[global]
<略>
allow nt4 crypto = yes
reject md5 clients = no
server reject md5 schannel = no
server schannel = yes
server schannel require seal = no
<略>
ontap91::> vserver cifs create -cifs-server svm91 -domain ADOSAKANA.LOCAL
In order to create an Active Directory machine account for the CIFS server, you
must supply the name and password of a Windows account with sufficient
privileges to add computers to the "CN=Computers" container within the
"ADOSAKANA.LOCAL" domain.
Enter the user name: administrator
Enter the password:
Warning: An account by this name already exists in Active Directory at
CN=SVM91,CN=Computers,DC=adosakana,DC=local.
If there is an existing DNS entry for the name SVM91, it must be
removed. Data ONTAP cannot remove such an entry.
Use an external tool to remove it after this command completes.
Ok to reuse this account? {y|n}: y
Error: command failed: Failed to create CIFS server SVM91. Reason:
create_with_lug: RPC: Unable to receive; errno = Connection reset by
peer; netid=tcp fd=17 TO=600.0s TT=0.119s O=224b I=0b CN=113/3 VSID=-3
127.0.0.1:766.
ontap91::>
ONTAP 9.1P22 シミュレーター
ontap91::> vserver cifs create -cifs-server svm91 -domain ADOSAKANA.LOCAL
In order to create an Active Directory machine account for the CIFS server, you
must supply the name and password of a Windows account with sufficient
privileges to add computers to the "CN=Computers" container within the
"ADOSAKANA.LOCAL" domain.
Enter the user name: administrator
Enter the password:
Error: Machine account creation procedure failed
[ 56] Loaded the preliminary configuration.
[ 92] Successfully connected to ip 172.17.44.49, port 88 using
TCP
[ 107] Successfully connected to ip 172.17.44.49, port 389 using
TCP
[ 110] Unable to start TLS: Connect error
[ 110] Additional info:
[ 110] Unable to connect to LDAP (Active Directory) service on
sambaad.ADOSAKANA.LOCAL
**[ 110] FAILURE: Unable to make a connection (LDAP (Active
** Directory):ADOSAKANA.LOCAL), result: 7652
Error: command failed: Failed to create the Active Directory machine account
"SVM91". Reason: LDAP Error: Cannot establish a connection to the
server.
ontap91::>
ontap91::> vserver cifs create -cifs-server svm91 -domain ADOSAKANA.LOCAL
In order to create an Active Directory machine account for the CIFS server, you
must supply the name and password of a Windows account with sufficient
privileges to add computers to the "CN=Computers" container within the
"ADOSAKANA.LOCAL" domain.
Enter the user name: administrator
Enter the password:
Error: Machine account creation procedure failed
[ 61] Loaded the preliminary configuration.
[ 99] Successfully connected to ip 172.17.44.49, port 88 using
TCP
[ 168] Successfully connected to ip 172.17.44.49, port 389 using
TCP
[ 168] Entry for host-address: 172.17.44.49 not found in the
current source: FILES. Ignoring and trying next available
source
[ 172] Source: DNS unavailable. Entry for
host-address:172.17.44.49 not found in any of the
available sources
**[ 181] FAILURE: Unable to SASL bind to LDAP server using GSSAPI:
** Local error
[ 181] Additional info: SASL(-1): generic failure: GSSAPI Error:
Unspecified GSS failure. Minor code may provide more
information (Cannot determine realm for numeric host
address)
[ 181] Unable to connect to LDAP (Active Directory) service on
sambaad.ADOSAKANA.LOCAL (Error: Local error)
[ 181] Unable to make a connection (LDAP (Active
Directory):ADOSAKANA.LOCAL), result: 7643
Error: command failed: Failed to create the Active Directory machine account
"SVM91". Reason: LDAP Error: Local error occurred.
ontap91::>
ontap91::> vserver cifs create -cifs-server svm91 -domain ADOSAKANA.LOCAL
In order to create an Active Directory machine account for the CIFS server, you
must supply the name and password of a Windows account with sufficient
privileges to add computers to the "CN=Computers" container within the
"ADOSAKANA.LOCAL" domain.
Enter the user name: administrator
Enter the password:
Warning: An account by this name already exists in Active Directory at
CN=SVM91,CN=Computers,DC=adosakana,DC=local.
If there is an existing DNS entry for the name SVM91, it must be
removed. Data ONTAP cannot remove such an entry.
Use an external tool to remove it after this command completes.
Ok to reuse this account? {y|n}: y
Error: Machine account creation procedure failed
[ 13] Loaded the preliminary configuration.
[ 92] Created a machine account in the domain
[ 93] SID to name translations of Domain Users and Admins
completed successfully
[ 100] Modified account 'cn=SVM91,CN=Computers,dc=VM2,dc=ADOSAKANA
dc=LOCAL'
[ 101] Successfully connected to ip 172.17.44.49, port 88 using
TCP
[ 113] Successfully connected to ip 172.17.44.49, port 464 using
TCP
[ 242] Kerberos password set for 'SVM91$@ADOSAKANA.LOCAL' succeeded
[ 242] Set initial account password
[ 277] Successfully connected to ip 172.17.44.49, port 445 using
TCP
[ 312] Successfully connected to ip 172.17.44.49, port 88 using
TCP
[ 346] Successfully authenticated with DC
sambaad.ADOSAKANA.LOCAL
[ 366] Unable to connect to NetLogon service on
sambaad.ADOSAKANA.LOCAL (Error:
RESULT_ERROR_GENERAL_FAILURE)
**[ 366] FAILURE: Unable to make a connection
** (NetLogon:ADOSAKANA.LOCAL), result: 3
[ 366] Unable to make a NetLogon connection to
sambaad.ADOSAKANA.LOCAL using the new machine account
Error: command failed: Failed to create the Active Directory machine account
"SVM91". Reason: general failure.
ontap91::>
root@zstack137:~# ceph -v
ceph version 18.2.2 (e9fe820e7fffd1b7cde143a9f77653b73fcec748) reef (stable)
root@zstack137:~# pveversion
pve-manager/8.1.4/ec5affc9e41f1d79 (running kernel: 6.5.11-8-pve)
root@zstack137:~# pveceph pool ls
lqqqqqqqqqqqqqqqqqwqqqqqqwqqqqqqqqqqwqqqqqqqqwqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqk
x Name x Size x Min Size x PG Num x min. PG Num x Optimal PG Num x PG Autoscale Mode x PG Autoscale Target Size x PG Autoscale Target Ratio x Crush Rule Name x %-Used x Used x
tqqqqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqqqnqqqqqqqqnqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqu
x .mgr x 3 x 2 x 1 x 1 x 1 x on x x x replicated_rule x 3.08950029648258e-06 x 1388544 x
tqqqqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqqqnqqqqqqqqnqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqu
x cephfs_data x 3 x 2 x 32 x x 32 x on x x x replicated_rule x 0 x 0 x
tqqqqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqqqnqqqqqqqqnqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqu
x cephfs_metadata x 3 x 2 x 32 x 16 x 16 x on x x x replicated_rule x 4.41906962578287e-07 x 198610 x
tqqqqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqqqnqqqqqqqqnqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqu
x storagepool x 3 x 2 x 128 x x 32 x warn x x x replicated_rule x 0.0184257291257381 x 8436679796 x
mqqqqqqqqqqqqqqqqqvqqqqqqvqqqqqqqqqqvqqqqqqqqvqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqj
root@zstack137:~#
「ceph osd pool autoscale-status」
root@zstack137:~# ceph osd pool autoscale-status
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE BULK
.mgr 452.0k 3.0 449.9G 0.0000 1.0 1 on False
cephfs_data 0 3.0 449.9G 0.0000 1.0 32 on False
cephfs_metadata 66203 3.0 449.9G 0.0000 4.0 32 on False
storagepool 2681M 3.0 449.9G 0.0175 1.0 128 warn False
root@zstack137:~#
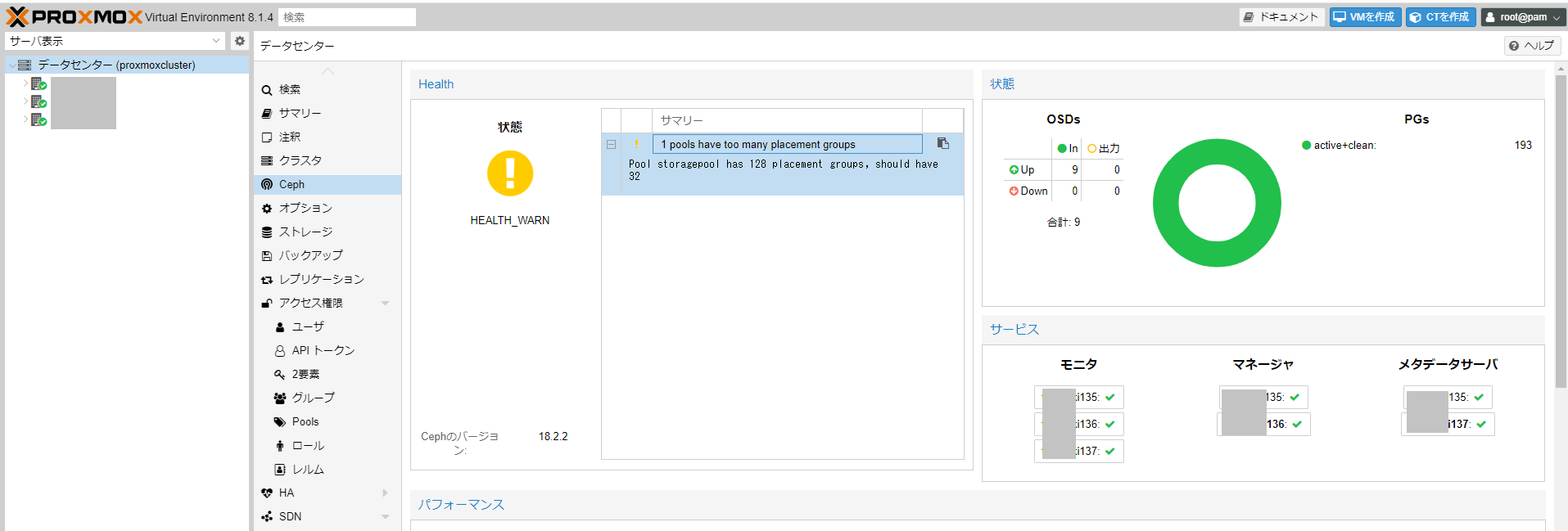
root@zstack137:~# ceph health
HEALTH_WARN 1 pools have too many placement groups
root@zstack137:~# ceph health detail
HEALTH_WARN 1 pools have too many placement groups
[WRN] POOL_TOO_MANY_PGS: 1 pools have too many placement groups
Pool storagepool has 128 placement groups, should have 32
root@zstack137:~#
root@zstack137:~# ceph -s
cluster:
id: 9e085d6a-77f3-41f1-8f6d-71fadc9c011b
health: HEALTH_WARN
1 pools have too many placement groups
services:
mon: 3 daemons, quorum zstack136,zstack135,zstack137 (age 3h)
mgr: zstack136(active, since 3h), standbys: zstack135
mds: 1/1 daemons up, 1 standby
osd: 9 osds: 9 up (since 3h), 9 in (since 3d)
data:
volumes: 1/1 healthy
pools: 4 pools, 193 pgs
objects: 716 objects, 2.7 GiB
usage: 8.3 GiB used, 442 GiB / 450 GiB avail
pgs: 193 active+clean
root@zstack137:~#
ceph pg dump | awk '
BEGIN { IGNORECASE = 1 }
/^PG_STAT/ { col=1; while($col!="UP") {col++}; col++ }
/^[0-9a-f]+\.[0-9a-f]+/ { match($0,/^[0-9a-f]+/); pool=substr($0, RSTART, RLENGTH); poollist[pool]=0;
up=$col; i=0; RSTART=0; RLENGTH=0; delete osds; while(match(up,/[0-9]+/)>0) { osds[++i]=substr(up,RSTART,RLENGTH); up = substr(up, RSTART+RLENGTH) }
for(i in osds) {array[osds[i],pool]++; osdlist[osds[i]];}
}
END {
printf("\n");
printf("pool :\t"); for (i in poollist) printf("%s\t",i); printf("| SUM \n");
for (i in poollist) printf("--------"); printf("----------------\n");
for (i in osdlist) { printf("osd.%i\t", i); sum=0;
for (j in poollist) { printf("%i\t", array[i,j]); sum+=array[i,j]; sumpool[j]+=array[i,j] }; printf("| %i\n",sum) }
for (i in poollist) printf("--------"); printf("----------------\n");
printf("SUM :\t"); for (i in poollist) printf("%s\t",sumpool[i]); printf("|\n");
}'
無事実行できた。
root@zstack137:~# ceph pg dump | awk '
BEGIN { IGNORECASE = 1 }
/^PG_STAT/ { col=1; while($col!="UP") {col++}; col++ }
/^[0-9a-f]+\.[0-9a-f]+/ { match($0,/^[0-9a-f]+/); pool=substr($0, RSTART, RLENGTH); poollist[pool]=0;
up=$col; i=0; RSTART=0; RLENGTH=0; delete osds; while(match(up,/[0-9]+/)>0) { osds[++i]=substr(up,RSTART,RLENGTH); up = substr(up, RSTART+RLENGTH) }
for(i in osds) {array[osds[i],pool]++; osdlist[osds[i]];}
}
END {
printf("\n");
printf("pool :\t"); for (i in poollist) printf("%s\t",i); printf("| SUM \n");
for (i in poollist) printf("--------"); printf("----------------\n");
for (i in osdlist) { printf("osd.%i\t", i); sum=0;
for (j in poollist) { printf("%i\t", array[i,j]); sum+=array[i,j]; sumpool[j]+=array[i,j] }; printf("| %i\n",sum) }
for (i in poollist) printf("--------"); printf("----------------\n");
printf("SUM :\t"); for (i in poollist) printf("%s\t",sumpool[i]); printf("|\n");
}'
dumped all
pool : 3 2 1 4 | SUM
------------------------------------------------
osd.3 4 5 1 13 | 23
osd.8 4 6 0 12 | 22
osd.6 2 4 0 15 | 21
osd.5 6 4 0 16 | 26
osd.2 3 3 0 15 | 21
osd.1 4 3 0 10 | 17
osd.4 1 1 0 16 | 18
osd.0 5 2 0 10 | 17
osd.7 3 4 0 21 | 28
------------------------------------------------
SUM : 32 32 1 128 |
root@zstack137:~#
poolによって差がありすぎている?
中国語のページで「ceph使用问题积累」というところがあって「HEALTH_WARN:pools have too many placement groups」と「HEALTH_WARN: mons are allowing insecure global_id reclaim」についての対処方法が載っている。
後者については「ceph config set mon auth_allow_insecure_global_id_reclaim false」となっていた。
module設定変える前に「ceph mgr module ls」で状態確認
root@zstack137:~# ceph mgr module ls
MODULE
balancer on (always on)
crash on (always on)
devicehealth on (always on)
orchestrator on (always on)
pg_autoscaler on (always on)
progress on (always on)
rbd_support on (always on)
status on (always on)
telemetry on (always on)
volumes on (always on)
iostat on
nfs on
restful on
alerts -
influx -
insights -
localpool -
mirroring -
osd_perf_query -
osd_support -
prometheus -
selftest -
snap_schedule -
stats -
telegraf -
test_orchestrator -
zabbix -
root@zstack137:~#
SUSEのページにあるSUSE Enterprise Storage 7 DocumentationのAdministration and Operations Guide「12 Determine the cluster state」を見るといろいろな状態確認コマンドがあった。
root@zstack137:~# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 450 GiB 442 GiB 8.3 GiB 8.3 GiB 1.85
TOTAL 450 GiB 442 GiB 8.3 GiB 8.3 GiB 1.85
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
.mgr 1 1 449 KiB 2 1.3 MiB 0 140 GiB
cephfs_data 2 32 0 B 0 0 B 0 140 GiB
cephfs_metadata 3 32 35 KiB 22 194 KiB 0 140 GiB
storagepool 4 128 2.6 GiB 692 7.9 GiB 1.84 140 GiB
root@zstack137:~# ceph df detail
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 450 GiB 442 GiB 8.3 GiB 8.3 GiB 1.85
TOTAL 450 GiB 442 GiB 8.3 GiB 8.3 GiB 1.85
--- POOLS ---
POOL ID PGS STORED (DATA) (OMAP) OBJECTS USED (DATA) (OMAP) %USED MAX AVAIL QUOTA OBJECTS QUOTA BYTES DIRTY USED COMPR UNDER COMPR
.mgr 1 1 449 KiB 449 KiB 0 B 2 1.3 MiB 1.3 MiB 0 B 0 140 GiB N/A N/A N/A 0 B 0 B
cephfs_data 2 32 0 B 0 B 0 B 0 0 B 0 B 0 B 0 140 GiB N/A N/A N/A 0 B 0 B
cephfs_metadata 3 32 35 KiB 18 KiB 17 KiB 22 194 KiB 144 KiB 50 KiB 0 140 GiB N/A N/A N/A 0 B 0 B
storagepool 4 128 2.6 GiB 2.6 GiB 3.0 KiB 692 7.9 GiB 7.9 GiB 9.1 KiB 1.84 140 GiB N/A N/A N/A 0 B 0 B
root@zstack137:~#
TOO_MANY_PGSの時の対処としていかが書かれている
TOO_MANY_PGS The number of PGs in use is above the configurable threshold of mon_pg_warn_max_per_osd PGs per OSD. This can lead to higher memory usage for OSD daemons, slower peering after cluster state changes (for example OSD restarts, additions, or removals), and higher load on the Ceph Managers and Ceph Monitors.
While the pg_num value for existing pools cannot be reduced, the pgp_num value can. This effectively co-locates some PGs on the same sets of OSDs, mitigating some of the negative impacts described above. The pgp_num value can be adjusted with:
じゃあ、「ceph osd pool set storagepool pgp_num 32」を実行してpgp_numを128から32に変更してみる
root@zstack137:~# ceph osd pool stats
pool .mgr id 1
nothing is going on
pool cephfs_data id 2
nothing is going on
pool cephfs_metadata id 3
nothing is going on
pool storagepool id 4
nothing is going on
root@zstack137:~# ceph osd pool get storagepool pgp_num
pgp_num: 128
root@zstack137:~# ceph osd pool set storagepool pgp_num 32
set pool 4 pgp_num to 32
root@zstack137:~# ceph osd pool get storagepool pgp_num
pgp_num: 125
root@zstack137:~# ceph osd pool get storagepool pgp_num
pgp_num: 119
root@zstack137:~#
徐々に変更されていく模様
root@zstack137:~# ceph -s
cluster:
id: 9e085d6a-77f3-41f1-8f6d-71fadc9c011b
health: HEALTH_WARN
Reduced data availability: 1 pg peering
1 pools have too many placement groups
1 pools have pg_num > pgp_num
services:
mon: 3 daemons, quorum zstack136,zstack135,zstack137 (age 5h)
mgr: zstack136(active, since 5h), standbys: zstack135
mds: 1/1 daemons up, 1 standby
osd: 9 osds: 9 up (since 5h), 9 in (since 3d); 2 remapped pgs
data:
volumes: 1/1 healthy
pools: 4 pools, 193 pgs
objects: 716 objects, 2.7 GiB
usage: 8.4 GiB used, 442 GiB / 450 GiB avail
pgs: 0.518% pgs not active
16/2148 objects misplaced (0.745%)
190 active+clean
2 active+recovering
1 remapped+peering
io:
recovery: 2.0 MiB/s, 0 objects/s
root@zstack137:~# ceph health
HEALTH_WARN Reduced data availability: 1 pg peering; 1 pools have too many placement groups; 1 pools have pg_num > pgp_num
root@zstack137:~# ceph health detail
HEALTH_WARN 1 pools have too many placement groups; 1 pools have pg_num > pgp_num
[WRN] POOL_TOO_MANY_PGS: 1 pools have too many placement groups
Pool storagepool has 128 placement groups, should have 32
[WRN] SMALLER_PGP_NUM: 1 pools have pg_num > pgp_num
pool storagepool pg_num 128 > pgp_num 32
root@zstack137:~#
ある程度時間が経過したあと
root@zstack137:~# ceph health detail
HEALTH_WARN 1 pools have too many placement groups; 1 pools have pg_num > pgp_num
[WRN] POOL_TOO_MANY_PGS: 1 pools have too many placement groups
Pool storagepool has 128 placement groups, should have 32
[WRN] SMALLER_PGP_NUM: 1 pools have pg_num > pgp_num
pool storagepool pg_num 128 > pgp_num 32
root@zstack137:~# ceph pg dump | awk '
BEGIN { IGNORECASE = 1 }
/^PG_STAT/ { col=1; while($col!="UP") {col++}; col++ }
/^[0-9a-f]+\.[0-9a-f]+/ { match($0,/^[0-9a-f]+/); pool=substr($0, RSTART, RLENGTH); poollist[pool]=0;
up=$col; i=0; RSTART=0; RLENGTH=0; delete osds; while(match(up,/[0-9]+/)>0) { osds[++i]=substr(up,RSTART,RLENGTH); up = substr(up, RSTART+RLENGTH) }
for(i in osds) {array[osds[i],pool]++; osdlist[osds[i]];}
}
END {
printf("\n");
printf("pool :\t"); for (i in poollist) printf("%s\t",i); printf("| SUM \n");
for (i in poollist) printf("--------"); printf("----------------\n");
for (i in osdlist) { printf("osd.%i\t", i); sum=0;
for (j in poollist) { printf("%i\t", array[i,j]); sum+=array[i,j]; sumpool[j]+=array[i,j] }; printf("| %i\n",sum) }
for (i in poollist) printf("--------"); printf("----------------\n");
printf("SUM :\t"); for (i in poollist) printf("%s\t",sumpool[i]); printf("|\n");
}'
dumped all
pool : 3 2 1 4 | SUM
------------------------------------------------
osd.3 4 5 1 15 | 25
osd.8 4 6 0 16 | 26
osd.6 2 4 0 16 | 22
osd.5 6 4 0 4 | 14
osd.2 3 3 0 11 | 17
osd.1 4 3 0 13 | 20
osd.4 1 1 0 17 | 19
osd.0 5 2 0 20 | 27
osd.7 3 4 0 16 | 23
------------------------------------------------
SUM : 32 32 1 128 |
root@zstack137:~# ceph osd pool autoscale-status
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE BULK
.mgr 452.0k 3.0 449.9G 0.0000 1.0 1 on False
cephfs_data 0 3.0 449.9G 0.0000 1.0 32 on False
cephfs_metadata 66203 3.0 449.9G 0.0000 4.0 32 on False
storagepool 2681M 3.0 449.9G 0.0175 1.0 128 warn False
root@zstack137:~# pveceph pool ls
lqqqqqqqqqqqqqqqqqwqqqqqqwqqqqqqqqqqwqqqqqqqqwqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqk
x Name x Size x Min Size x PG Num x min. PG Num x Optimal PG Num x PG Autoscale Mode x PG Autoscale Target Size x PG Autoscale Target Ratio x Crush Rule Name x %-Used x Used x
tqqqqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqqqnqqqqqqqqnqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqu
x .mgr x 3 x 2 x 1 x 1 x 1 x on x x x replicated_rule x 3.09735719383752e-06 x 1388544 x
tqqqqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqqqnqqqqqqqqnqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqu
x cephfs_data x 3 x 2 x 32 x x 32 x on x x x replicated_rule x 0 x 0 x
tqqqqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqqqnqqqqqqqqnqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqu
x cephfs_metadata x 3 x 2 x 32 x 16 x 16 x on x x x replicated_rule x 4.43030785390874e-07 x 198610 x
tqqqqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqqqnqqqqqqqqnqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqu
x storagepool x 3 x 2 x 128 x x 32 x warn x x x replicated_rule x 0.018471721559763 x 8436679796 x
mqqqqqqqqqqqqqqqqqvqqqqqqvqqqqqqqqqqvqqqqqqqqvqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqj
root@zstack137:~#
pg_numを減らせる?
root@zstack137:~# ceph osd pool get storagepool pg_num
pg_num: 128
root@zstack137:~# ceph osd pool set storagepool pg_num 32
set pool 4 pg_num to 32
root@zstack137:~# ceph osd pool get storagepool pg_num
pg_num: 128
root@zstack137:~# ceph osd pool get storagepool pg_num
pg_num: 124
root@zstack137:~#
徐々に減ってる
ステータスはHEALTH_OLに変わった
root@zstack137:~# ceph osd pool get storagepool pg_num
pg_num: 119
root@zstack137:~# ceph health detail
HEALTH_OK
root@zstack137:~# pveceph pool ls
lqqqqqqqqqqqqqqqqqwqqqqqqwqqqqqqqqqqwqqqqqqqqwqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqk
x Name x Size x Min Size x PG Num x min. PG Num x Optimal PG Num x PG Autoscale Mode x PG Autoscale Target Size x PG Autoscale Target Ratio x Crush Rule Name x %-Used x Used x
tqqqqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqqqnqqqqqqqqnqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqu
x .mgr x 3 x 2 x 1 x 1 x 1 x on x x x replicated_rule x 3.10063592223742e-06 x 1388544 x
tqqqqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqqqnqqqqqqqqnqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqu
x cephfs_data x 3 x 2 x 32 x x 32 x on x x x replicated_rule x 0 x 0 x
tqqqqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqqqnqqqqqqqqnqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqu
x cephfs_metadata x 3 x 2 x 32 x 16 x 16 x on x x x replicated_rule x 4.43499772018185e-07 x 198610 x
tqqqqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqqqnqqqqqqqqnqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqu
x storagepool x 3 x 2 x 117 x x 32 x warn x x x replicated_rule x 0.0184909123927355 x 8436679796 x
mqqqqqqqqqqqqqqqqqvqqqqqqvqqqqqqqqqqvqqqqqqqqvqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqj
root@zstack137:~#
「ceph osd pool autoscale-status」の方のPG_NUMは即反映
root@zstack137:~# ceph osd pool autoscale-status
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE BULK
.mgr 452.0k 3.0 449.9G 0.0000 1.0 1 on False
cephfs_data 0 3.0 449.9G 0.0000 1.0 32 on False
cephfs_metadata 66203 3.0 449.9G 0.0000 4.0 32 on False
storagepool 2705M 3.0 449.9G 0.0176 1.0 32 warn False
root@zstack137:~#
root@zstack137:~# ceph health detail
HEALTH_WARN Reduced data availability: 2 pgs inactive, 2 pgs peering
[WRN] PG_AVAILABILITY: Reduced data availability: 2 pgs inactive, 2 pgs peering
pg 4.22 is stuck peering for 2d, current state peering, last acting [6,5,2]
pg 4.62 is stuck peering for 6h, current state peering, last acting [6,5,2]
root@zstack137:~#
しばらく時間がたって変更が終わったあとに状態をとってみた
root@zstack137:~# ceph health detail
HEALTH_OK
root@zstack137:~# pveceph pool ls
lqqqqqqqqqqqqqqqqqwqqqqqqwqqqqqqqqqqwqqqqqqqqwqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqqqqqqqqqqqwqqqqqqqqqqqqk
x Name x Size x Min Size x PG Num x min. PG Num x Optimal PG Num x PG Autoscale Mode x PG Autoscale Target Size x PG Autoscale Target Ratio x Crush Rule Name x %-Used x Used x
tqqqqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqqqnqqqqqqqqnqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqu
x .mgr x 3 x 2 x 1 x 1 x 1 x on x x x replicated_rule x 3.13595910483855e-06 x 1388544 x
tqqqqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqqqnqqqqqqqqnqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqu
x cephfs_data x 3 x 2 x 32 x x 32 x on x x x replicated_rule x 0 x 0 x
tqqqqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqqqnqqqqqqqqnqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqu
x cephfs_metadata x 3 x 2 x 32 x 16 x 16 x on x x x replicated_rule x 4.4855224246021e-07 x 198610 x
tqqqqqqqqqqqqqqqqqnqqqqqqnqqqqqqqqqqnqqqqqqqqnqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqqqqqqqqqqqnqqqqqqqqqqqqu
x storagepool x 3 x 2 x 32 x x 32 x warn x x x replicated_rule x 0.0186976287513971 x 8436679796 x
mqqqqqqqqqqqqqqqqqvqqqqqqvqqqqqqqqqqvqqqqqqqqvqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqj
root@zstack137:~# ceph -s
cluster:
id: 9e085d6a-77f3-41f1-8f6d-71fadc9c011b
health: HEALTH_OK
services:
mon: 3 daemons, quorum zstack136,zstack135,zstack137 (age 6h)
mgr: zstack136(active, since 6h), standbys: zstack135
mds: 1/1 daemons up, 1 standby
osd: 9 osds: 9 up (since 6h), 9 in (since 3d)
data:
volumes: 1/1 healthy
pools: 4 pools, 97 pgs
objects: 716 objects, 2.7 GiB
usage: 8.6 GiB used, 441 GiB / 450 GiB avail
pgs: 97 active+clean
root@zstack137:~# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 450 GiB 441 GiB 8.7 GiB 8.7 GiB 1.94
TOTAL 450 GiB 441 GiB 8.7 GiB 8.7 GiB 1.94
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
.mgr 1 1 449 KiB 2 1.3 MiB 0 137 GiB
cephfs_data 2 32 0 B 0 0 B 0 137 GiB
cephfs_metadata 3 32 35 KiB 22 194 KiB 0 137 GiB
storagepool 4 32 2.7 GiB 692 8.0 GiB 1.89 137 GiB
root@zstack137:~#
「netsh advfirewall show allprofiles」でプロファイル確認
「netsh advfirewall show currentprofile」で現在有効になってるプロファイル確認
「netsh advfirewall firewall show rule name=all」で設定出力
「vssadmin list shadows」で現在存在しているシャドウコピーを確認
「vssadmin list shadowstorage」でシャドウコピーの保存先を確認
「vssadmin list volumes」でディスクのIDを確認
「schtasks /query /xml」で一覧をXML形式で出力し、名前が"ShadowCopyVolume~"のものの内容を確認
@echo off
set TIME2=%TIME: =0%
set LOGDATE=%DATE:~0,4%%DATE:~5,2%%DATE:~8,2%-%TIME2:~0,2%%TIME2:~3,2%
robocopy \\旧FS\share \\新FS\share /mir /copyall /R:0 /W:0 /LOG+:D:\LOGS\share-%LOGDATE%.txt
Manual checks that can be done using Upgrade ONTAP documentation
メッセージ
Manual validation checks need to be performed. Refer to the Upgrade Advisor Plan or the "What should I verify before I upgrade with or without Upgrade Advisor" section in the "Upgrade ONTAP" documentation for the remaining validation checks that need to be performed before update. Failing to do so can result in an update failure or an I/O disruption.
解決策
Refer to the Upgrade Advisor Plan or the "What should I verify before I upgrade with or without Upgrade Advisor" section in the "Upgrade ONTAP" documentation for the remaining validation checks that need to be performed before update.
ONTAP API to REST transition warning
ONTAP 9.12.1以降だと
ONTAP API to REST transition warning
メッセージ
NetApp ONTAP API has been used on this cluster for ONTAP data storage management within the last 30 days. NetApp ONTAP API is approaching end of availability.
解決策
Transition your automation tools from ONTAP API to ONTAP REST API. CPC-00410 - End of availability: ONTAPI : https://mysupport.netapp.com/info/communications/ECMLP2880232.html
LIFs on home node status
LIF(ネットワークインタフェース)がホーム以外のポートで運用されている場合に表示されます。
home portに戻すことで警告は消えます。home portに戻すことができない場合はONTAP OSのアップデートできません。
One or more LIFs are not on the node, verify that all LIFs are on the home node before attempting NDU.
Ensure that the NX-OS (cluster network switches), IOS (management network switches), and reference configuration file (RCF) software ersions are compatible with the target Data ONTAP release.
Refer to http://mysupport.netapp.com/NOW/download/software/cm_switches/ and http://mysupport.netapp.com/NOW/download/software/cm_switches_ntap/ for more details.
Name Service Configuration DNS Check
メッセージ
None of the configured DNS servers are reacjanle for the following Vservers: 名前. There might be other Vservers for DNS servers are not reachable.
解決策
Delete the DNS server, or verify that the DNS status is "up". Delete the DNS configuration for the Vservers which do not have "dns" as a configured source in the ns-switch database.
NFS mounts
メッセージ
This cluster is serving NFS clients. If NFS soft mounts are used, there is a possibility of frequent NFS timeouts and race conditions that can lead to data corruption during the upgrade
解決策
Use NFS hard mounts, if possible
CIFS status
メッセージ
CIFS is currently in use. Any unprotected sessions may be affected with possible loss of data.
解決作
Stop all unprotected CIFS workloads before performing the update. To list the unprotected CIFS workloads, run the command: vserver cifs session show -continuously-available No, Partial
ontap9121::> cluster image show-update-progress
Estimated Elapsed
Update Phase Status Duration Duration
-------------------- ----------------- --------------- ---------------
Pre-update checks completed 00:10:00 00:00:38
Details:
Pre-update Check Status Error-Action
-------------------- ----------------- --------------------------------------
AMPQ Router and OK N/A
Broker Config
Cleanup
Aggregate online OK N/A
status and parity
check
Application OK N/A
Provisioning Cleanup
Autoboot Bootargs OK N/A
Status
Backend OK N/A
Configuration Status
Boot Menu Status OK N/A
CIFS compatibility OK N/A
status check
Capacity licenses OK N/A
install status check
Check For SP/BMC OK N/A
Connectivity To
Nodes
Check LDAP fastbind OK N/A
users using
unsecure connection.
Cloud keymanager OK N/A
connectivity check
Cluster health and OK N/A
eligibility status
Cluster/management OK N/A
switch check
Compatible New OK N/A
Image Check
Current system OK N/A
version check if it
is susceptible to
possible outage
during NDU
Data ONTAP Version OK N/A
and Previous
Upgrade Status
Data aggregates HA OK N/A
policy check
Disk status check OK N/A
for failed, broken
or non-compatibility
Duplicate Initiator OK N/A
Check
Encryption key OK N/A
migration status
check
External OK N/A
key-manager with
legacy KMIP client
check
External keymanager OK N/A
key server status
check
Infinite Volume OK N/A
availibility check
Logically over OK N/A
allocated DP
volumes check
Manual checks that Warning Warning: Manual validation checks
can be done using need to be performed. Refer to the
Upgrade ONTAP Upgrade Advisor Plan or the "What
documentation should I verify before I upgrade with
or without Upgrade Advisor" section
in the "Upgrade ONTAP" documentation
for the remaining validation checks
that need to be performed before
update. Failing to do so can result
in an update failure or an I/O
disruption.
Action: Refer to the Upgrade Advisor
Plan or the "What should I verify
before I upgrade with or without
Upgrade Advisor" section in the
"Upgrade ONTAP" documentation for the
remaining validation checks that need
to be performed before update.
MetroCluster OK N/A
configuration
status check for
compatibility
Minimum number of OK N/A
aggregate disks
check
NAE Aggregate and OK N/A
NVE Volume
Encryption Check
NDMP sessions check OK N/A
NFS mounts status OK N/A
check
NVMe over Fabrics OK N/A
license check
Name Service OK N/A
Configuration DNS
Check
Name Service OK N/A
Configuration LDAP
Check
Node to SP/BMC OK N/A
connectivity check
OKM/KMIP enabled OK N/A
systems - Missing
keys check
ONTAP API to REST Warning Warning: NetApp ONTAP API has been
transition warning used on this cluster for ONTAP data
storage management within the last 30
days. NetApp ONTAP API is approaching
end of availability.
Action: Transition your automation
tools from ONTAP API to ONTAP REST
API. For more details, refer to
CPC-00410 - End of availability:
ONTAPI
https://mysupport.netapp.com/info/
communications/ECMLP2880232.html
ONTAP Image OK N/A
Capability Status
OpenSSL 3.0.x OK N/A
upgrade validation
check
Openssh 7.2 upgrade OK N/A
validation check
Pre-Update OK N/A
Configuration
Verification
RDB Replica Health OK N/A
Check
Replicated database OK N/A
schema consistency
check
Running Jobs Status OK N/A
SAN and NVMe LIF OK N/A
Online Check
SAN compatibility OK N/A
for manual
configurability
check
SAN kernel agent OK N/A
status check
Secure Purge OK N/A
operation Check
Shelves and Sensors OK N/A
check
SnapLock Version OK N/A
Check
SnapMirror OK N/A
Synchronous
relationship status
check
SnapMirror OK N/A
compatibility
status check
Supported platform OK N/A
check
Target ONTAP OK N/A
release support for
FiberBridge 6500N
check
Upgrade Version OK N/A
Compatibility Status
Verify all bgp OK N/A
peer-groups are in
the up state
Verify that e0M is OK N/A
home to no LIFs
with high speed
services.
Volume Conversion OK N/A
In Progress Check
Volume move OK N/A
progress status
check
Volume online OK N/A
status check
iSCSI target portal OK N/A
groups status check
Overall Status Warning Warning
61 entries were displayed.
ontap9121::>