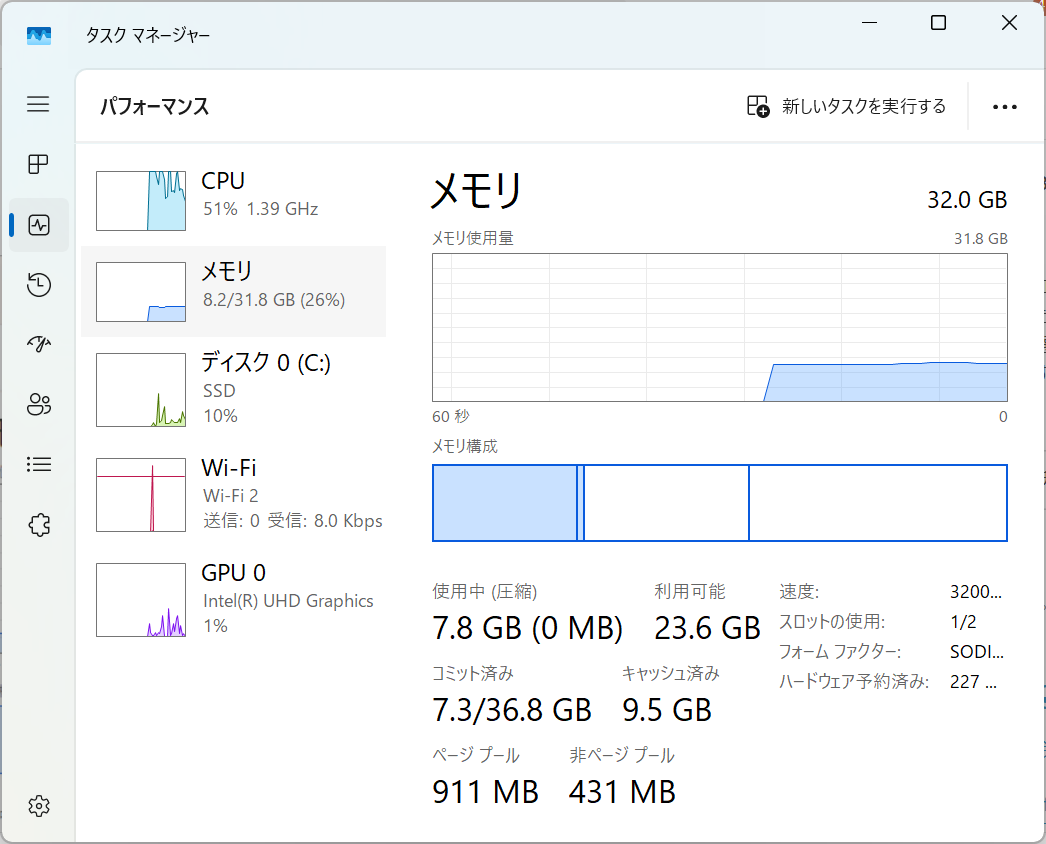
とりあえず現状簡単にできる範囲でのカスタマイズはもうないなぁ、といったところです。