[root@esxi:~] vim-cmd hostsvc/firmware/backup_config
Bundle can be downloaded at : http://*/downloads/52c603d0-73cb-65d5-893f-828faaa2f08b/configBundle-esxi.adsample.local.tgz
[root@esxi:~]
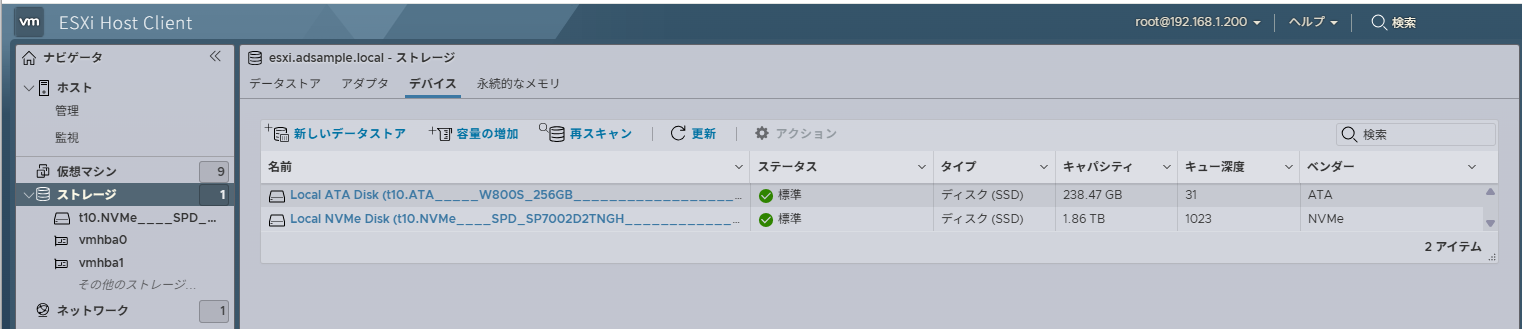
[root@esxi:~] esxcli storage core device list
t10.ATA_____W800S_256GB_____________________________2202211088199_______
Display Name: Local ATA Disk (t10.ATA_____W800S_256GB_____________________________2202211088199_______)
Has Settable Display Name: true
Size: 244198
Device Type: Direct-Access
Multipath Plugin: HPP
Devfs Path: /vmfs/devices/disks/t10.ATA_____W800S_256GB_____________________________2202211088199_______
Vendor: ATA
Model: W800S 256GB
Revision: 3G5A
SCSI Level: 5
Is Pseudo: false
Status: on
Is RDM Capable: false
Is Local: true
Is Removable: false
Is SSD: true
Is VVOL PE: false
Is Offline: false
Is Perennially Reserved: false
Queue Full Sample Size: 0
Queue Full Threshold: 0
Thin Provisioning Status: yes
Attached Filters:
VAAI Status: unsupported
Other UIDs: vml.01000000003232303232313130383831393920202020202020573830305320
Is Shared Clusterwide: false
Is SAS: false
Is USB: false
Is Boot Device: true
Device Max Queue Depth: 31
No of outstanding IOs with competing worlds: 31
Drive Type: unknown
RAID Level: unknown
Number of Physical Drives: unknown
Protection Enabled: false
PI Activated: false
PI Type: 0
PI Protection Mask: NO PROTECTION
Supported Guard Types: NO GUARD SUPPORT
DIX Enabled: false
DIX Guard Type: NO GUARD SUPPORT
Emulated DIX/DIF Enabled: false
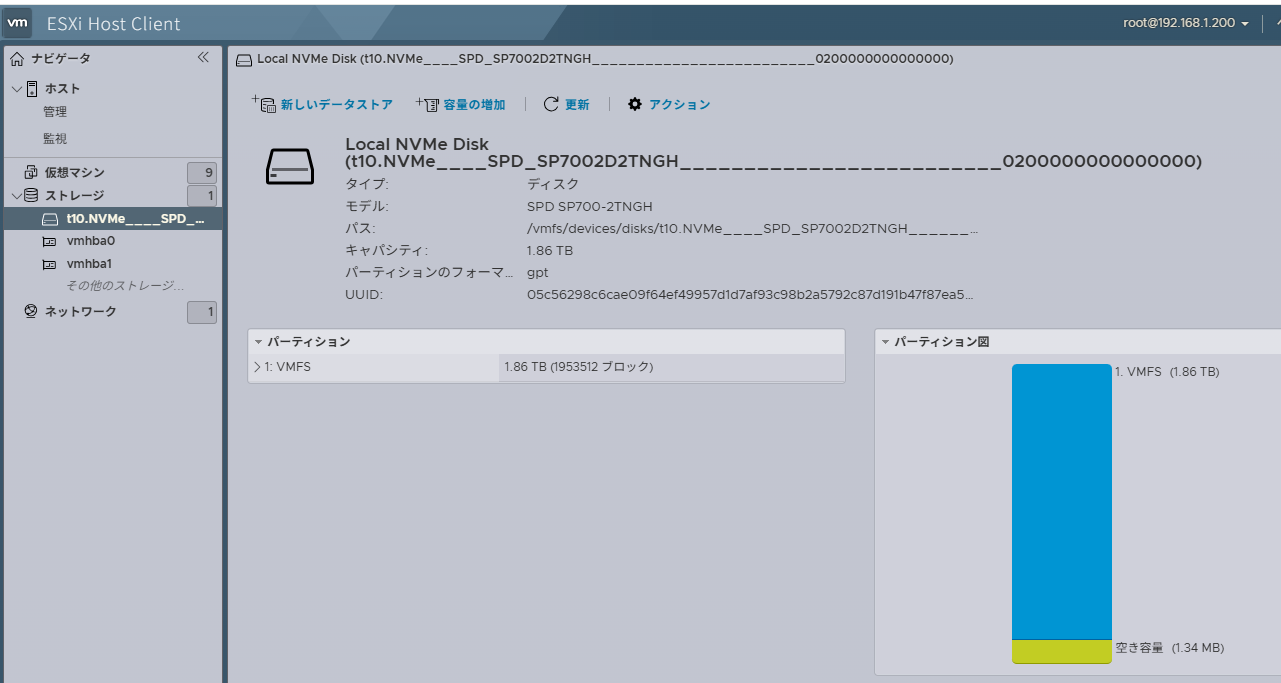
t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000
Display Name: Local NVMe Disk (t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000)
Has Settable Display Name: true
Size: 1953514
Device Type: Direct-Access
Multipath Plugin: HPP
Devfs Path: /vmfs/devices/disks/t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000
Vendor: NVMe
Model: SPD SP700-2TNGH
Revision: SP02203A
SCSI Level: 0
Is Pseudo: false
Status: on
Is RDM Capable: false
Is Local: true
Is Removable: false
Is SSD: true
Is VVOL PE: false
Is Offline: false
Is Perennially Reserved: false
Queue Full Sample Size: 0
Queue Full Threshold: 0
Thin Provisioning Status: no
Attached Filters:
VAAI Status: unsupported
Other UIDs: vml.05c56298c6cae09f64ef49957d1d7af93c98b2a5792c87d191b47f87ea5b89f9e2
Is Shared Clusterwide: false
Is SAS: false
Is USB: false
Is Boot Device: false
Device Max Queue Depth: 1023
No of outstanding IOs with competing worlds: 32
Drive Type: physical
RAID Level: NA
Number of Physical Drives: 1
Protection Enabled: false
PI Activated: false
PI Type: 0
PI Protection Mask: NO PROTECTION
Supported Guard Types: NO GUARD SUPPORT
DIX Enabled: false
DIX Guard Type: NO GUARD SUPPORT
Emulated DIX/DIF Enabled: false
[root@esxi:~]
パーテーションは1番の方なので下記を実施
[root@esxi:~] voma -m vmfs -f check -N -d /vmfs/devices/disks/vml.05c56298c6cae09f64ef49957d1d7af93c98b2a5792c87d191b47f87ea5b89f9e2:1
Running VMFS Checker version 2.1 in check mode
Initializing LVM metadata, Basic Checks will be done
Checking for filesystem activity
Performing filesystem liveness check..|Scanning for VMFS-6 host activity (4096 bytes/HB, 1024 HBs).
Reservation Support is not present for NVME devices
Performing filesystem liveness check..|
########################################################################
# Warning !!! #
# #
# You are about to execute VOMA without device reservation. #
# Any access to this device from other hosts when VOMA is running #
# can cause severe data corruption #
# #
# This mode is supported only under VMware support supervision. #
########################################################################
Do you want to continue (Y/N)?
0) _Yes
1) _No
Select a number from 0-1: 0
Phase 1: Checking VMFS header and resource files
Detected VMFS-6 file system (labeled:'nvme2tb') with UUID:68e4cab1-0a865c28-49c0-04ab182311d3, Version 6:82
Phase 2: Checking VMFS heartbeat region
Phase 3: Checking all file descriptors.
Phase 4: Checking pathname and connectivity.
Phase 5: Checking resource reference counts.
Total Errors Found: 0
[root@esxi:~]
[root@esxi:~] esxcli storage core path list
sata.vmhba0-sata.0:1-t10.ATA_____W800S_256GB_____________________________2202211088199_______
UID: sata.vmhba0-sata.0:1-t10.ATA_____W800S_256GB_____________________________2202211088199_______
Runtime Name: vmhba0:C0:T1:L0
Device: t10.ATA_____W800S_256GB_____________________________2202211088199_______
Device Display Name: Local ATA Disk (t10.ATA_____W800S_256GB_____________________________2202211088199_______)
Adapter: vmhba0
Controller: Not Applicable
Channel: 0
Target: 1
LUN: 0
Plugin: HPP
State: active
Transport: sata
Adapter Identifier: sata.vmhba0
Target Identifier: sata.0:1
Adapter Transport Details: Unavailable or path is unclaimed
Target Transport Details: Unavailable or path is unclaimed
Maximum IO Size: 33554432
pcie.300-pcie.0:0-t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000
UID: pcie.300-pcie.0:0-t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000
Runtime Name: vmhba1:C0:T0:L0
Device: t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000
Device Display Name: Local NVMe Disk (t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000)
Adapter: vmhba1
Controller: nqn.2014-08.org.nvmexpress_1e4b_SPD_SP700-2TNGH_________________________0901SP7007D00399
Channel: 0
Target: 0
LUN: 0
Plugin: HPP
State: active
Transport: pcie
Adapter Identifier: pcie.300
Target Identifier: pcie.0:0
Adapter Transport Details: Unavailable or path is unclaimed
Target Transport Details: Unavailable or path is unclaimed
Maximum IO Size: 524288
[root@esxi:~]
[root@esxi:~] esxcfg-mpath -b
t10.ATA_____W800S_256GB_____________________________2202211088199_______ : Local ATA Disk (t10.ATA_____W800S_256GB_____________________________2202211088199_______)
vmhba0:C0:T1:L0 LUN:0 state:active Local HBA vmhba0 channel 0 target 1
t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000 : Local NVMe Disk (t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000)
vmhba1:C0:T0:L0 LUN:0 state:active Local HBA vmhba1 channel 0 target 0
[root@esxi:~]
[root@esxi:~] esxcli storage core device list
t10.ATA_____W800S_256GB_____________________________2202211088199_______
Display Name: Local ATA Disk (t10.ATA_____W800S_256GB_____________________________2202211088199_______)
Has Settable Display Name: true
Size: 244198
Device Type: Direct-Access
Multipath Plugin: HPP
Devfs Path: /vmfs/devices/disks/t10.ATA_____W800S_256GB_____________________________2202211088199_______
Vendor: ATA
Model: W800S 256GB
Revision: 3G5A
SCSI Level: 5
Is Pseudo: false
Status: on
Is RDM Capable: false
Is Local: true
Is Removable: false
Is SSD: true
Is VVOL PE: false
Is Offline: false
Is Perennially Reserved: false
Queue Full Sample Size: 0
Queue Full Threshold: 0
Thin Provisioning Status: yes
Attached Filters:
VAAI Status: unsupported
Other UIDs: vml.01000000003232303232313130383831393920202020202020573830305320
Is Shared Clusterwide: false
Is SAS: false
Is USB: false
Is Boot Device: true
Device Max Queue Depth: 31
No of outstanding IOs with competing worlds: 31
Drive Type: unknown
RAID Level: unknown
Number of Physical Drives: unknown
Protection Enabled: false
PI Activated: false
PI Type: 0
PI Protection Mask: NO PROTECTION
Supported Guard Types: NO GUARD SUPPORT
DIX Enabled: false
DIX Guard Type: NO GUARD SUPPORT
Emulated DIX/DIF Enabled: false
t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000
Display Name: Local NVMe Disk (t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000)
Has Settable Display Name: true
Size: 1953514
Device Type: Direct-Access
Multipath Plugin: HPP
Devfs Path: /vmfs/devices/disks/t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000
Vendor: NVMe
Model: SPD SP700-2TNGH
Revision: SP02203A
SCSI Level: 0
Is Pseudo: false
Status: on
Is RDM Capable: false
Is Local: true
Is Removable: false
Is SSD: true
Is VVOL PE: false
Is Offline: false
Is Perennially Reserved: false
Queue Full Sample Size: 0
Queue Full Threshold: 0
Thin Provisioning Status: no
Attached Filters:
VAAI Status: unsupported
Other UIDs: vml.05c56298c6cae09f64ef49957d1d7af93c98b2a5792c87d191b47f87ea5b89f9e2
Is Shared Clusterwide: false
Is SAS: false
Is USB: false
Is Boot Device: false
Device Max Queue Depth: 1023
No of outstanding IOs with competing worlds: 32
Drive Type: physical
RAID Level: NA
Number of Physical Drives: 1
Protection Enabled: false
PI Activated: false
PI Type: 0
PI Protection Mask: NO PROTECTION
Supported Guard Types: NO GUARD SUPPORT
DIX Enabled: false
DIX Guard Type: NO GUARD SUPPORT
Emulated DIX/DIF Enabled: false
[root@esxi:~]
[root@esxi:~] esxcfg-scsidevs -c
Device UID Device Type Console Device Size Multipath PluginDisplay Name
t10.ATA_____W800S_256GB_____________________________2202211088199_______ Direct-Access /vmfs/devices/disks/t10.ATA_____W800S_256GB_____________________________2202211088199_______ 244198MB HPP Local ATA Disk (t10.ATA_____W800S_256GB_____________________________2202211088199_______)
t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000 Direct-Access /vmfs/devices/disks/t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000 1953514MB HPP Local NVMe Disk (t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000)
[root@esxi:~]
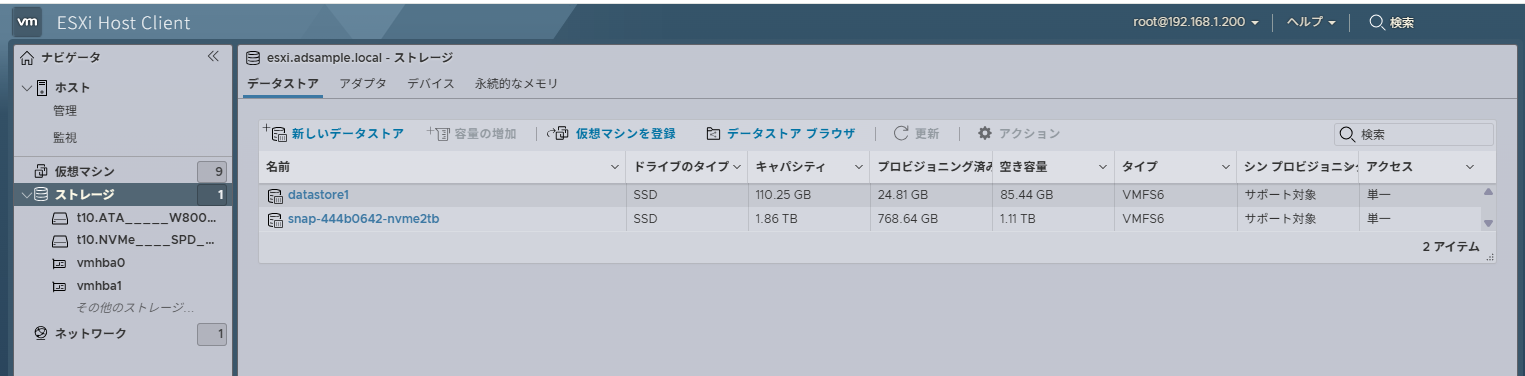
vmfsに関する出力となると、2TBデバイスが登場しない
[root@esxi:~] esxcli storage vmfs extent list
Volume Name VMFS UUID Extent Number Device Name Partition
------------------------------------------ ----------------------------------- ------------- ------------------------------------------------------------------------ ---------
datastore1 68cad69a-e82d8e40-5b65-5bb7fb6107f2 0 t10.ATA_____W800S_256GB_____________________________2202211088199_______ 8
OSDATA-68cad69a-d23fb18e-73e5-5bb7fb6107f2 68cad69a-d23fb18e-73e5-5bb7fb6107f2 0 t10.ATA_____W800S_256GB_____________________________2202211088199_______ 7
[root@esxi:~]
[root@esxi:~] esxcli system module parameters list --module=nvme_pcie
Name Type Value Description
--------------------------- ---- ----- -----------
nvmePCIEBlkSizeAwarePollAct int NVMe PCIe block size aware poll activate. Valid if poll activated. Default activated.
nvmePCIEDebugMask int NVMe PCIe driver debug mask
nvmePCIEDma4KSwitch int NVMe PCIe 4k-alignment DMA
nvmePCIEFakeAdminQSize uint NVMe PCIe fake ADMIN queue size. 0's based
nvmePCIELogLevel int NVMe PCIe driver log level
nvmePCIEMsiEnbaled int NVMe PCIe MSI interrupt enable
nvmePCIEPollAct int NVMe PCIe hybrid poll activate, MSIX interrupt must be enabled. Default activated.
nvmePCIEPollInterval uint NVMe PCIe hybrid poll interval between each poll in microseconds. Valid if poll activated. Default 50us.
nvmePCIEPollOIOThr uint NVMe PCIe hybrid poll OIO threshold of automatic switch from interrupt to poll. Valid if poll activated. Default 30 OIO commands per IO queue.
[root@esxi:~] esxcli system module parameters list --module=vmknvme
Name Type Value Description
------------------------------------- ---- ----- -----------
vmknvme_adapter_num_cmpl_queues uint Number of PSA completion queues for NVMe-oF adapter, min: 1, max: 16, default: 4
vmknvme_bind_intr uint If enabled, the interrupt cookies are binded to completion worlds. This parameter is only applied when using driver completion worlds.
vmknvme_compl_world_type uint completion world type, PSA: 0, VMKNVME: 1
vmknvme_ctlr_recover_initial_attempts uint Number of initial controller recover attempts, MIN: 2, MAX: 30
vmknvme_ctlr_recover_method uint controller recover method after initial recover attempts, RETRY: 0, DELETE: 1
vmknvme_cw_rate uint Number of completion worlds per IO queue (NVMe/PCIe only). Number is a power of 2. Applies when number of queues less than 4.
vmknvme_enable_noiob uint If enabled, driver will split the commands based on NOIOB.
vmknvme_hostnqn_format uint HostNQN format, UUID: 0, HostName: 1
vmknvme_io_queue_num uint vmknvme IO queue number for NVMe/PCIe adapter: pow of 2 in [1, 16]
vmknvme_io_queue_size uint IO queue size: [8, 1024]
vmknvme_iosplit_workaround uint If enabled, qdepth in PSA layer is half size of vmknvme settings.
vmknvme_log_level uint log level: [0, 20]
vmknvme_max_prp_entries_num uint User defined maximum number of PRP entries per controller:default value is 0
vmknvme_stats uint Nvme statistics per controller (NVMe/PCIe only now). Logical OR of flags for collecting. 0x0 for disable, 0x1 for basic data (IO pattern), 0x2 for histogram without IO block size, 0x4 for histogram with IO block size. Default 0x2.
vmknvme_total_io_queue_size uint Aggregated IO queue size of a controller, MIN: 64, MAX: 4096
vmknvme_use_default_domain_name uint If set to 1, the default domain name "com.vmware", not the system domain name will always be used to generate host NQN. Not used: 0, used: 1, default: 0
[root@esxi:~] esxcli system module parameters list --module=vmknvme_vmkapi_compat
[root@esxi:~]
[root@esxi:~] esxcli nvme device list
HBA Name Status Signature
-------- ------ ---------
vmhba1 Online nvmeMgmt-nvmhba0
[root@esxi:~] esxcli nvme device get -A vmhba1
Controller Identify Info:
PCIVID: 0x1e4b
PCISSVID: 0x1e4b
Serial Number: 0901SP7007D00399
Model Number: SPD SP700-2TNGH
Firmware Revision: SP02203A
Recommended Arbitration Burst: 0
IEEE OUI Identifier: 000000
Controller Associated with an SR-IOV Virtual Function: false
Controller Associated with a PCI Function: true
NVM Subsystem May Contain Two or More Controllers: false
NVM Subsystem Contains Only One Controller: true
NVM Subsystem May Contain Two or More PCIe Ports: false
NVM Subsystem Contains Only One PCIe Port: true
Max Data Transfer Size: 7
Controller ID: 0
Version: 1.4
RTD3 Resume Latency: 500000 us
RTD3 Entry Latency: 2000000 us
Optional Firmware Activation Event Support: true
Optional Namespace Attribute Changed Event Support: false
Host Identifier Support: false
Namespace Management and Attachment Support: false
Firmware Activate and Download Support: true
Format NVM Support: true
Security Send and Receive Support: true
Abort Command Limit: 2
Async Event Request Limit: 3
Firmware Activate Without Reset Support: true
Firmware Slot Number: 3
The First Slot Is Read-only: false
Telemetry Log Page Support: false
Command Effects Log Page Support: true
SMART/Health Information Log Page per Namespace Support: false
Error Log Page Entries: 63
Number of Power States Support: 4
Format of Admin Vendor Specific Commands Is Same: true
Format of Admin Vendor Specific Commands Is Vendor Specific: false
Autonomous Power State Transitions Support: true
Warning Composite Temperature Threshold: 363
Critical Composite Temperature Threshold: 368
Max Time for Firmware Activation: 200 * 100ms
Host Memory Buffer Preferred Size: 8192 * 4KB
Host Memory Buffer Min Size: 8192 * 4KB
Total NVM Capacity: 0x1dceea56000
Unallocated NVM Capacity: 0x0
Access Size: 0 * 512B
Total Size: 0 * 128KB
Authentication Method: 0
Number of RPMB Units: 0
Keep Alive Support: 0
Max Submission Queue Entry Size: 64 Bytes
Required Submission Queue Entry Size: 64 Bytes
Max Completion Queue Entry Size: 16 Bytes
Required Completion Queue Entry Size: 16 Bytes
Max Outstanding Commands: 0
Number of Namespaces: 1
Reservation Support: false
Save/Select Field in Set/Get Feature Support: true
Write Zeroes Command Support: true
Dataset Management Command Support: true
Write Uncorrectable Command Support: true
Compare Command Support: true
Fused Operation Support: false
Cryptographic Erase as Part of Secure Erase Support: false
Cryptographic Erase and User Data Erase to All Namespaces: false
Cryptographic Erase and User Data Erase to One Particular Namespace: true
Format Operation to All Namespaces: false
Format Opertaion to One Particular Namespace: true
Volatile Write Cache Is Present: true
Atomic Write Unit Normal: 0 Logical Blocks
Atomic Write Unit Power Fail: 0 Logical Blocks
Format of All NVM Vendor Specific Commands Is Same: false
Format of All NVM Vendor Specific Commands Is Vendor Specific: true
Atomic Compare and Write Unit: 0
SGL Address Specify Offset Support: false
MPTR Contain SGL Descriptor Support: false
SGL Length Able to Larger than Data Amount: false
SGL Length Shall Be Equal to Data Amount: true
Byte Aligned Contiguous Physical Buffer of Metadata Support: false
SGL Bit Bucket Descriptor Support: false
SGL Keyed SGL Data Block Descriptor Support: false
SGL for NVM Command Set Support: false
NVM Subsystem NVMe Qualified Name:
NVM Subsystem NVMe Qualified Name (hex format):
[root@esxi:~]
[root@esxi:~] esxcli storage vmfs lockmode list
Volume Name UUID Type Locking Mode ATS Compatible ATS Upgrade Modes ATS Incompatibility Reason
------------------------------------------ ----------------------------------- -------- ------------ -------------- ----------------- --------------------------
datastore1 68cad69a-e82d8e40-5b65-5bb7fb6107f2 VMFS-6 ATS+SCSI false None Device does not support ATS
OSDATA-68cad69a-d23fb18e-73e5-5bb7fb6107f2 68cad69a-d23fb18e-73e5-5bb7fb6107f2 Non-VMFS ATS+SCSI false None Device does not support ATS
[root@esxi:~]
vomaコマンドでファイルシステムチェック
[root@esxi:~] ls /vmfs/devices/disks/
t10.ATA_____W800S_256GB_____________________________2202211088199_______
t10.ATA_____W800S_256GB_____________________________2202211088199_______:1
t10.ATA_____W800S_256GB_____________________________2202211088199_______:5
t10.ATA_____W800S_256GB_____________________________2202211088199_______:6
t10.ATA_____W800S_256GB_____________________________2202211088199_______:7
t10.ATA_____W800S_256GB_____________________________2202211088199_______:8
t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000
t10.NVMe____SPD_SP7002D2TNGH_________________________0200000000000000:1
vml.0100000000303230305f303030305f303030305f3030303000535044205350
vml.0100000000303230305f303030305f303030305f3030303000535044205350:1
vml.01000000003232303232313130383831393920202020202020573830305320
vml.01000000003232303232313130383831393920202020202020573830305320:1
vml.01000000003232303232313130383831393920202020202020573830305320:5
vml.01000000003232303232313130383831393920202020202020573830305320:6
vml.01000000003232303232313130383831393920202020202020573830305320:7
vml.01000000003232303232313130383831393920202020202020573830305320:8
vml.05c56298c6cae09f64ef49957d1d7af93c98b2a5792c87d191b47f87ea5b89f9e2
vml.05c56298c6cae09f64ef49957d1d7af93c98b2a5792c87d191b47f87ea5b89f9e2:1
[root@esxi:~] voma -m vmfs -f check -N -d /vmfs/devices/disks/vml.05c56298c6cae09f64ef49957d1d7af93c98b2a5792c87d191b47f87ea5b8
9f9e2:1
Running VMFS Checker version 2.1 in check mode
Initializing LVM metadata, Basic Checks will be done
Checking for filesystem activity
Performing filesystem liveness check..|Scanning for VMFS-6 host activity (4096 bytes/HB, 1024 HBs).
Reservation Support is not present for NVME devices
Performing filesystem liveness check..|
########################################################################
# Warning !!! #
# #
# You are about to execute VOMA without device reservation. #
# Any access to this device from other hosts when VOMA is running #
# can cause severe data corruption #
# #
# This mode is supported only under VMware support supervision. #
########################################################################
Do you want to continue (Y/N)?
0) _Yes
1) _No
Select a number from 0-1: 0
Phase 1: Checking VMFS header and resource files
Detected VMFS-6 file system (labeled:'nvme2tb') with UUID:68e4cab1-0a865c28-49c0-04ab182311d3, Version 6:82
Phase 2: Checking VMFS heartbeat region
Phase 3: Checking all file descriptors.
Phase 4: Checking pathname and connectivity.
Phase 5: Checking resource reference counts.
Total Errors Found: 0
[root@esxi:~]
[root@esxi:~] voma -m vmfs -f check -N -d /vmfs/devices/disks/vml.05c56298c6cae09f64ef49957d1d7af93c98b2a5792c87d191b47f87ea5b8
9f9e2:1
Running VMFS Checker version 2.1 in check mode
Initializing LVM metadata, Basic Checks will be done
Checking for filesystem activity
Performing filesystem liveness check..|Scanning for VMFS-6 host activity (4096 bytes/HB, 1024 HBs).
Reservation Support is not present for NVME devices
Performing filesystem liveness check..|
########################################################################
# Warning !!! #
# #
# You are about to execute VOMA without device reservation. #
# Any access to this device from other hosts when VOMA is running #
# can cause severe data corruption #
# #
# This mode is supported only under VMware support supervision. #
########################################################################
Do you want to continue (Y/N)?
0) _Yes
1) _No
Select a number from 0-1: 0
Phase 1: Checking VMFS header and resource files
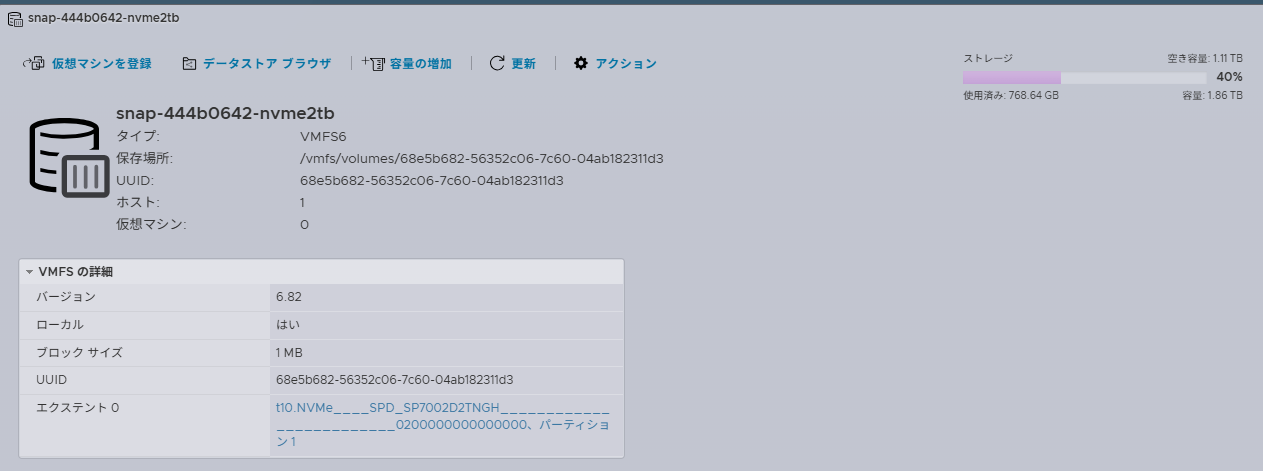
Detected VMFS-6 file system (labeled:'snap-444b0642-nvme2tb') with UUID:68e5b682-56352c06-7c60-04ab182311d3, Version 6:82
Phase 2: Checking VMFS heartbeat region
Phase 3: Checking all file descriptors.
Phase 4: Checking pathname and connectivity.
Phase 5: Checking resource reference counts.
Total Errors Found: 0
[root@esxi:~] esxcli storage vmfs snapshot list
[root@esxi:~] esxcli storage filesystem list
Mount Point Volume Name UUID Mounted Type Size Free
------------------------------------------------- ------------------------------------------ ----------------------------------- ------- ------ ------------- -------------
/vmfs/volumes/68cad69a-e82d8e40-5b65-5bb7fb6107f2 datastore1 68cad69a-e82d8e40-5b65-5bb7fb6107f2 true VMFS-6 118380036096 91743059968
/vmfs/volumes/68e5b682-56352c06-7c60-04ab182311d3 snap-444b0642-nvme2tb 68e5b682-56352c06-7c60-04ab182311d3 true VMFS-6 2048162529280 1222844088320
/vmfs/volumes/68cad69a-d23fb18e-73e5-5bb7fb6107f2 OSDATA-68cad69a-d23fb18e-73e5-5bb7fb6107f2 68cad69a-d23fb18e-73e5-5bb7fb6107f2 true VMFSOS 128580583424 125363552256
/vmfs/volumes/fa8a25f7-ba40ebee-45ac-f419c9f388e0 BOOTBANK1 fa8a25f7-ba40ebee-45ac-f419c9f388e0 true vfat 4293591040 4022075392
/vmfs/volumes/f43b0450-7e4d6762-c6be-52e6552cc1f8 BOOTBANK2 f43b0450-7e4d6762-c6be-52e6552cc1f8 true vfat 4293591040 4021354496
[root@esxi:~]
特に状況は変わらない
lockmode確認すると、そちらでもデバイスは増えた
[root@esxi:~] esxcli storage vmfs lockmode list
Volume Name UUID Type Locking Mode ATS Compatible ATS Upgrade Modes ATS Incompatibility Reason
------------------------------------------ ----------------------------------- -------- ------------ -------------- ----------------- --------------------------
datastore1 68cad69a-e82d8e40-5b65-5bb7fb6107f2 VMFS-6 ATS+SCSI false None Device does not support ATS
snap-444b0642-nvme2tb 68e5b682-56352c06-7c60-04ab182311d3 VMFS-6 ATS+SCSI false None Device does not support ATS
OSDATA-68cad69a-d23fb18e-73e5-5bb7fb6107f2 68cad69a-d23fb18e-73e5-5bb7fb6107f2 Non-VMFS ATS+SCSI false None Device does not support ATS
[root@esxi:~]
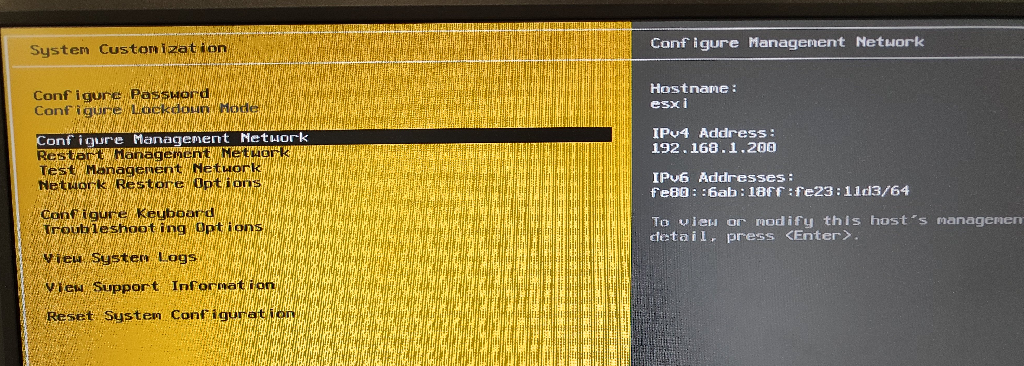
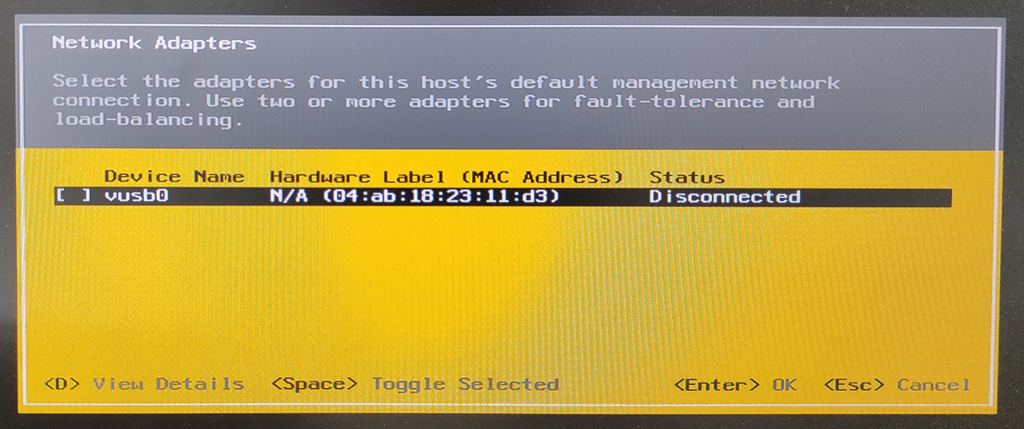
Persisting USB NIC Bindings Option 1: Run the following ESXCLI command which will enable the driver parameter to perform a full USB bus scan during startup: esxcli system module parameters set -p “usbBusFullScanOnBootEnabled=1” -m vmkusb_nic_fling
[root@esxi:~] esxcli system module list|grep nic
vmkusb_nic_fling true true
[root@esxi:~] esxcli system module list|grep usb
vmkusb_nic_fling true true
[root@esxi:~]
モジュール vmkusb_nic_fling は、ESXi 8.0でも存在している。
モジュールに対して設定できるパラメータを確認。
[root@esxi:~] esxcli system module parameters list -m vmkusb_nic_fling
Name Type Value Description
--------------------------- ------ ----- -----------
usbBusFullScanOnBootEnabled int Enable USB Bus full scan on system boot: 0 No (Default), 1 Yes
usbCdromPassthroughEnabled int Enable USB CDROM device for USB passtrough: 0 No (Default), 1 Yes
usbStorageRegisterDelaySecs int Delay to register cached USB storage device: Min: 0 second, Max: 600 seconds, Default: 10 seconds
vusb0_mac string Persist vusb0 MAC Address: xx:xx:xx:xx:xx:xx
vusb10_mac string Persist vusb10 MAC Address: xx:xx:xx:xx:xx:xx
vusb11_mac string Persist vusb11 MAC Address: xx:xx:xx:xx:xx:xx
vusb1_mac string Persist vusb1 MAC Address: xx:xx:xx:xx:xx:xx
vusb2_mac string Persist vusb2 MAC Address: xx:xx:xx:xx:xx:xx
vusb3_mac string Persist vusb3 MAC Address: xx:xx:xx:xx:xx:xx
vusb4_mac string Persist vusb4 MAC Address: xx:xx:xx:xx:xx:xx
vusb5_mac string Persist vusb5 MAC Address: xx:xx:xx:xx:xx:xx
vusb6_mac string Persist vusb6 MAC Address: xx:xx:xx:xx:xx:xx
vusb7_mac string Persist vusb7 MAC Address: xx:xx:xx:xx:xx:xx
vusb8_mac string Persist vusb8 MAC Address: xx:xx:xx:xx:xx:xx
vusb9_mac string Persist vusb9 MAC Address: xx:xx:xx:xx:xx:xx
[root@esxi:~]
usbBusFullScanOnBootEnabled が初期値0で存在していることを確認
(“Persisting VMkernel to USB NIC mappings”に記載されている複数のUSB NICがある時に、指す場所を変えてもvusbの番号が変わらないようにするための設定も引き続きある)
現段階のesxcliでの正式オプションに修正して、「esxcli system module parameters set –module=vmkusb_nic_fling –parameter-string=”usbBusFullScanOnBootEnabled=1″」と実行する
[root@esxi:~] esxcli system module parameters set --module=vmkusb_nic_fling --parameter-string="usbBusFullScanOnBootEnabled=1"
[root@esxi:~] esxcli system module parameters list -m vmkusb_nic_fling
Name Type Value Description
--------------------------- ------ ----- -----------
usbBusFullScanOnBootEnabled int 1 Enable USB Bus full scan on system boot: 0 No (Default), 1 Yes
usbCdromPassthroughEnabled int Enable USB CDROM device for USB passtrough: 0 No (Default), 1 Yes
usbStorageRegisterDelaySecs int Delay to register cached USB storage device: Min: 0 second, Max: 600 seconds, Default: 10 seconds
vusb0_mac string Persist vusb0 MAC Address: xx:xx:xx:xx:xx:xx
vusb10_mac string Persist vusb10 MAC Address: xx:xx:xx:xx:xx:xx
vusb11_mac string Persist vusb11 MAC Address: xx:xx:xx:xx:xx:xx
vusb1_mac string Persist vusb1 MAC Address: xx:xx:xx:xx:xx:xx
vusb2_mac string Persist vusb2 MAC Address: xx:xx:xx:xx:xx:xx
vusb3_mac string Persist vusb3 MAC Address: xx:xx:xx:xx:xx:xx
vusb4_mac string Persist vusb4 MAC Address: xx:xx:xx:xx:xx:xx
vusb5_mac string Persist vusb5 MAC Address: xx:xx:xx:xx:xx:xx
vusb6_mac string Persist vusb6 MAC Address: xx:xx:xx:xx:xx:xx
vusb7_mac string Persist vusb7 MAC Address: xx:xx:xx:xx:xx:xx
vusb8_mac string Persist vusb8 MAC Address: xx:xx:xx:xx:xx:xx
vusb9_mac string Persist vusb9 MAC Address: xx:xx:xx:xx:xx:xx
[root@esxi:~]
[root@esxi:~] ls -l /etc/rc.local.d
total 32
-r-xr-xr-x 1 root root 378 Apr 3 2025 009.vsanwitness.sh
drwxr-xr-x 1 root root 512 Oct 3 00:25 autodeploy
-r-xr-xr-x 1 root root 2249 Apr 3 2025 backupPrevBootLogs.py
-r-xr-xr-x 1 root root 2071 Apr 3 2025 cleanupStatefulHost.py
-r-xr-xr-x 1 root root 2567 Apr 3 2025 kickstart.py
-rwxr-xr-t 1 root root 506 Apr 3 2025 local.sh
-r-xr-xr-x 1 root root 397 Apr 3 2025 psaScrub.sh
-r-xr-xr-x 1 root root 1190 Apr 3 2025 raiseConfigStoreVob.py
[root@esxi:~] cat /etc/rc.local.d/local.sh
#!/bin/sh ++group=host/vim/vmvisor/boot
# local configuration options
# Note: modify at your own risk! If you do/use anything in this
# script that is not part of a stable API (relying on files to be in
# specific places, specific tools, specific output, etc) there is a
# possibility you will end up with a broken system after patching or
# upgrading. Changes are not supported unless under direction of
# VMware support.
# Note: This script will not be run when UEFI secure boot is enabled.
exit 0
[root@esxi:~]
今回実行したesxcliのコマンド群を追加
[root@esxi:~] vi /etc/rc.local.d/local.sh
[root@esxi:~] cat /etc/rc.local.d/local.sh
#!/bin/sh ++group=host/vim/vmvisor/boot
# local configuration options
# Note: modify at your own risk! If you do/use anything in this
# script that is not part of a stable API (relying on files to be in
# specific places, specific tools, specific output, etc) there is a
# possibility you will end up with a broken system after patching or
# upgrading. Changes are not supported unless under direction of
# VMware support.
# Note: This script will not be run when UEFI secure boot is enabled.
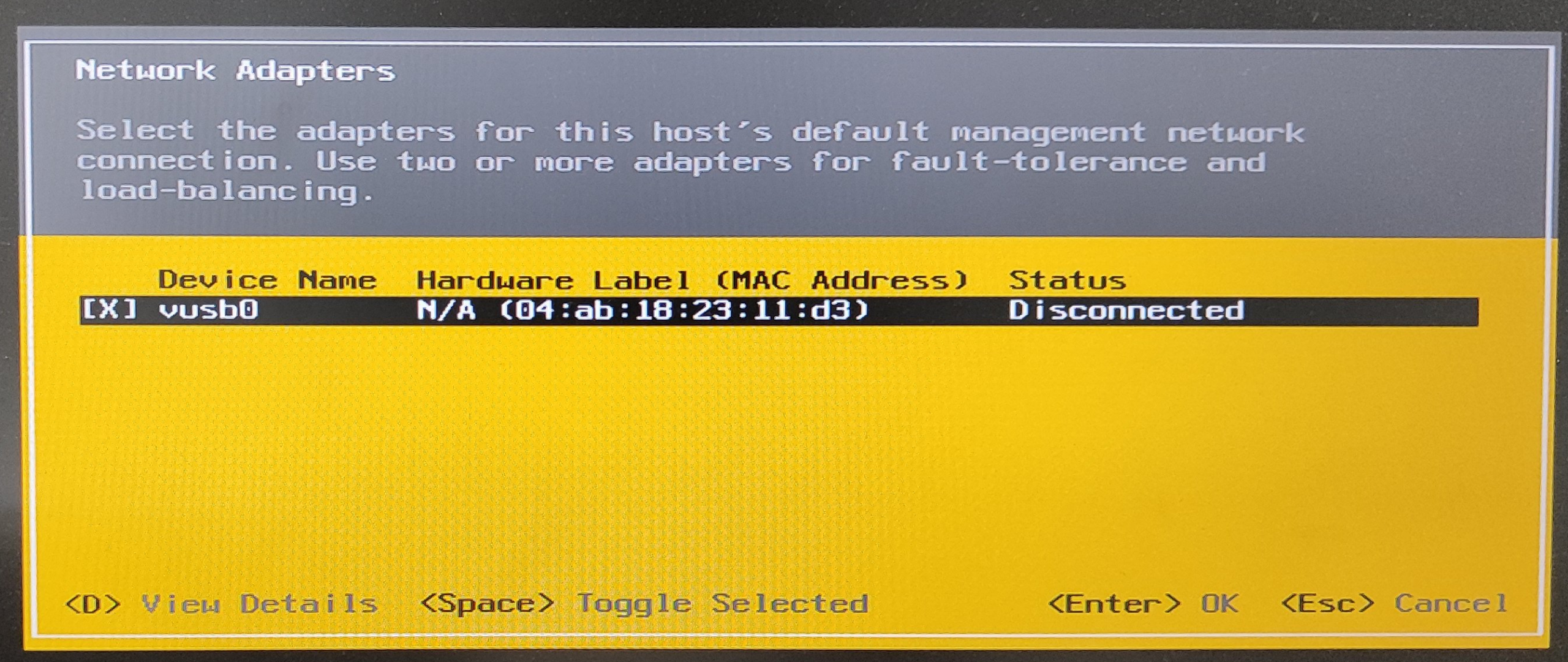
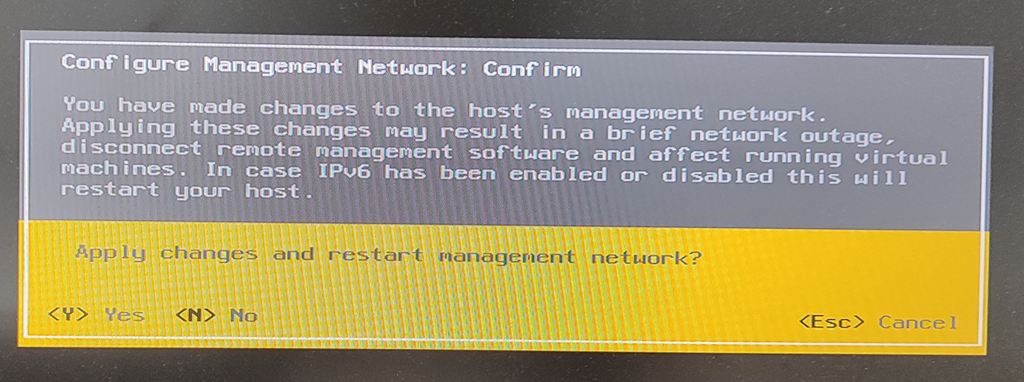
esxcli network vswitch standard uplink add --vswitch-name=vSwitch0 --uplink-name=vusb0
esxcli network vswitch standard portgroup policy failover set --portgroup-name="Management Network" --active-uplinks=vusb0
esxcli network vswitch standard portgroup policy failover set --portgroup-name="VM Network" --active-uplinks=vusb0
exit 0
[root@esxi:~]
[root@esxi:~] date
Fri Oct 3 00:57:12 UTC 2025
[root@esxi:~] ls -ltr /bootbank/
total 261895
<略>
-rwx------ 1 root root 1797 Sep 17 16:34 boot.cfg
-rwx------ 1 root root 102 Oct 3 00:25 jumpstrt.gz
-rwx------ 1 root root 266977 Oct 3 00:31 state.tgz
[root@esxi:~]
/bootbank/state.tgz が更新されていない
[root@esxi:~] auto-backup.sh
ConfigStore has been modified since the last backup
Bootbank lock is /var/lock/bootbank/f43b0450-7e4d6762-c6be-52e6552cc1f8
INFO: Successfully claimed lock file for pid 526790
Saving current state in /bootbank
Ssh configuration synced to configstore
Creating ConfigStore Backup
Locking esx.conf
Creating archive
Unlocked esx.conf
Using key ID d27fa69c-5edc-424d-bc0f-61d7966bf4d4 to encrypt
Clock updated.
Time: 00:57:21 Date: 10/03/2025 UTC
[root@esxi:~]
auto-backup.shを実行後を確認
[root@esxi:~] ls -ltr /bootbank/
total 261895
<略>
-rwx------ 1 root root 1797 Sep 17 16:34 boot.cfg
-rwx------ 1 root root 102 Oct 3 00:25 jumpstrt.gz
-rwx------ 1 root root 266974 Oct 3 00:57 state.tgz
[root@esxi:~]
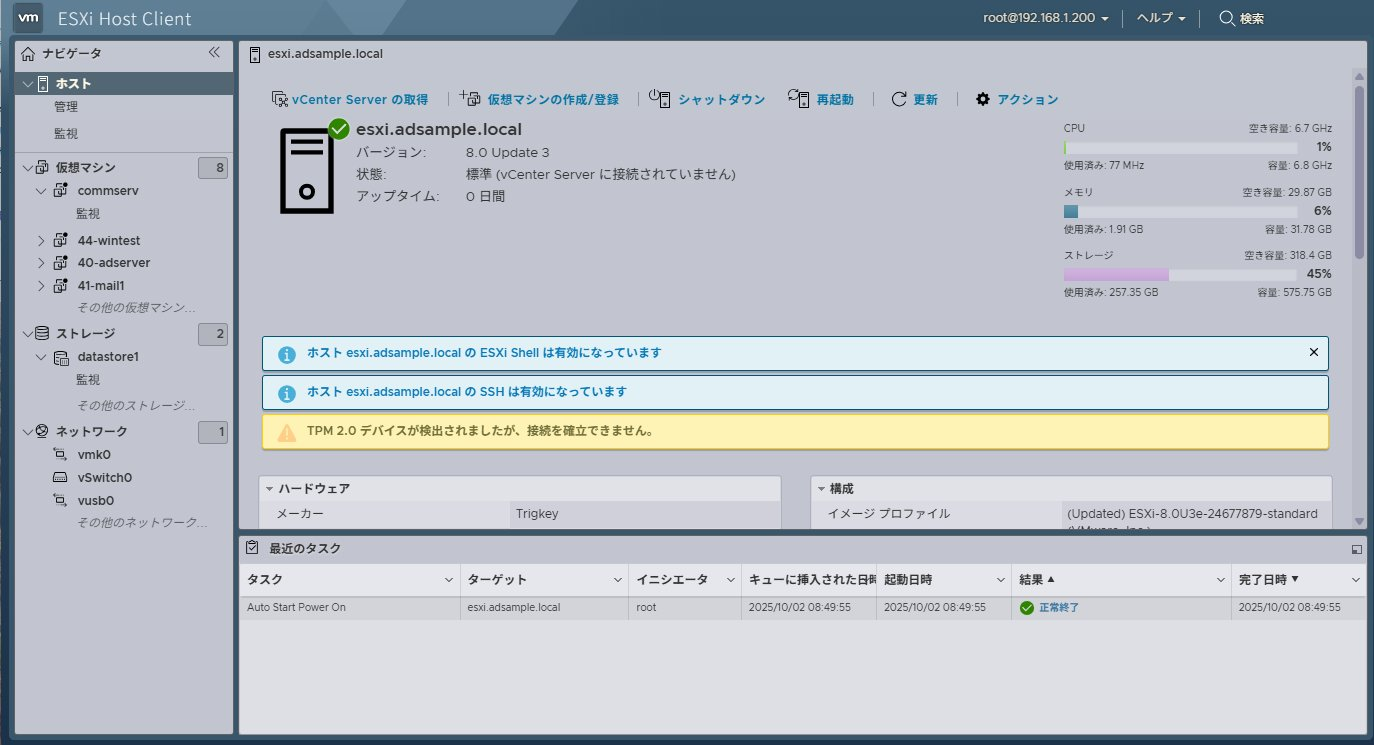
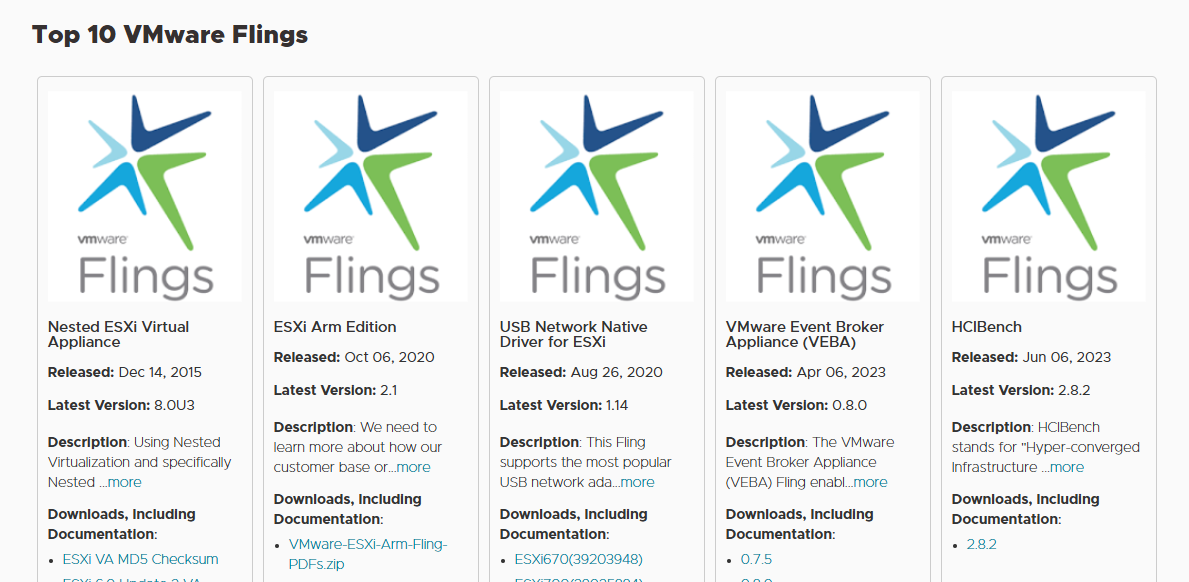
VMware flingsで配布している「USB Network Native Driver for ESXi」からvmkusb_nic_fling ドライバをインストールすると、使えるUSB NICの種類が増える
[root@esxi:/vmfs/volumes/6908722d-a37ea8a3-525a-4d150daf152f/iso] esxcli software vib install -d /vmfs/volumes/datastore1/iso/ESXi8
03-VMKUSB-NIC-FLING-76444229-component-24179899.zip
Installation Result
Message: The update completed successfully, but the system needs to be rebooted for the changes to be effective.
VIBs Installed: VMW_bootbank_vmkusb-nic-fling_1.14-2vmw.803.0.0.76444229
VIBs Removed:
VIBs Skipped:
Reboot Required: true
DPU Results:
[root@esxi:/vmfs/volumes/6908722d-a37ea8a3-525a-4d150daf152f/iso]
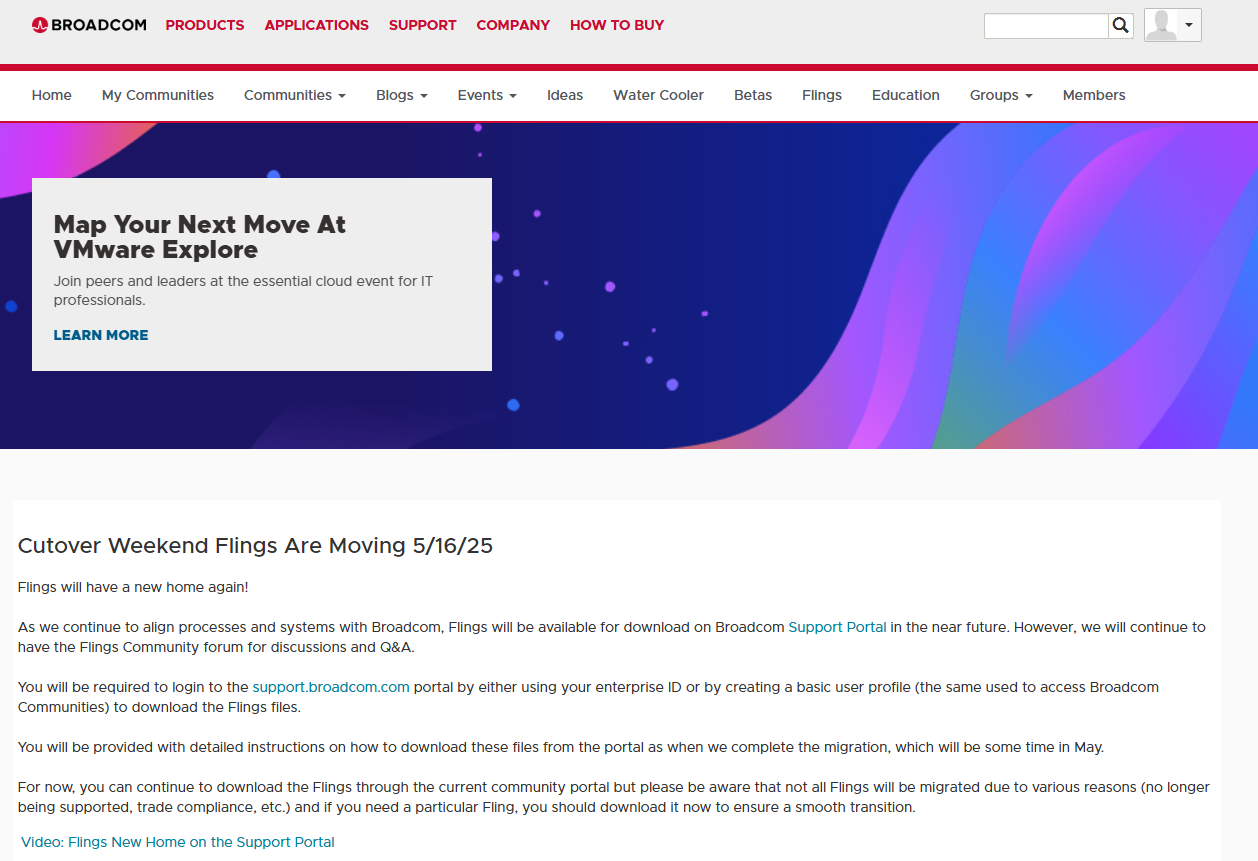
ESXi for ARM EditionやUSB Network Native Driver for ESXi といった以前VMware Flings http://flings.vmware.com にあったソフトウェアは、2023年10月に https://developer.vmware.com/samples にリダイレクトされるようになった。